由于转转前端业务方向主要偏向于 C 端,比如 App端内 H5、 小程序内 H5 等,并且技术栈以 Hybrid 为主(承载容器为转转标准化webview)。但是,近些年随着业务不断扩大,逐渐出现了如乾数据平台、行星平台等 专门服务 B 端的FE项目。但是没有相关性能数据来作为参考支撑,比如需要分析用户体验质量;分析现有页面性能缺陷以及后续需要做性能优化的方向等。因此,需要一款符合转转内部埋点上报体系的 PC 端项目网页的性能统计平台。
由于内部性能埋点统计体系不支持分批/分段上报,每个 Router 都需要作为一个单独的页面进行一次性的性能数据上报。在 B 端,一些新的指标需要支持和特殊处理。因此,在数据采集统计方面,我们会遇到以下几个问题。
定义好哪些性能指标需要上报,是做好一个完善的采集性能数据采集 sdk 的前提条件,经过分析主要将指标分为两类:1. 纯 H5 页面性能指标 2. 页面相关业务性指标。
以上提到的绝大部分指标,可以通过浏览器提供的 PerformanceNavigationTiming PerformanceResourceTiming API 和 谷歌团队提供的 web-vitals 工具函数很方便的进行获取和计算。
所谓业务性指标,主要是作为查询分析的一些要素,比如 我们想查询某个业务线的某个项目的某个页面在某个平台下某个性能指标的表现如何?那么就需要一些非页面性能本身的业务要素指标进行定义和上报统计。
业务指标主要包括:actiontype 埋点类型标识 、 pagetype 业务线/项目标识、pageid 页面标识 、 clientType 端信息、 pagestate 页面状态、pageurl 页面url、 cookieid 用户id、 fromType 来源、 loadcnt 加载次数 等等。
PS: web-vitals 由于在苹果和低版本安卓的兼容性存在问题,因此没有在 C 端作为一个必选项,但 B 端用户绝大多数使用 chromium 内核浏览器,所以大胆的将 web-vitals 纳入采集指标中
上面进行了各种指标的定义,那么如何高效有序的接入到转转埋点体系内进行上报统计呢?转转内部其实已经有了 C 端埋点体系,其实只需要按照一定的规则进行接入即可,主要是性能平台B端项目需要的字段和后端已有日志表结构做好关系映射和扩展。
为了解决上面提到B端项目的特有问题,以及满足上述提到所有性能指标、业务指标都可以很优雅的进行上报统计,方便在代码层面更好的进行结构上的解耦,并且尽量做到性能计算统计相关程序不影响页面本身的性能,在技术实现设计层我们把上面的指标做了一些分类,比如 同步计算指标(基础业务同步指标、基础性能资源同步指标)、异步计算指标(性能异步指标、后置异步指标)等。具体如下图所示。
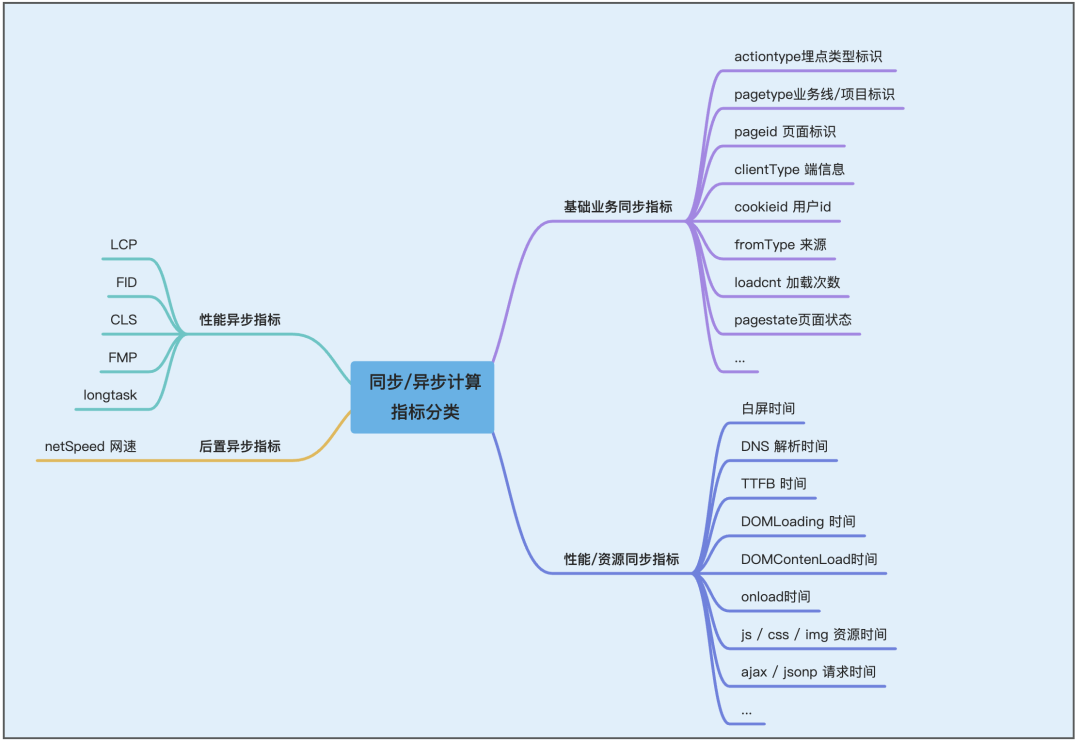
技术层面指标分类
下面详细介绍一下一些关键逻辑是怎么处理的?各类性能指标具体是怎么计算的?下面列出了部分指标怎么获取和计算的关键代码。
SPA 项目的路由页面的拦截关键逻辑:
const hackRouter = () => {
if (!window?.history?.pushState) {
return;
}
// 浏览器的历史记录发生变化时被触发, 导航前进、后退
const oldOnPopState = window.onpopstate;
window.onpopstate = function(this: WindowEventHandlers, ...args: any[]): any {
const to = window.location.href;
const from = lastHref;
lastHref = to;
// 通知订阅的回调
triggerHandlers('history', {
from,
to
});
if (oldOnPopState) {
try {
return oldOnPopState.apply(this, args);
} catch (e) {}
}
};
// history pushState 或 replaceState 触发,通过 history api 方式
const wrapHistoryFn = (type: 'pushState'|'replaceState') => {
const originalHistoryFunction = window.history[type]
return function(this: History, ...args: any[]): void {
const url = args.length > 2 ? args[2] : undefined;
if (url) {
// coerce to string (this is what pushState does)
const from = lastHref;
const to = String(url);
lastHref = to;
