复合索引 和 Include索引,但又在真实场景中用的特别多,本篇我们就从底层数据页层面厘清一下。索引覆盖 角度来展开吧,为了方便讲述,先上一个测试 sql:
IF(OBJECT_ID('t') IS NOT NULL) DROP TABLE t;
CREATE TABLE t(a INT IDENTITY, b CHAR(6), c CHAR(10) DEFAULT 'aaaaaaaaaa')
SET NOCOUNT ON
DECLARE @num INT
SET @num =10000
WHILE (@num <90000)
BEGIN
INSERT INTO t(b) VALUES ('b'+CAST(@num AS CHAR(5)))
SET @num=@num+1
END
CREATE CLUSTERED INDEX idx_a ON t(a)
CREATE INDEX idx_b ON t(b)
SELECT * FROM t;
 代码非常简单,在 t 表中创建三个列,插入 8w 条数据,然后创建两个索引,接下来做一个查询获取
代码非常简单,在 t 表中创建三个列,插入 8w 条数据,然后创建两个索引,接下来做一个查询获取 b,c 列。
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT b,c FROM t WHERE b IN ('b10000','b20000','b30000','b40000','b50000','b70000','b80000','b90000')
SET STATISTICS IO OFF
SET STATISTICS TIME OFF
表“t”。扫描计数 8,逻辑读取次数 30,物理读取次数 0,页面服务器读取次数 0,预读读取次数 0,页面服务器预读读取次数 0,LOb 逻辑读取次数 0,LOB 逻辑读取次数 0,LOB 页面服务器读取次数 0,LOB 预读读取次数 0,LOB 页面服务器预读读取次数 0。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 134 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
Completion time: 2023-01-06T08:47:45.2364473+08:00
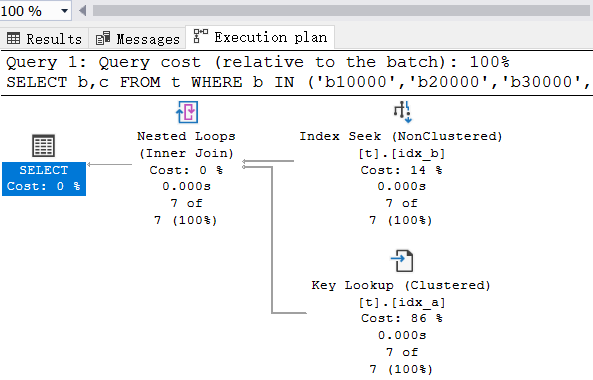 从执行计划看,这是一个经典的 书签查找,这种查找返回的行数越多性能越差,在索引优化时一般都会规避掉这种情况,我们也看到了逻辑读取次数有 30 次,那能不能再小一点呢?为了解决这个问题,干脆把 c 列也放到索引中去达到索引覆盖的效果,这就需要用到 复合索引 了,参考sql如下:
从执行计划看,这是一个经典的 书签查找,这种查找返回的行数越多性能越差,在索引优化时一般都会规避掉这种情况,我们也看到了逻辑读取次数有 30 次,那能不能再小一点呢?为了解决这个问题,干脆把 c 列也放到索引中去达到索引覆盖的效果,这就需要用到 复合索引 了,参考sql如下:
CREATE INDEX idx_complex ON t (b,c)
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
表“t”。扫描计数 8,逻辑读取次数 24,物理读取次数 0,页面服务器读取次数 0,预读读取次数 0,页面服务器预读读取次数 0,LOb 逻辑读取次数 0,LOB 逻辑读取次数 0,LOB 页面服务器读取次数 0,LOB 预读读取次数 0,LOB 页面服务器预读读取次数 0。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 96 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
Completion time: 2023-01-06T08:53:56.9688921+08:00
 从执行计划来看,这次没有走 书签查找 而是 索引查找,并且逻辑读也降到了 24 次,这是一个好的优化。相信有些朋友也知道用 Include索引 也能达到这个效果,接下来试着把复合索引给删了增加一个 Include索引,代码如下:
从执行计划来看,这次没有走 书签查找 而是 索引查找,并且逻辑读也降到了 24 次,这是一个好的优化。相信有些朋友也知道用 Include索引 也能达到这个效果,接下来试着把复合索引给删了增加一个 Include索引,代码如下:
DROP INDEX idx_complex ON dbo.t;
CREATE INDEX idx_include ON t(b) INCLUDE (c)
表“t”。扫描计数 8,逻辑读取次数 16,物理读取次数 0,页面服务器读取次数 0,预读读取次数 0,页面服务器预读读取次数 0,LOb 逻辑读取次数 0,LOB 逻辑读取次数 0,LOB 页面服务器读取次数 0,LOB 预读读取次数 0,LOB 页面服务器预读读取次数 0。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 73 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
Completion time: 2023-01-06T08:58:18.1122561+08:00
