关于作者
🐶 程序猿周周
⌨️ 短视频小厂BUG攻城狮
🤺 如果文章对你有帮助,记得关注、点赞、收藏,一键三连哦,你的支持将成为我最大的动力
本文是《后端面试小册子》系列的第 1️⃣2️⃣ 篇文章,该系列将整理和梳理笔者作为 Java 后端程序猿在日常工作以及面试中遇到的实际问题,通过这些问题的系统学习,也帮助笔者顺利拿到阿里、字节、华为、快手等多个大厂 Offer,也祝愿大家能够早日斩获自己心仪的 Offer。
PS:《后端面试小册子》已整理成册,目前共十三章节,总计约二十万字,欢迎👏🏻关注公众号【程序猿周周】获取电子版和更多学习资料(最新系列文章也会在此陆续更新)。公众号后台可以回复关键词「电⼦书」可获得这份面试小册子。文中所有内容都会在 Github 开源,项目地址 csnotes,如文中存在错误,欢迎指出。如果觉得文章还对你有所帮助,赶紧点个免费的 star 支持一下吧!

文章目录
设计模式是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性、程序的重用性。
设计模式可在多个项目中重用。
设计模式提供了一个帮助定义系统架构的解决方案。
设计模式吸收了软件工程的经验。
设计模式为应用程序的设计提供了透明性。
设计模式是被实践证明切实有效的,由于它们是建立在专家软件开发人员的知识和经验之上的。
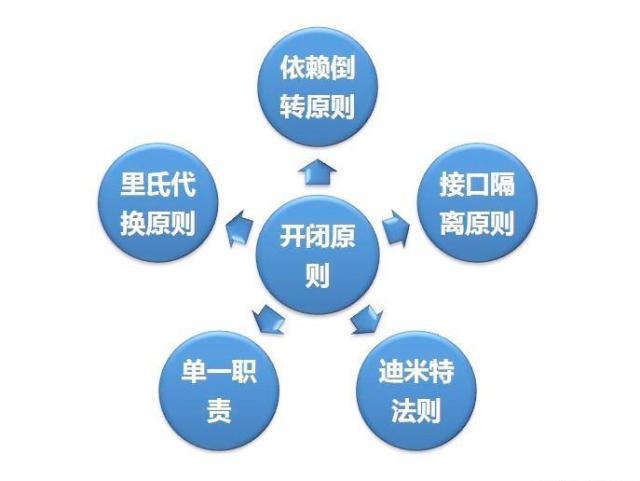
1)单一责任原则(Principle of single responsibility):一个类或者一个方法只负责一项职责。
2)里氏替换原则(Liskov Substitution Principle):使用基类的任何地方可以使用继承的子类,完美的替换基类。
3)依赖倒转原则(Dependence Inversion Principle):其核心思想是面向接口编程。
4)接口隔离原则(Interface Segregation Principle):使用多个隔离的接口,比使用单个接口要好。还是一个降低类之间的耦合度的意思。
5)迪米特法则(Demeter Principle):最少知道原则,一个对象应当对其他对象有尽可能少地了解,简称类间解耦。
6)开闭原则(Open Close Principle):尽量通过扩展软件实体来解决需求变化,而不是通过修改已有的代码来完成变化。
通常情况下,我们可以将常用的 23 种设计模式分为创建模式、结构模式以及行为模式三种类型。
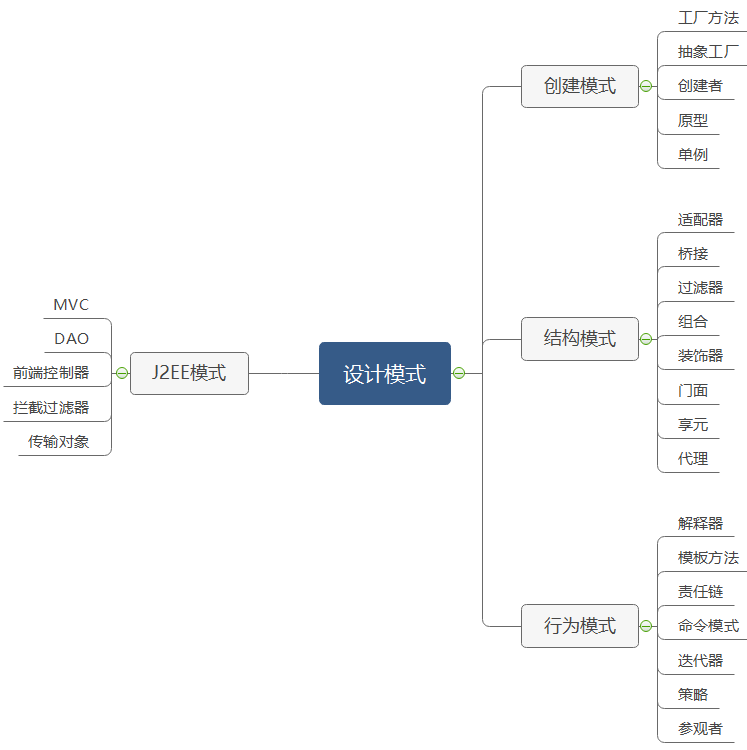
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代器模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
保证一个类只有一个实例,并且提供一个访问该全局访问点。
1)应用程序的日志应用,一般都可用单例模式实现,这一般是由于共享的日志文件一直处于打开状态,因为只能有一个实例去操作,否则内容不好追加。
2)数据库连接池的设计一般也是采用单例模式,因为数据库连接是一种数据库资源。
3)多线程的线程池的设计一般也是采用单例模式,这是由于线程池要方便对池中的线程进行控制。
单例模式的创建方式主要分为懒汉式和饿汉式两种,并在次基础衍生出更多实现方式:
1)饿汉式:类初始化时会立即创建该类单例对象,线程天生安全,调用效率高。
2)懒汉式:类初始化时,不会立即实例化该对象,而是在真正需要使用的时候才会创建该对象,具备懒加载功能。
3)静态内部方式:结合了懒汉式和饿汉式各自的优点,真正需要对象的时候才会加载,加载类是线程安全的。
public class Demo3 {
public static class SingletonClassInstance {
private static final Demo3 DEMO_3 = new Demo3();
}
// 方法没有同步
public static Demo3 getInstance() {
return SingletonClassInstance.DEMO_3;
}
}
4)枚举单例:使用枚举实现单例模式,其优点是实现简单、调用效率高,枚举本身就是单例,由 JVM 从根本上提供保障,避免通过反射和反序列化的漏洞,而缺点是没有延迟加载。
public class Demo4 {