// 通知订阅的回调
triggerHandlers('history', {
from,
to
});
}
return originalHistoryFunction.apply(this, args);
};
};
window.history.pushState = wrapHistoryFn("pushState");
window.history.replaceState = wrapHistoryFn("replaceState");
}性能基础指标的获取相关代码:
// 获取 PerformanceTiming 相关数据
export const getPerformanceTimingData = (task: TaskTypes) => {
if (!window?.performance?.timing) return {}
const { metrics } = task;
const { state } = task.ctx;
const ptiming = performance.timing;
// 默认为 -1 方便过滤无效值
const result = {
blankTime: -1,
dnsTime: -1,
httpTime: -1,
domTime: -1,
domReady: -1,
// ...
}
// 页面加载状态
if(state === 'pageload') {
// ...
// 白屏
result.blankTime = fix(ptiming.responseStart - ptiming.navigationStart);
// DNS查询
result.dnsTime = fix(ptiming.domainLookupEnd - ptiming.domainLookupStart);
// HTTP请求
result.httpTime = fix(ptiming.responseEnd - ptiming.responseStart);
// 解析dom树
result.domTime = fix(ptiming.domComplete - ptiming.domInteractive);
// DOMready
result.domReady = fix(ptiming.domContentLoadedEventEnd - ptiming.navigationStart)
// ...
}
// 路由切换状态
if (state === 'navigation') {
// ...
}
return result
}资源相关指标的数据获取关键逻辑:
// 记录
let performanceCursor: number = 0;
// 获取当前页面资源列表
export const startPerformance = (task: TaskTypes) => {
const { timeOrigin } = task.ctx;
if (!window.performance || !window.performance.getEntries || !timeOrigin) {
return;
}
// performanceEntries
const performanceEntries = performance.getEntries();
const pss = performanceEntries.slice(performanceCursor);
// 处理 各种 performanceEntry 资源
formatResourceEntries(task, pss);
performanceCursor = Math.max(performanceEntries.length - 1, 0);
}
export const formatResourceEntries = (task: TaskTypes, entries: PerformanceEntryList) => {
const { state, startTimestamp, timeOrigin } = task.ctx;
const { metrics } = task
entries.forEach(entry => {
const startTime = entry.startTime;
// console.log( timeOrigin, startTime, startTimestamp, timeOrigin + startTime < startTimestamp)
if (state === 'navigation' && timeOrigin + startTime < startTimestamp) {
return;
}
const baseStartTime = startTimestamp - timeOrigin;
switch (entry.entryType) {
case 'navigation':
// 处理 bodysize
// ...