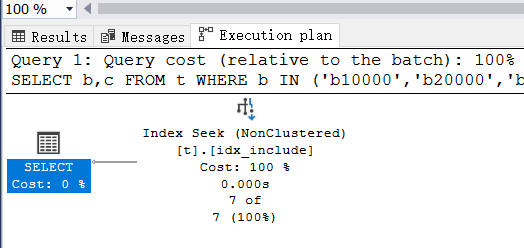 从执行计划来看也是走的 非聚集索引,而且逻辑读再次降到了 16 次,相比原始的书签查找已经优化了 50%,这是一个巨大的性能提升不是。到这里其实有一个问题,两种优化走的都是 非聚集索引,从逻辑读次数看貌似 Include索引 更好一些,为什么会这样呢?这就涉及到了底层存储,接下来一起扒一下。
从执行计划来看也是走的 非聚集索引,而且逻辑读再次降到了 16 次,相比原始的书签查找已经优化了 50%,这是一个巨大的性能提升不是。到这里其实有一个问题,两种优化走的都是 非聚集索引,从逻辑读次数看貌似 Include索引 更好一些,为什么会这样呢?这就涉及到了底层存储,接下来一起扒一下。
DBCC TRACEON(3604)
DBCC IND(MyTestDB,t,-1)
 从 IndexLevel=2 来看这个复合索引构成的B树已经达到了二层,接下来我们查一下 368 号数据页内容。
从 IndexLevel=2 来看这个复合索引构成的B树已经达到了二层,接下来我们查一下 368 号数据页内容。
DBCC PAGE(MyTestDB,1,368,2)
PAGE: (1:368)
Memory Dump @0x000000F555578000
000000F555578000: 01020002 00800001 00000000 00001b00 00000000 ....................
000000F555578014: 00000200 3e010000 601f9c00 70010000 01000000 ....>...`...p.......
000000F555578028: f8000000 e0680000 f5010000 00000000 00000000 .....h..............
000000F55557803C: 00000000 01000000 00000000 00000000 00000000 ....................
000000F555578050: 00000000 00000000 00000000 00000000 16623130 .................b10
000000F555578064: 30303061 61616161 61616161 61010000 00380500 000aaaaaaaaaa....8..
000000F555578078: 00010004 00001662 38333631 36616161 61616161 .......b83616aaaaaaa
000000F55557808C: 61616191 1f010070 05000001 00040000 00006231 aaa....p..........b1
OFFSET TABLE:
Row - Offset
1 (0x1) - 126 (0x7e)
0 (0x0) - 96 (0x60)
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
PAGE: (1:1632)
Memory Dump @0x000000F555578000
...
000000F555578050: 00000000 00000000 00000000 00000000 16623135 .................b15
000000F555578064: 32383761 61616161 61616161 61a81400 00040000 287aaaaaaaaaa.......
000000F555578078: 16623135 32383861 61616161 61616161 61a91400 .b15288aaaaaaaaaa...
000000F55557808C: 00040000 16623135 32383961 61616161 61616161 .....b15289aaaaaaaaa
000000F5555780A0: 61aa1400 00040000 16623135 32393061 61616161 a........b15290aaaaa
000000F5555780B4: 61616161 61ab1400 00040000 16623135 32393161 aaaaa........b15291a
000000F5555780C8: 61616161 61616161 61ac1400 00040000 16623135 aaaaaaaaa........b15
000000F5555780DC: 32393261 61616161 61616161 61ad1400 00040000 292aaaaaaaaaa.......
000000F5555780F0: 16623135 32393361 61616161 61616161 61ae1400 .b15293aaaaaaaaaa...
000000F555578104: 00040000 16623135 32393461 61616161 61616161 .....b15294aaaaaaaaa
000000F555578118: 61af1400 00040000 16623135 32393561 61616161 a........b15295aaaaa
000000F55557812C: 61616161 61b01400 00040000 16623135 32393661 aaaaa........b15296a
000000F555578140: 61616161 61616161 61b11400 00040000 16623135 aaaaaaaaa........b15
...
