ELK日志我们一般都是按天存储,例如索引名为"kafkalog-2022-04-05",因为日志量所占的存储是非常大的,我们不能一直保存,而是要定期清理旧的,这里就以保留7天日志为例。
自动清理7天以前的日志可以用定时任务的方式,这样就需要加入多一个定时任务,可能不同服务记录的索引名又不一样,这样用定时任务配还是没那么方便。
ES给我们提供了一个索引的生命周期策略(lifecycle),就可以对索引指定删除时间,能很好解决这个问题。
索引生命周期分为四个阶段:HOT(热)=>WARM(温)=》COLD(冷)=>DELETE(删除)
这里为ELK日志超过7天的自动删除,所以只需要用到DELETE(删除阶段)
PUT _ilm/policy/auto_delete_policy
{
"policy": {
"phases": {
"delete": {
"min_age": "7d",
"actions": {
"delete": {}
}
}
}
}
}
创建一个自动删除策略(auto_delete_policy)
delete:删除阶段,7天执行删除索引动作
查看策略:GET _ilm/policy/
索引模板可以匹配索引名称,匹配到的索引名称按这个模板创建mapping
PUT _template/elk_template
{
"index_patterns": ["kafka*"],
"settings": {
"index":{
"lifecycle":{
"name":"auto_delete_policy",
"indexing_complete":true
}
}
}
}
创建索引模板(elk_tempalte),index.lifecycle.name把上面的自动删除策略绑定到elk索引模板
创建kafka开头的索引时就会应用这个模板。
indexing_complete:true,必须设为true,跳过HOT阶段的Rollover
查看模板:GET /_template/
logstash配置:
logstash接收kafka的输入,输出到es。
input {
kafka {
type=>"log1"
topics => "kafkalog" #在kafka这个topics提取数据
bootstrap_servers => "127.0.0.1:9092" # kafka的地址
codec => "json" # 在提取kafka主机的日志时,需要写成json格式
}
}
output {
if [type] =="log1"
{
elasticsearch {
hosts => ["127.0.0.1:9200"] #es地址
index => "kafkalog%{+yyyy.MM.dd}" #把日志采集到es的索引名称
# user => "elastic"
# password => "123456"
}
}
}
这里测试时把DELETE的日期由7天"7d"改为1分钟"1m"。
生命周期策略默认10分钟检测一次,为了方便测试,这里设为30s。
PUT /_cluster/settings
{
"transient": {
"indices.lifecycle.poll_interval":"30s"
}
}
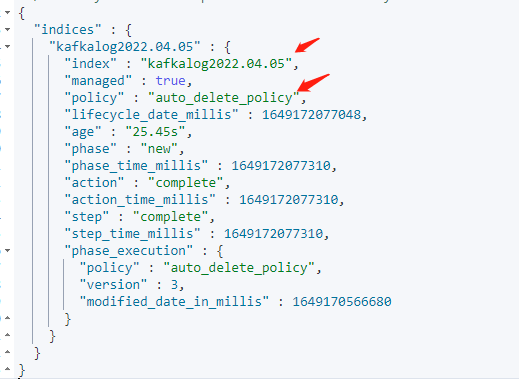
把日志写入到es后,查看日志索引的生命周期策略信息。
GET kafka*/_ilm/explain 查看kafka开头索引的生命周期策略
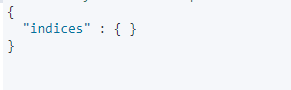
过一会再点查询,索引已经没有了,说明已经生效。
我发现自己需要这个。假设cart是一个包含用户列表的模型。defindex_of_itemcart.users.each_with_indexdo|u,i|ifu==current_userreturniendend获取此类关联索引的更简单方法是什么? 最佳答案 indexArray上的方法与您的index_of_item方法相同,例如cart.users.index(current_user)返回数组中第一个对象的索引==给obj。如果未找到匹配项,则返回nil。 关于ruby-on-
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
假设我有一个可枚举对象enum,现在我想获取第三个项目。我知道一种通用方法是转换成数组,然后使用索引访问,如:enum.to_a[2]但这种方式会创建一个临时数组,效率可能很低。现在我使用:enum.each_with_index{|v,i|breakvifi==2}但这非常丑陋和多余。执行此操作最有效的方法是什么? 最佳答案 你可以使用take剥离前三个元素,然后剥离last从take给你的数组中获取第三个元素:third=enum.take(3).last如果您根本不想生成任何数组,那么也许:#Ifenumisn'tanEnum
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
在运行Cucumber测试时,我得到(除了测试结果)大量调试/日志相关的输出形式:D,[2013-03-06T12:21:38.911829#49031]DEBUG--:SOAPrequest:D,[2013-03-06T12:21:38.911919#49031]DEBUG--:Pragma:no-cache,SOAPAction:"",Content-Type:text/xml;charset=UTF-8,Content-Length:1592W,[2013-03-06T12:21:38.912360#49031]WARN--:HTTPIexecutesHTTPPOSTusingt
我最近将我的http客户端切换到faraday,一切都按预期工作。我有以下代码来创建连接:@connection=Faraday.new(:url=>base_url)do|faraday|faraday.useCustim::Middlewarefaraday.request:url_encoded#form-encodePOSTparamsfaraday.request:jsonfaraday.response:json,:content_type=>/\bjson$/faraday.response:loggerfaraday.adapterFaraday.default_ada
在我的场景中,Logstash收到的系统日志行的“时间戳”是UTC,我们在Elasticsearch输出中使用事件“时间戳”:output{elasticsearch{embedded=>falsehost=>localhostport=>9200protocol=>httpcluster=>'elasticsearch'index=>"syslog-%{+YYYY.MM.dd}"}}我的问题是,在UTC午夜,Logstash在外时区(GMT-4=>America/Montreal)结束前将日志发送到不同的索引,并且索引在20小时(晚上8点)之后没有日志,因为“时间戳”是UTC。我们已
我想从特定索引开始遍历数组。我该怎么做?myj.eachdo|temp|...end 最佳答案 执行以下操作:your_array[your_index..-1].eachdo|temp|###end 关于ruby-从特定索引开始迭代数组,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/44151758/
我一直在努力学习如何处理由数组组成的数组。假设我有这个数组:my_array=[['ORANGE',1],['APPLE',2],['PEACH',3]我将如何找到包含'apple'的my_array索引并删除该索引(删除子数组['APPLE',2]因为'apple'包含在该索引的数组中)?谢谢-我非常感谢这里的帮助。 最佳答案 您可以使用Array.select过滤掉项目:>>a=[['ORANGE',1],['APPLE',2],['PEACH',3]]=>[["ORANGE",1],["APPLE",2],["PEACH",3