case 'paint':
// 处理 paint 指标 fcp fp
// ...
case 'resource':
// 序列化各种资源, 如js/css/img/jsonp/ajax/fetch/iframe...
calcResource(entry, result, baseStartTime);
}
// ...
}业务指标数据的获取:
// 初始化基础业务指标
export const initBaseData = (task: TaskTypes) => {
const { params = { backup: {} }, options = {} } = task;
// ...
Object.assign(params, {
pagetype: options?.pagetype || pagetype,
actiontype: options?.actiontype || actiontype,
appid: options?.appid || appid,
// and more ...
});
return task;
}longTask 的记录获取:
function startLongTasks(): void {
const entryHandler = (entries: PerformanceEntry[]): void => {
for (const entry of entries) {
const startTime = entry.startTime
const duration = entry.duration;
const endTime = startTime + duration;
const longtask = {
name: `longtask-${++n}`,
startTime,
endTime,
duration
}
longTasks.push(longtask);
}
};
if(PerformanceObserver?.supportedEntryTypes?.includes('longtask')) {
// 注册 longtask 异步任务
observe('longtask', entryHandler);
}
}在实际项目统计时,发现一些性能指标算法的适用性问题需要注意:
- LCP 算法存在的问题。比如:触发条件限制的问题,当检测到用户输入时候 FMP算法会停止计算,就导致某些场景触发不了(比如主要内容还没显示就点击页面)。白屏占位图问题,页面初始有较大的白屏占位图时 即使后面被移除了,LCP 算法还会把它当作主要内容。
- FMP 算法不适合某些特殊场景。比如:2/3 是金刚位图片布局,最下面 1/3 区域有一个瀑布流,由于FMP算法计算规则会导致统计时间在瀑布流请求之后展现后,就导致直观上的页面首屏时间变大。
