记录一下 PLG 收集运行日志的相关步骤和一些重点说明
目录
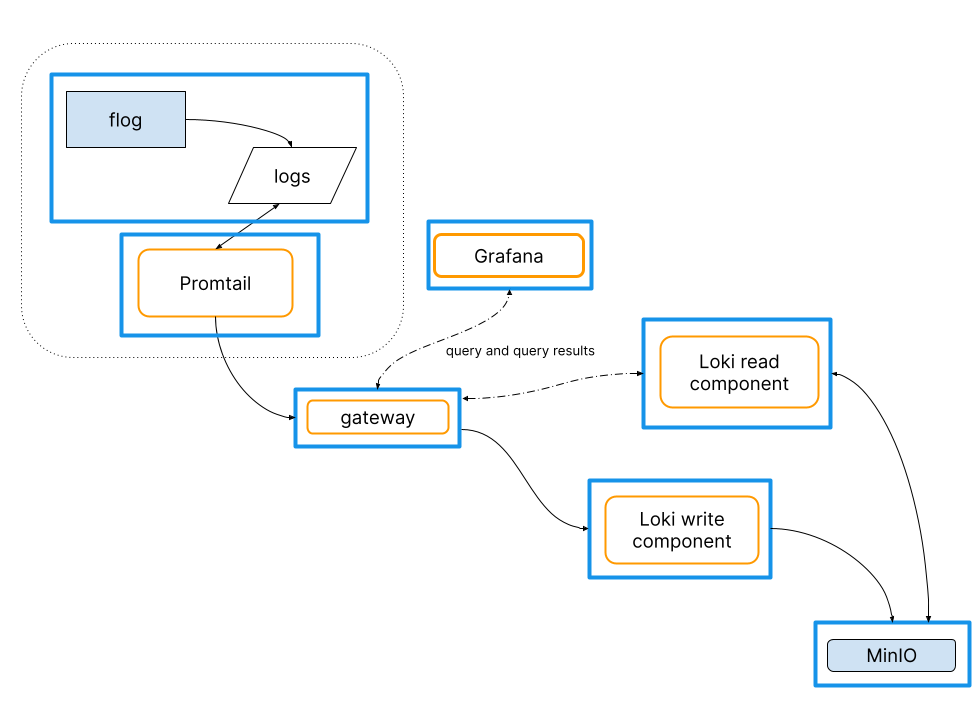
promtail : 读取、收集、传输日志信息
loki: 存储 promtail 传输过来的日志信息,当然loki也可以存储其他 的收集工具收集的日志,例如:Fluent logstash等
Grafana:日志展示层,读取loki接口日志信息展示在页面,提供动态查询
https://grafana.com/docs/loki/latest/installation/
程序下载:
https://github.com/grafana/loki/releases/
选择下载文件是 logcli-windows-amd64.exe.zip
配置下载:
wget https://raw.githubusercontent.com/grafana/loki/master/cmd/loki/loki-local-config.yaml
Show all 34 asserts 
选择下载文件是 promtail-windows-amd64.exe.zip
wget https://raw.githubusercontent.com/grafana/loki/main/clients/cmd/promtail/promtail-local-config.yaml
https://grafana.com/grafana/download?platform=windows
设置一下配置文件 loki-local-config.yaml,loki用来存储日志,这里可以设置最大保存时间。
参考: https://grafana.com/docs/loki/latest/configuration/examples/
auth_enabled: false
# 对外端口
server:
http_listen_port: 3100
# 存储设置
ingester:
lifecycler:
address: 127.0.0.1
ring:
kvstore:
store: inmemory
replication_factor: 1
final_sleep: 0s
chunk_idle_period: 5m
chunk_retain_period: 30s
schema_config:
configs:
- from: 2020-05-15
store: boltdb
object_store: filesystem
schema: v11
index:
prefix: index_
period: 168h
# 数据存放地址 包含索引
storage_config:
boltdb:
directory: /tmp/loki/index
filesystem:
directory: /tmp/loki/chunks
limits_config:
enforce_metric_name: false
reject_old_samples: true
reject_old_samples_max_age: 168h
table_manager:
retention_deletes_enabled: true
# 注意和索引存储时间一致,按1周为单位
retention_period: 168h
启动命令:
.\loki-windows-amd64.exe --config.file=loki-local-config.yaml
这里是收集日志,涉及多个日志行合并为一条日志信息传输给 loki,以及设置按照 logback里面的时间序列作为 loki的时间序列等配置。
这个不得说下,需要多看官方文档,里面配置比较细内容分散,需要结合其他人博客和官方文档进行分析测试。
模拟两个 微服务Springboot的日志收集(wms_main 和 wms_tools),
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
# 配置你的 loki 地址和端口
clients:
- url: http://localhost:3100/loki/api/v1/push
scrape_configs:
- job_name: wms_main