 用同样的方式观察下 Include索引,发现 IndexLevel=1,说明只有一层。
用同样的方式观察下 Include索引,发现 IndexLevel=1,说明只有一层。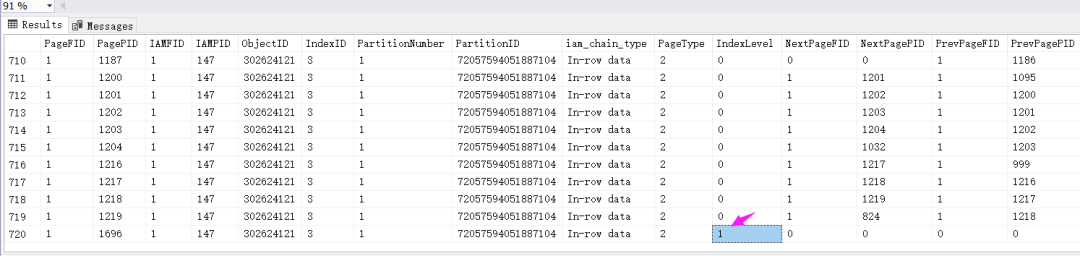 再用 DBCC 观察下分支节点的布局。
再用 DBCC 观察下分支节点的布局。
PAGE: (1:1696)
Memory Dump @0x000000F554F78000
000000F554F78000: 01020001 00820001 00000000 00001100 00000000 ....................
000000F554F78014: 00000601 42010000 1c09d814 a0060000 01000000 ....B.... ..........
000000F554F78028: 0f010000 78310000 39010000 00000000 00000000 ....x1..9...........
000000F554F7803C: f01efa04 00000000 00000000 00000000 00000000 ....................
000000F554F78050: 00000000 00000000 00000000 00000000 16623130 .................b10
000000F554F78064: 30303001 00000088 03000001 00030000 16623130 000..............b10
000000F554F78078: 33313138 010000b0 03000001 00030000 16623130 3118.............b10
000000F554F7808C: 3632326f 020000b1 03000001 00030000 16623130 622o.............b10
000000F554F780A0: 393333a6 030000b2 03000001 00030000 16623131 933..............b11
...
PAGE: (1:1218)
Memory Dump @0x000000F554F78000
000000F554F78000: 01020000 04020001 c1040000 01001500 c3040000 ....................
000000F554F78014: 01003701 42010000 0a00881d c2040000 01000000 ..7.B...............
000000F554F78028: 0f010000 00310000 03000000 00000000 00000000 .....1..............
000000F554F7803C: e7351886 00000000 00000000 00000000 00000000 .5..................
000000F554F78050: 00000000 00000000 00000000 00000000 16623833 .................b83
000000F554F78064: 313235a6 1d010061 61616161 61616161 61040000 125....aaaaaaaaaa...
000000F554F78078: 16623833 313236a7 1d010061 61616161 61616161 .b83126....aaaaaaaaa
000000F554F7808C: 61040000 16623833 313237a8 1d010061 61616161 a....b83127....aaaaa
000000F554F780A0: 61616161 61040000 16623833 313238a9 1d010061 aaaaa....b83128....a
000000F554F780B4: 61616161 61616161 61040000 16623833 313239aa aaaaaaaaa....b83129.
000000F554F780C8: 1d010061 61616161 61616161 61040000 16623833 ...aaaaaaaaaa....b83
000000F554F780DC: 313330ab 1d010061 61616161 61616161 61040000 130....aaaaaaaaaa...
...