public static Demo4 getInstance() {
return Demo.INSTANCE.getInstance();
}
//定义枚举
private static enum Demo {
INSTANCE;
// 枚举元素为单例
private Demo4 demo4;
private Demo() {
demo4 = new Demo4();
}
public Demo4 getInstance() {
return demo4;
}
}
}
5)双重检测锁方式:因为 JVM 重排序的原因,可能会初始化多次,不推荐使用。
public class Demo5 {
private volatile static Demo5 demo5;
public static Demo5 getInstance() {
if (demo5 == null) {
synchronized (Demo5.class) {
if (demo5 == null) {
demo5 = new Demo5();
}
}
}
return demo5;
}
}
工厂模式提供了一种创建对象的最佳方式。在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。
1)工厂模式是我们最常用的实例化对象模式了,是用工厂方法代替new操作的一种模式。
2)利用工厂模式可以降低程序的耦合性,为后期的维护修改提供了很大的便利。
3)将选择实现类、创建对象统一管理和控制。从而将调用者跟我们的实现类解耦。
实现了创建者和调用者分离,工厂模式又可以分为简单工厂、工厂方法以及抽象工厂三种模式。
1)简单工厂:用来生产同一等级结构中的任意产品。(不支持拓展增加产品)
2)工厂方法:用来生产同一等级结构中的固定产品。(支持拓展增加产品)
3)抽象工厂:用来生产不同产品族的全部产品。(不支持拓展增加产品;支持增加产品族)
建造者模式是将一个复杂的对象的构建与它的表示分离,使得同样的构建过程可以创建不同的方式进行创建。
工厂类模式是提供的是创建单个类的产品,而建造者模式则是将各种产品集中起来进行管理,更加关注零件装配,用来具有不同的属性的产品。
1)Java 语言中的 StringBuilder。
原型设计模式简单来说就是克隆。原型表明了有一个样板实例,这个原型是可定制的。
原型模式多用于创建复杂的或者构造耗时的实例,因为这种情况下,复制一个已经存在的实例可使程序运行更高效。
1)类初始化需要消化非常多的资源,这个资源包括数据、硬件资源等。这时我们就可以通过原型拷贝避免这些消耗。
2)通过 new 产生的一个对象需要非常繁琐的数据准备或者权限,这时可以使用原型模式。
3)一个对象需要提供给其他对象访问,而且各个调用者可能都需要修改其值时,可以考虑使用原型模式拷贝多个对象供调用者使用,即保护性拷贝。
代理模式通过代理控制对象的访问,可以在这个对象调用方法之前、调用方法之后去处理,甚至添加新的功能。(AOP 的实现原理)
Spring AOP、日志打印、异常处理、事务控制、权限控制等。
1)静态代理:简单代理模式,是动态代理的理论基础,也是常见使用在代理模式。
2)JDK 动态代理:使用反射完成代理,需要有顶层接口才能使用,常见是Mybatis 的 mapper 文件。
3)cglib 动态代理:也是使用反射完成代理,使用字节码技术,可以直接代理类,有个缺点就是不能对 final 类进行继承。
也被叫做门面模式,用于隐藏系统的复杂性,并向客户端提供了一个客户端可以访问系统的接口。
策略模式定义了一系列的算法或业务逻辑操作,并将每一个算法、逻辑、操作封装起来,而且使它们还可以相互替换。
模板方法模式定义一个操作中的业务处理逻辑骨架(父类),而将一些步骤延迟到子类中。使得子类可以不改变一个操作的结构来重定义该操作逻辑的实现。
实现一些操作时,整体步骤很固定,但是其中一小部分需要改变,这时候可以使用模板方法模式,将容易变的部分抽象出来,供子类实现。
举个例子,去餐厅吃饭时,餐厅给我们提供了一个模板就是:看菜单,点菜,吃饭,付款,走人。这里的点菜和付款是不确定的,需要由子类来完成的,其他的则是一个模板。
观察者模式是一种行为性模型,又叫发布-订阅模式。其定义对象之间一种一对多的依赖关系,使得当一个对象改变状态,则所有依赖于它的对象都会得到通知并自动更新。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候