static_configs:
- targets:
- localhost
labels:
job: wms_main
app: wms
name: jtwms
__path__: E:\IDEA_HOME\guohe\wms-main-api\logs\*.log
pipeline_stages:
- match:
selector: '{job="wms_main"}'
stages:
- regex:
expression: '^(?s)(?P<timestamp>\S+?) (?P<level>\S+?) (?P<content>.*)$'
- multiline:
firstline: '^\d{4}-\d{2}-\d{2}T\d{1,2}:\d{2}:\d{2}\.\d{3}'
max_wait_time: 3s
- labels:
level:
content:
- timestamp:
format: RFC3339Nano
source: timestamp
- job_name: wms_tools
static_configs:
- targets:
- localhost
labels:
job: wms_tools
__path__: E:\IDEA_HOME\guohe\wms-tools-api\logs\*.log
pipeline_stages:
- match:
selector: '{job="wms_tools"}'
stages:
- regex:
expression: '^(?s)(?P<timestamp>\S+?) (?P<level>\S+?) (?P<content>.*)$'
- multiline:
firstline: '^\d{4}-\d{2}-\d{2}T\d{1,2}:\d{2}:\d{2}\.\d{3}'
max_wait_time: 3s
- labels:
level:
- timestamp:
format: RFC3339Nano
source: timestamp
上面的配置说明:
job_name 是 promtail收集任务或者是线程,一般一个job对应一个微服务日志收集工作
labels 配置项目中 __path__ 是微服务logback 日志的生产路径,建议docker方式的springboot 日志地址映射到主机路径即可。
labels 的其他配置是可以自定义的,比如你可以增加一个host 主机地址
pipeline_stages 是重点,里面配置主要用于修改调整收集到的日志,通过go的正则表达式进行解析 logback的一行日志信息,来配置生成最终要传递给loki的日志是什么样子的。
expression go语言正则表达式,对一行logback日志进行划分
这里说下logback xml的配置规则如下:
.... 省略
<encoder>
<Pattern>%d{yyyy-MM-dd'T'HH:mm:ss.SSSXXX} %-5level [%thread] %logger{36} L%line - %msg%n</Pattern>
<charset>UTF-8</charset>
</encoder>
... 省略
生成出来的logback日志信息如下:
...
2022-09-12T18:53:22.085+08:00 INFO [RMI TCP Connection(1)-192.168.50.1] o.s.web.servlet.DispatcherServlet L547 - Completed initialization in 19 ms
2022-09-12T18:54:55.641+08:00 DEBUG [http-nio-9903-exec-2] c.m.s.shirojwt.filter.JwtFilter L130 - JwtFilter isAccessAllowed url:/api/tools/test
2022-09-12T18:54:55.643+08:00 DEBUG [http-nio-9903-exec-2] c.s.w.m.f.s.ShiroJwtBussinessService L84 - 进入 认证 doGetAuthenticationInfo
...