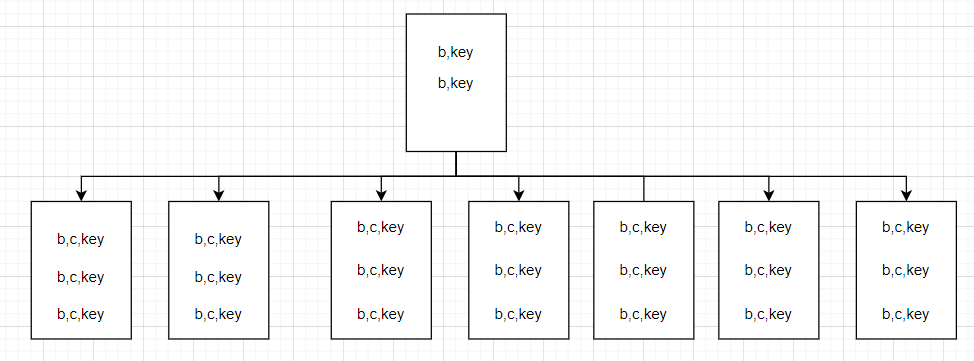 从图中可以看出,Include索引 的分支节点是不包含 c 列的,这个列只会保存在 叶子节点 中,再结合树的高度来看就能解释为什么 Include索引 的逻辑读要少于 复合索引。
从图中可以看出,Include索引 的分支节点是不包含 c 列的,这个列只会保存在 叶子节点 中,再结合树的高度来看就能解释为什么 Include索引 的逻辑读要少于 复合索引。为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
请帮助我理解范围运算符...和..之间的区别,作为Ruby中使用的“触发器”。这是PragmaticProgrammersguidetoRuby中的一个示例:a=(11..20).collect{|i|(i%4==0)..(i%3==0)?i:nil}返回:[nil,12,nil,nil,nil,16,17,18,nil,20]还有:a=(11..20).collect{|i|(i%4==0)...(i%3==0)?i:nil}返回:[nil,12,13,14,15,16,17,18,nil,20] 最佳答案 触发器(又名f/f)是
我有一个包含多个键的散列和一个字符串,该字符串不包含散列中的任何键或包含一个键。h={"k1"=>"v1","k2"=>"v2","k3"=>"v3"}s="thisisanexamplestringthatmightoccurwithakeysomewhereinthestringk1(withspecialcharacterslike(^&*$#@!^&&*))"检查s是否包含h中的任何键的最佳方法是什么,如果包含,则返回它包含的键的值?例如,对于上面的h和s的例子,输出应该是v1。编辑:只有字符串是用户定义的。哈希将始终相同。 最佳答案
我正在检查一个Rails项目。在ERubyHTML模板页面上,我看到了这样几行:我不明白为什么不这样写:在这种情况下,||=和ifnil?有什么区别? 最佳答案 在这种特殊情况下没有区别,但可能是出于习惯。每当我看到nil?被使用时,它几乎总是使用不当。在Ruby中,很少有东西在逻辑上是假的,只有文字false和nil是。这意味着像if(!x.nil?)这样的代码几乎总是更好地表示为if(x)除非期望x可能是文字false。我会将其切换为||=false,因为它具有相同的结果,但这在很大程度上取决于偏好。唯一的缺点是赋值会在每次运行
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
打印1:defsum(i)i=i+[2]end$x=[1]sum($x)print$x打印12:defsum(i)i.push(2)end$x=[1]sum($x)print$x后者是修改全局变量$x。为什么它在第二个例子中被修改而不是在第一个例子中?类Array的任何方法(不仅是push)都会发生这种情况吗? 最佳答案 变量范围在这里无关紧要。在第一段代码中,您仅使用赋值运算符=为变量i赋值,而在第二段代码中,您正在修改$x(也称为i)使用破坏性方法push。赋值从不修改任何对象。它只是提供一个名称来引用一个对象。方法要么是破坏性
Ruby中的Fixnum方法.next和.succ有什么区别?看起来它的工作原理是一样的:1.next=>21.succ=>2如果有什么不同,为什么有两种方法做同样的事情? 最佳答案 它们是等价的。Fixnum#succ只是Fixnum#next的同义词。他们甚至在thereferencemanual中共享同一block. 关于ruby-Ruby中.next和.succ的区别,我们在StackOverflow上找到一个类似的问题: https://stacko
我的Gallery模型中有以下查询:media_items.includes(:photo,:video).rank(:position_in_gallery)我的图库模型有_许多媒体项,每个都有一个照片或视频关联。到目前为止,一切正常。它返回所有media_items包括它们的photo或video关联,由media_item的position_in_gallery属性排序。但是我现在需要将此查询返回的照片限制为仅具有is_processing属性的照片,即nil。是否可以进行相同的查询,但条件是返回的照片等同于:.where(photo:'photo.is_processingIS
我明白了defa(&block)block.call(self)end和defa()yieldselfend导致相同的结果,如果我假设有这样一个blocka{}。我的问题是-因为我偶然发现了一些这样的代码,它是否有任何区别或者是否有任何优势(如果我不使用变量/引用block):defa(&block)yieldselfend这是一个我不理解&block用法的具体案例:defrule(code,name,&block)@rules=[]if@rules.nil?@rules 最佳答案 我能想到的唯一优点就是自省(introspecti