1、使用A30显卡,使用分布式并行Distributed Data Parallel,运行程序时显卡显存充满,卡在设置local_rank处,并未启动进程组
2、如图:


0、最新解决方案,针对Supermicro主板:BIOS->Advanced->NB Configuration->IOMMU->Disabled
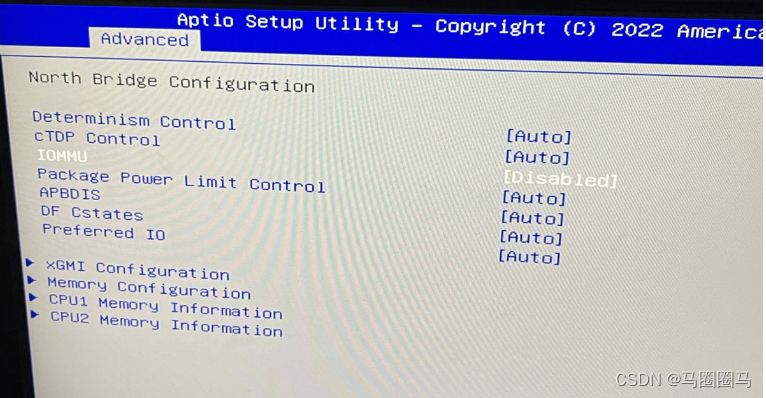
==其它型号的主板的BIOS可能还需要禁用ACS:
https://zhuanlan.zhihu.com/p/607203976
https://www.supermicro.com/support/faqs/faq.cfm?faq=20264
https://www.supermicro.com/support/faqs/faq.cfm?faq=22226
后面的1-4可不看了~
1、更换后端为“Gloo”,正常执行shell命令运行程序。
torch.distributed.init_process_group(backend="Gloo")
python -m torch.distributed.launch --nproc_per_node=7 --master_port 8888 main.py
2、仍旧使用“NCCL”后端,但需要更改环境变量,在shell命令前加入禁用P2P。
torch.distributed.init_process_group(backend="NCCL")
NCCL_P2P_DISABLE=1 python -m torch.distributed.launch --nproc_per_node=7 --master_port 8888 main.py
3、仍旧使用“NCCL”后端,但需要更改环境变量,永久更改环境设置,正常执行shell命令运行程序。
torch.distributed.init_process_group(backend="NCCL")
vim ~/.bashrc
export NCCL_P2P_DISABLE=1
source ~/.bashrc.
python -m torch.distributed.launch --nproc_per_node=7 --master_port 8888 main.py
4、建议使用第3个方案,据我测试,Gloo后端没有NCCL后端通信速度快,程序运行速度NCCL较快。另外,每次加上修改环境变量的命令也挺烦的,修改bash环境变量一劳永逸。
NCCL_P2P_DISABLE=1将禁用GPU之间直接通信(如使用NVlink或者PCIe),鉴于NVDIA官网显示A30支持NVlink或者PCIe,因此判断可能是硬件故障或者是软件版本不匹配导致P2P通信受阻,使得进程阻塞,程序挂起。
1:https://zhuanlan.zhihu.com/p/60054075
2:https://github.com/pytorch/pytorch/issues/23074
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我明白了:x,(y,z)=1,*[2,3]x#=>1y#=>2z#=>nil我想知道为什么z的值为nil。 最佳答案 x,(y,z)=1,*[2,3]右侧的splat*是内联扩展的,所以它等同于:x,(y,z)=1,2,3左边带括号的列表被视为嵌套赋值,所以它等价于:x=1y,z=23被丢弃,而z被分配给nil。 关于ruby-带括号和splat运算符的并行赋值,我们在StackOverflow上找到一个类似的问题: https://stackoverflow
假设您在Ruby中执行此操作:ar=[1,2]x,y=ar然后,x==1和y==2。是否有一种方法可以在我自己的类中定义,从而产生相同的效果?例如rb=AllYourCode.newx,y=rb到目前为止,对于这样的赋值,我所能做的就是使x==rb和y=nil。Python有这样一个特性:>>>classFoo:...def__iter__(self):...returniter([1,2])...>>>x,y=Foo()>>>x1>>>y2 最佳答案 是的。定义#to_ary。这将使您的对象被视为要分配的数组。irb>o=Obje
我想测试一个并行赋值的返回值,我写了puts(x,y=1,2),但是不行,打印错误信息:SyntaxError:(irb):74:syntaxerror,unexpected',',expecting')'puts(x,y=1,2)^(irb):74:syntaxerror,unexpected')',expectingend-of-input有什么问题吗? 最佳答案 你有两个问题。puts和(之间的空格防止括号列表被解释为参数列表。一旦你在方法名后放置一个空格,任何argumentlisthastobeoutsidethepare
我一直在尝试使用Thor编写一个小型库,以帮助我快速创建新项目和站点。我写了这个小方法:defssh(cmd)Net::SSH.start(server_ip,user,:port=>port)do|session|session.execcmdendend只是协助我在需要时在远程服务器上运行快速命令。问题是当我需要在远程端的sudo下运行命令时,脚本似乎卡在我身上。例如当执行这个...ssh("sudocp#{file_from_path}#{file_to_path}")脚本会提示我输入密码[sudo]passwordforuser:但是在输入之后整个事情就挂起。有人会碰巧知道它为
我有几个跳过的规范。Pending:(Failureslistedhereareexpectedanddonotaffectyoursuite'sstatus)1)...#Notyetimplemented#./spec/requests/request_spec.rb:22如何抑制未决规范的输出? 最佳答案 您可以添加以下配置选项以从运行中过滤掉所有待处理的规范:RSpec.configuredo|config|config.filter_run_excludingskip:trueend此外,here是一个更详细的抑制输出的建议
我不知道为什么,但是当我在我的Rails项目中运行rake命令时,没有任何反应。railsserver什么也不做。有什么建议吗? 最佳答案 你可以在开头添加一个“ruby-rtracer”以查看它卡在哪里。 关于ruby-on-rails-Rails和Rake命令挂起并且什么都不做,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/3657296/
我在一个ruby脚本中有4个测试,我使用命令运行它们rubytest.rb输出看起来像LoadedsuitetestStarted....Finishedin50.326546seconds.4tests,5assertions,0failures,0errors,0pendings,0omissions,0notifications100%passed我想要实现的是,并行运行所有4个测试,而不是按顺序运行。大约4个线程,每个线程运行一个测试,有效地将执行时间减少到4个测试中最慢的一个+并行执行的时间很短。我遇到了this,但这似乎并行运行多个ruby测试文件-假设我有test
我有以下代码:FTP...do|ftp|files.eachdo|file|...ftp.put(file)sleep1endend我想在单独的线程或某种并行方式中运行每个文件。执行此操作的正确方法是什么?这是对的吗?这是我对parallelgem的尝试FTP...do|ftp|Parallel.map(files)do|file|...ftp.put(file)sleep1endend并行的问题是puts/outputs可以像这样同时发生:as=[1,2,3,4,5,6,7,8]results=Parallel.map(as)do|a|putsaend我怎样才能强制执行看跌期权,就像
在我的应用程序中,我有几个生成器类,它们负责获取从外部API请求接收的数据,并将资源构建/保存到数据库中。我正在处理大量数据,并已实现并行gem以通过使用多个进程来加快处理速度。但是,我发现对使用Parallel的方法的任何测试都会失败并出现相同的错误:ActiveRecord::StatementInvalid:PG::ConnectionBad:PQconsumeInput()serverclosedtheconnectionunexpectedlyThisprobablymeanstheserverterminatedabnormallybeforeorwhileprocessi