可以看到表达式 前面两个是按照空格为分割符进行一行日志的拆解,主要目的是为了提取这一行日志的级别 level
multiline 配置项是为了传输到loki里面时,合并必要的日志行,例如java程序发生异常是的异常堆栈信息,这里就希望所有的堆栈信息合并一个日志条目存储到loki里面,在granfa页面上查看时比较方便
firstline 是合并日志行配置,表示什么样的开头表示是一条新日志,这里设置的是符合一行的日志信息以时间序列为开始的表示是一个新的日志条目。
timestamp 设置存储到loki里面的时间序列使用默认的还是从上面解析出来的值作为时间序列值, 为什么要这样做? 就是为了方便排序查看,不然默认的收集时间序列可能不会按照logbak的时间序列排序。
level 这里指 pipeline_stages 配置项下的,这里主要是将 logbak的日志等级加入到 标签中,为了方便查询。
启动命令:
.\promtail-windows-amd64.exe --config.file=promtail-local-config.yaml
可以修改配置文件 ./conf/defaults.ini 设置是否有访问前缀,或者是域名https方式访问这些。
[server]
protocol = http
...
http_port = 3000
...
domain = localhost
# 这里添加了一个访问前缀 /grafana 目的是为了后面配置 nginx 代理方便区分。
root_url = %(protocol)s://%(domain)s:%(http_port)s/grafana/
# 这里一定配置 true 表示 root_url 可以配置为子级路径访问
serve_from_sub_path = true
....
启动命令: 或者双击运行
.\bin\grafana-server.exe
初始登录账户:admin/admin
启动成功之后,http://localhost:3000/grafana/ 即可
添加数据源:
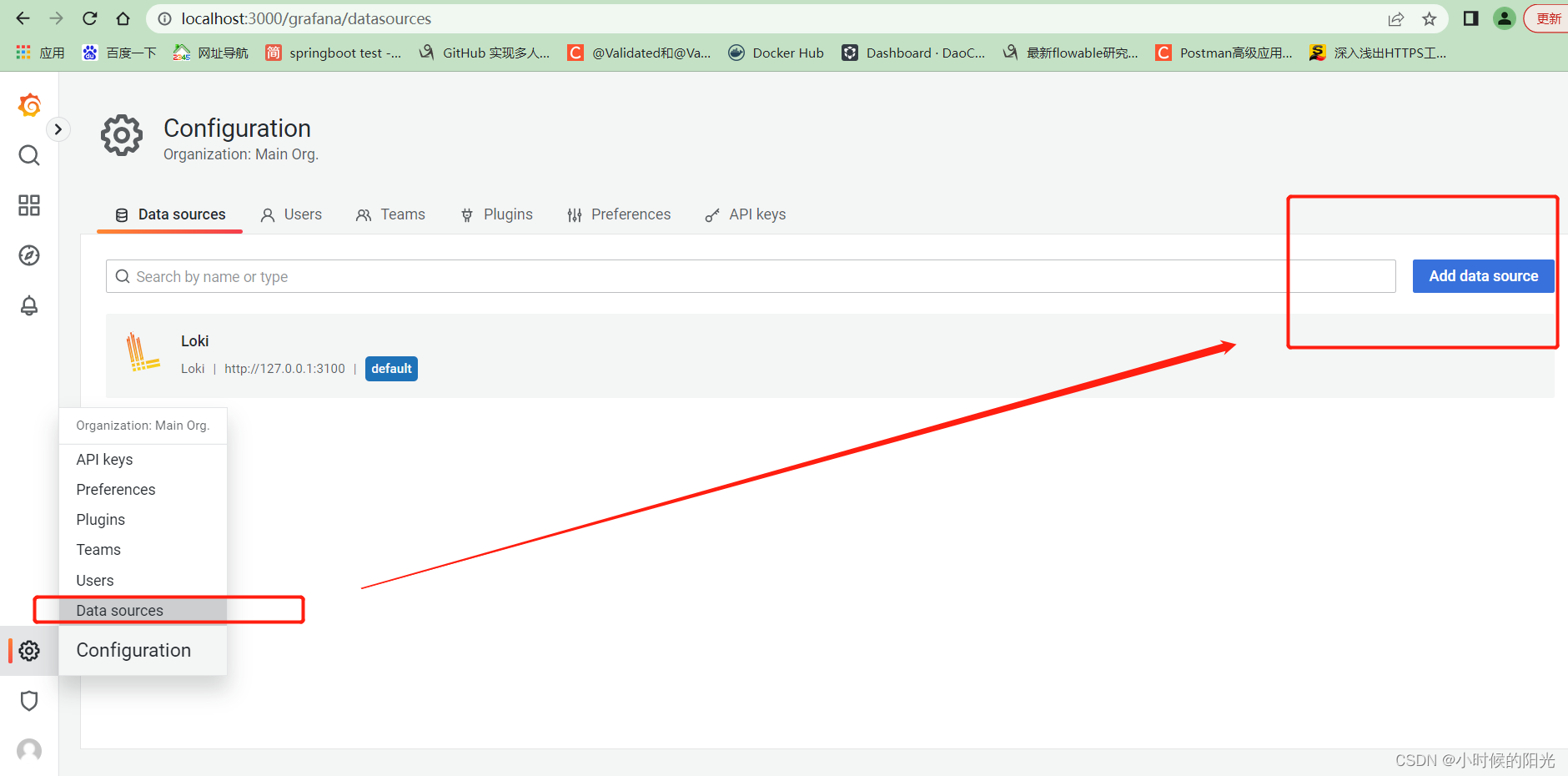
选择 Loki类型的数据源
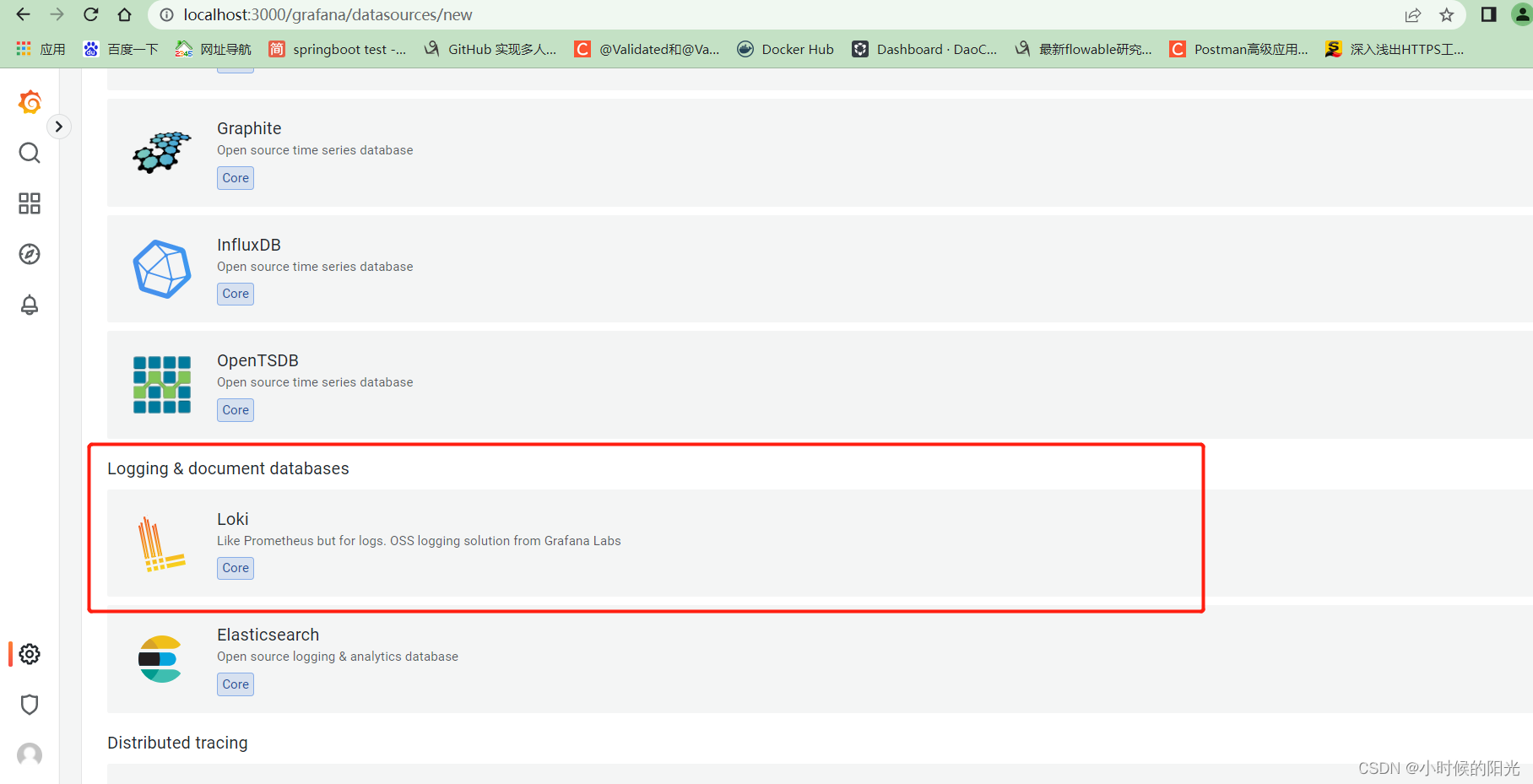
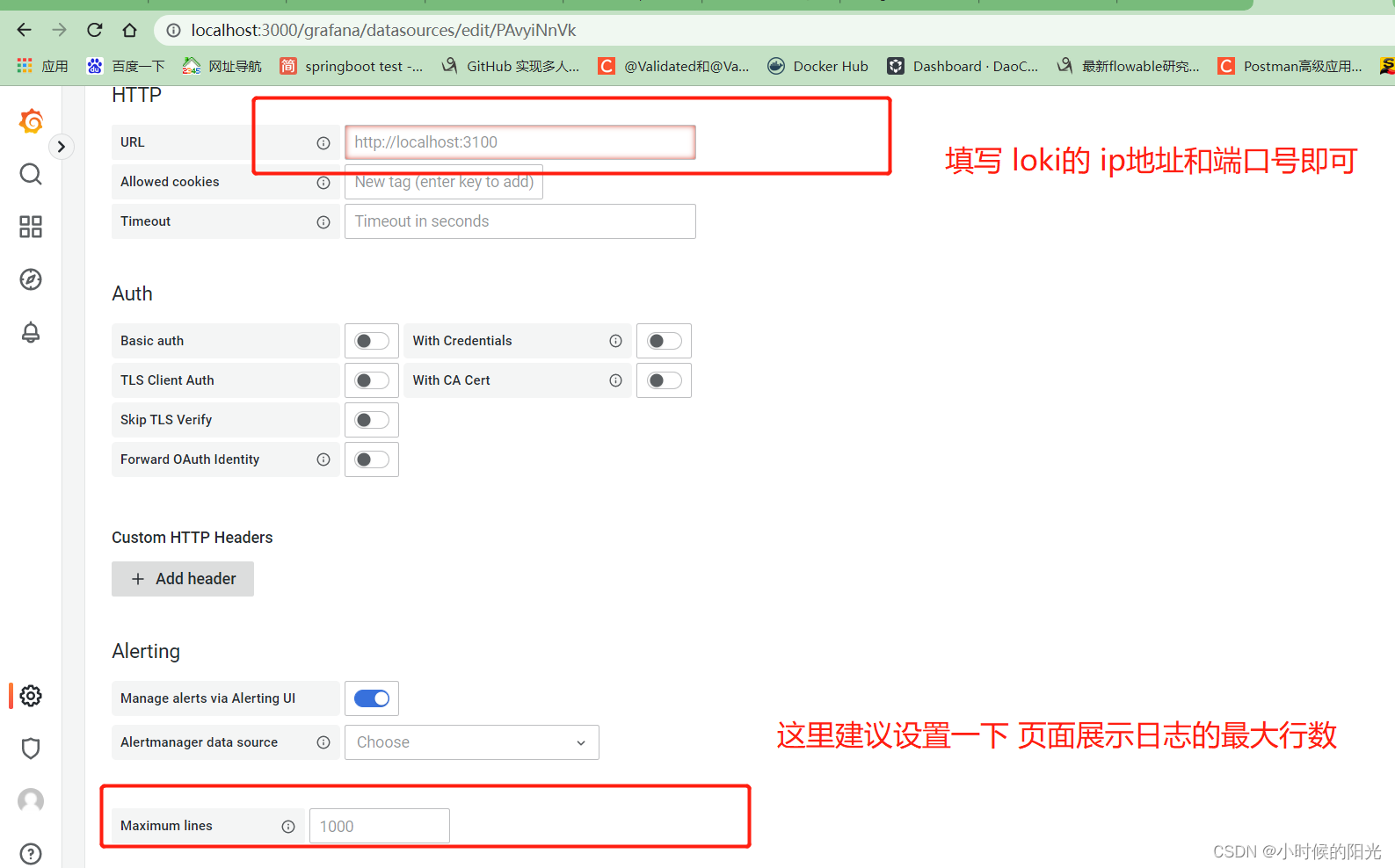
然后 测试 和 发布这个配置:
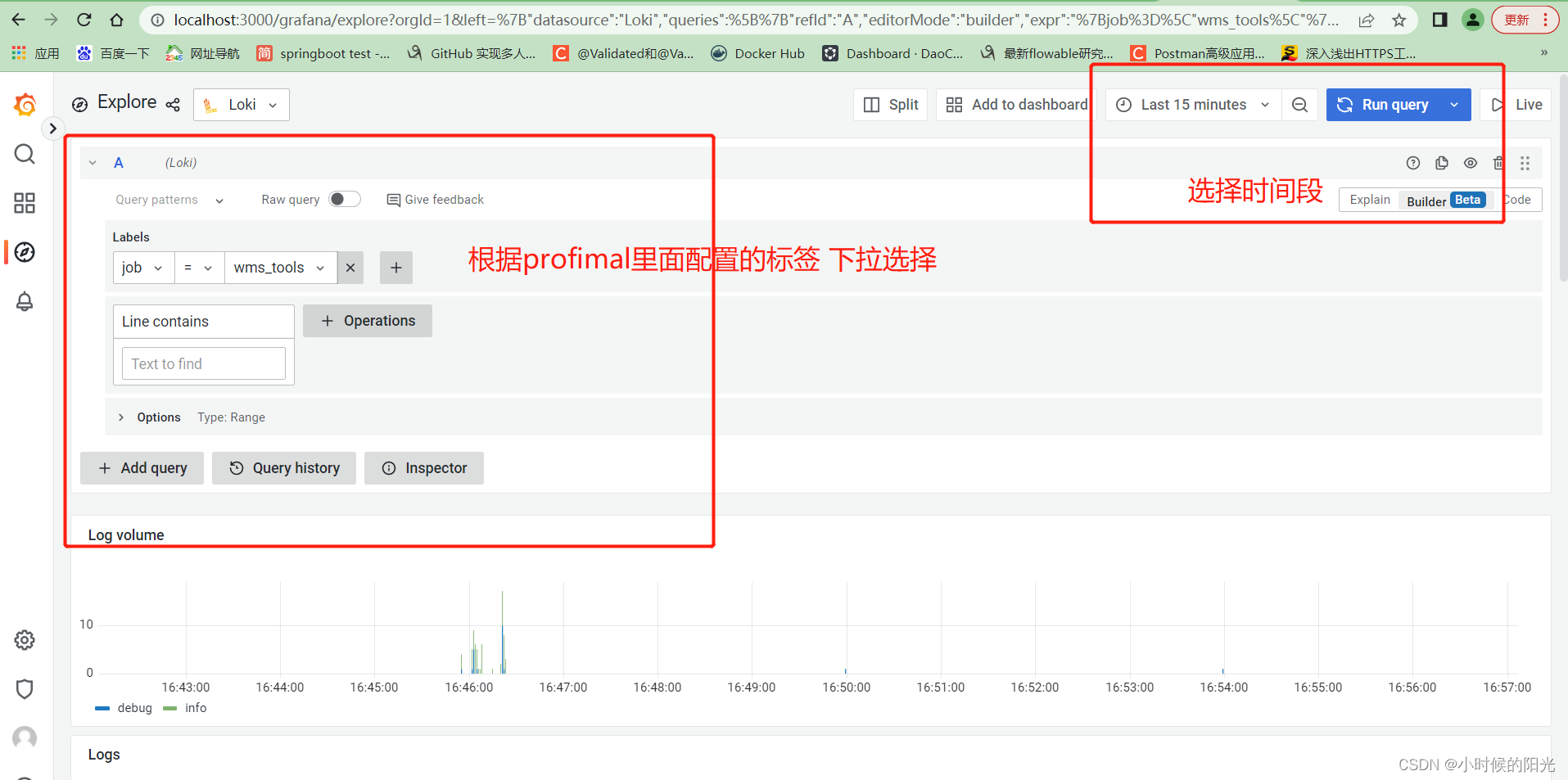
设置查询条件:
查看日志信息: 观察看看 多行合并是否生效 , 时间序列是否生效。
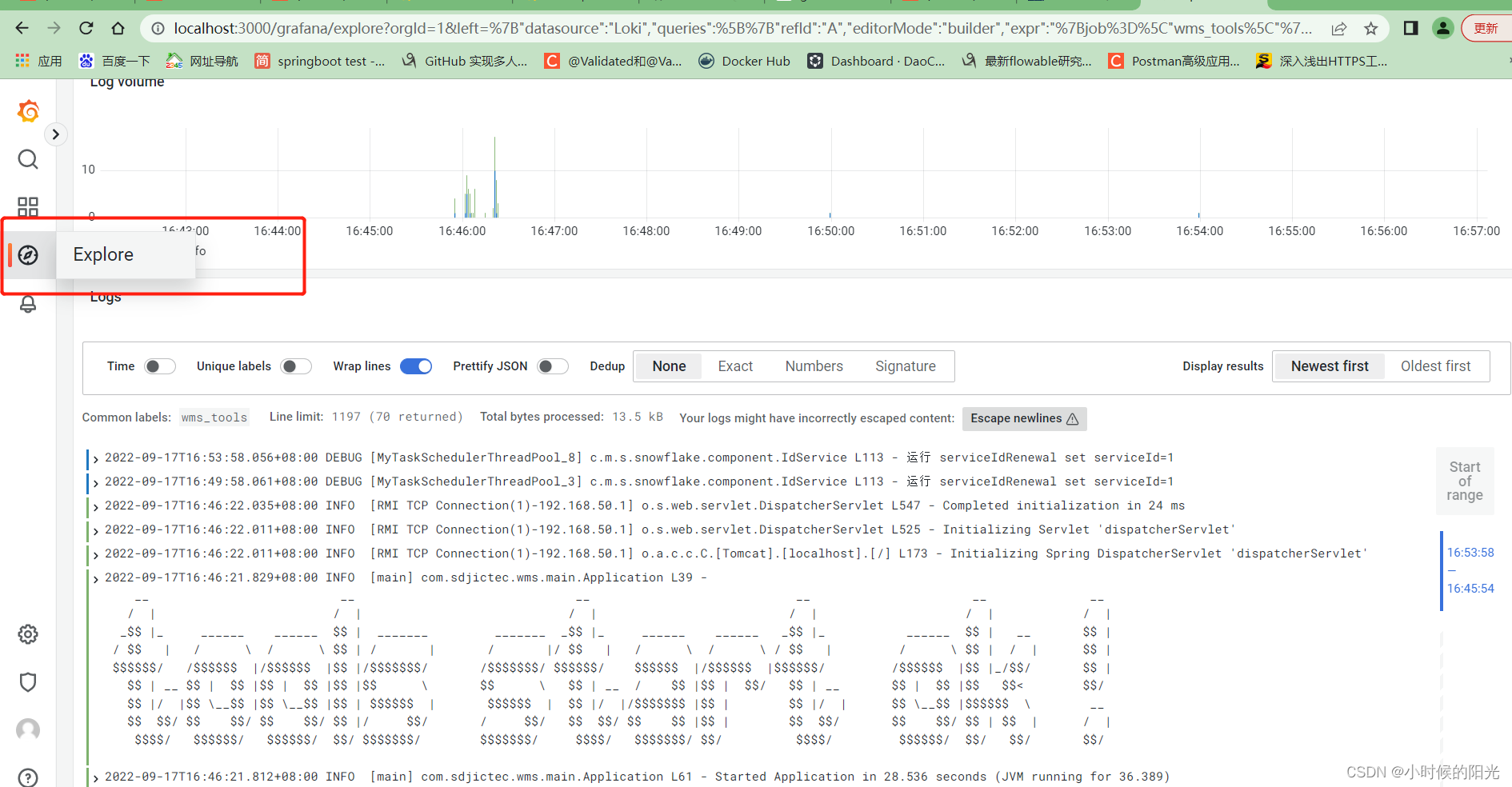
例如上面的 打印 banner tools start ok ! 如果没有配置多行合并,则每一行都会被当成单独的日志条目进行存储展示。
go语言正则表达式:
http://c.biancheng.net/view/5124.html
https://www.goregex.cn/
promtail pipeline 中文翻译,不过建议和官方文档对照看
点击访问
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
在运行Cucumber测试时,我得到(除了测试结果)大量调试/日志相关的输出形式:D,[2013-03-06T12:21:38.911829#49031]DEBUG--:SOAPrequest:D,[2013-03-06T12:21:38.911919#49031]DEBUG--:Pragma:no-cache,SOAPAction:"",Content-Type:text/xml;charset=UTF-8,Content-Length:1592W,[2013-03-06T12:21:38.912360#49031]WARN--:HTTPIexecutesHTTPPOSTusingt
我最近将我的http客户端切换到faraday,一切都按预期工作。我有以下代码来创建连接:@connection=Faraday.new(:url=>base_url)do|faraday|faraday.useCustim::Middlewarefaraday.request:url_encoded#form-encodePOSTparamsfaraday.request:jsonfaraday.response:json,:content_type=>/\bjson$/faraday.response:loggerfaraday.adapterFaraday.default_ada
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
像这样转换数组的最快/单行方法是什么:[1,1,1,1,2,2,3,5,5,5,8,13,21,21,21]...进入像这样的对象数组:[{1=>4},{2=>2},{3=>1},{5=>3},{8=>1},{13=>1},{21=>3}] 最佳答案 要获得所需的格式,您可以附加一个调用以映射到您的解决方案:array.inject({}){|h,v|h[v]||=0;h[v]+=1;h}.map{|k,v|{k=>v}}虽然它仍然是单行的,但它开始变得凌乱了。 关于ruby-在Ruby
我正在使用此代码在我的Sinatra应用程序中启用日志记录:log_file=File.new('my_log_file.log',"a")$stdout.reopen(log_file)$stderr.reopen(log_file)$stdout.sync=true$stderr.sync=true实际的日志记录是使用:logger.debug("Startingcall.Params=#{params.inspect}")事实证明,只有INFO或更高级别的日志消息被记录,而DEBUG消息没有被记录。我正在寻找一种将日志级别设置为DEBUG的方法。 最佳
我有这段代码来跟踪远程日志文件:defdo_tail(session,file)session.open_channeldo|channel|channel.on_datado|ch,data|puts"[#{file}]->#{data}"endchannel.exec"tail-f#{file}"endNet::SSH.start("host","user",:password=>"passwd")do|session|do_tailsession,"/path_to_log/file.log"session.loop我只想在file.log中检索带有ERROR字符串的行,我正在尝
当我为Daemons(1.1.0)gem设置日志记录参数时,我将如何实现与此行类似的行为?logger=Logger.new('foo.log',10,1024000)守护进程选项:options={:ARGV=>['start'],:dir_mode=>:normal,:dir=>log_dir,:multiple=>false,:ontop=>false:mode=>:exec,:backtrace=>true,:log_output=>true} 最佳答案 不幸的是,Daemonsgem不使用Logger。它将STDOUT和S