数据可以计算并获取了,那么如何进行友好的处理上报?
由于内部埋点提下不支持回话形式的分段上报,那么就需要在前端提前准备好所有需要需要上报的数据的处理,整体B端 SPA 项目性能数据处理的上报处理机制,以及同步任务数据、异步任务数据任务的处理流如下图所示。
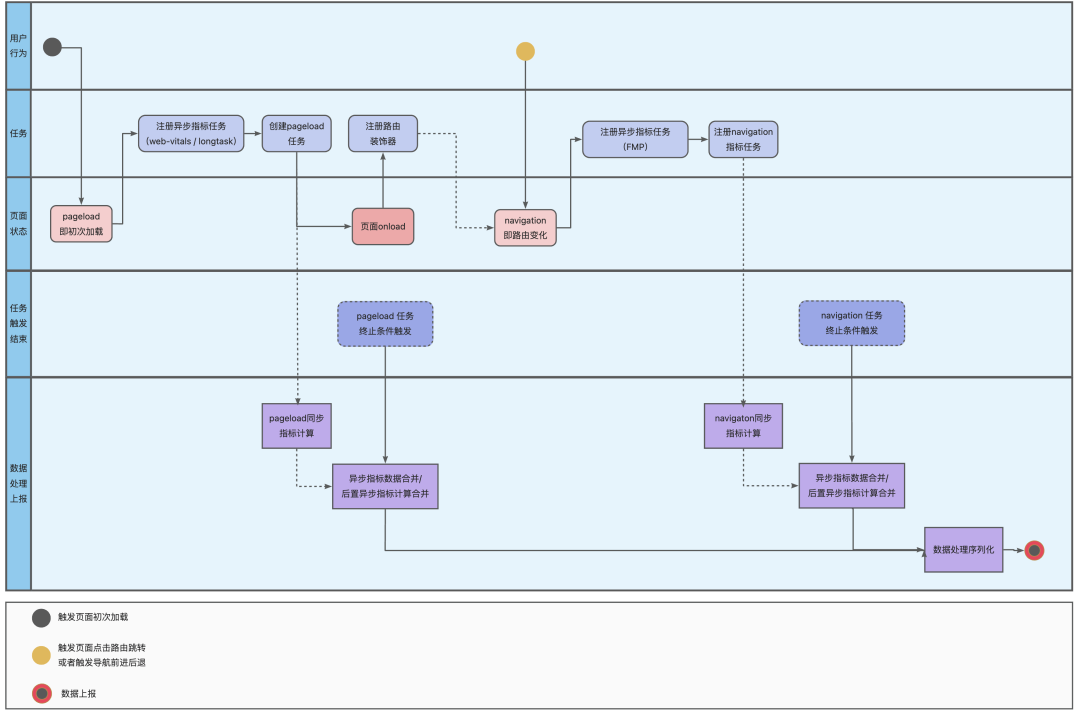
在进行数据上报时,如果页面的静态资源加载 / ajax请求数量很多时,埋点上报请求接口的 body 会很大,导致请求耗时长而影响页面本身的性能。因此针对 body 过大的问题,对一些资源的统计做了序列化处理。
比如:单条静态资源的原始数据结构为:
const entry:PerformanceResourceTiming = {
"name": "https://xxx.zzz.com/yyy.css?v=5J1NDtbnnIr2Rc2SdhEMlMxD4l9Eydj88B31E7_NhS4",
"entryType": "resource",
"startTime": 1924.6000000238419,
"duration": 1400.5999999642372,
"initiatorType": "link",
"fetchStart": 1924.6000000238419,
"responseEnd": 3325.199999988079,
}序列化之后,将各个关键数据合并成一个字符串,即:
// 将 entries 分类,并把单个entry 进行字符串化后,再将所有 css entry 合并
const cssEntry:string = 'https://xxx.zzz.com/yyy.css|1924|1924|3325'可以发现系列化精简后将 255个字符优化成了 42 个字符。
往往B端 SPA 项目静态资源和请求多达几十上百个,这样序列化处理合并之后,能将埋点上报请求 body 体积减少数千个字节。当然了,如果服务支持编解码,还可以通过其他更优的序列化方案进行 body 体积压缩。
在对数据进行处理时,也遇到了一些问题。
每天上报的性能埋点数据存储在哪里?
如何计算数据?如何扩展数据?如何查询数据?
二次计算后的数据量依旧非常大,该怎么办?
为了解决数据处理中的两个核心问题,我们采用了这个完整的流程。在面对如此庞大的数据时,我们需要考虑它们存储在何处。同时,我们也需要考虑如何查找和计算需要的指标。这个流程可以帮助我们更好地处理数据,提高效率。
此外,这个流程还有一个重要的作用,那就是保证数据的准确性和完整性。在数据处理过程中,我们需要遵循一定的规则和标准,以确保数据的可靠性。这样才能让我们在分析数据时得出正确的结论,更好的进行针对性的优化。
web平台部分功能页面展示如下:
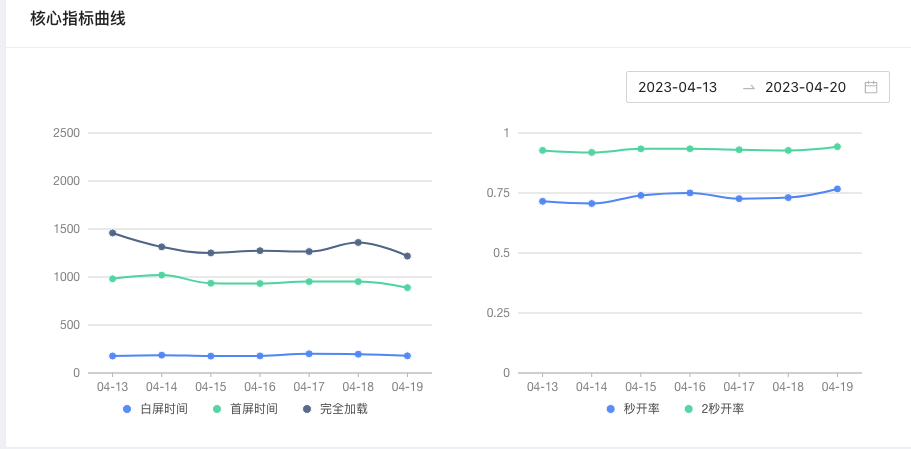
历史变化曲线
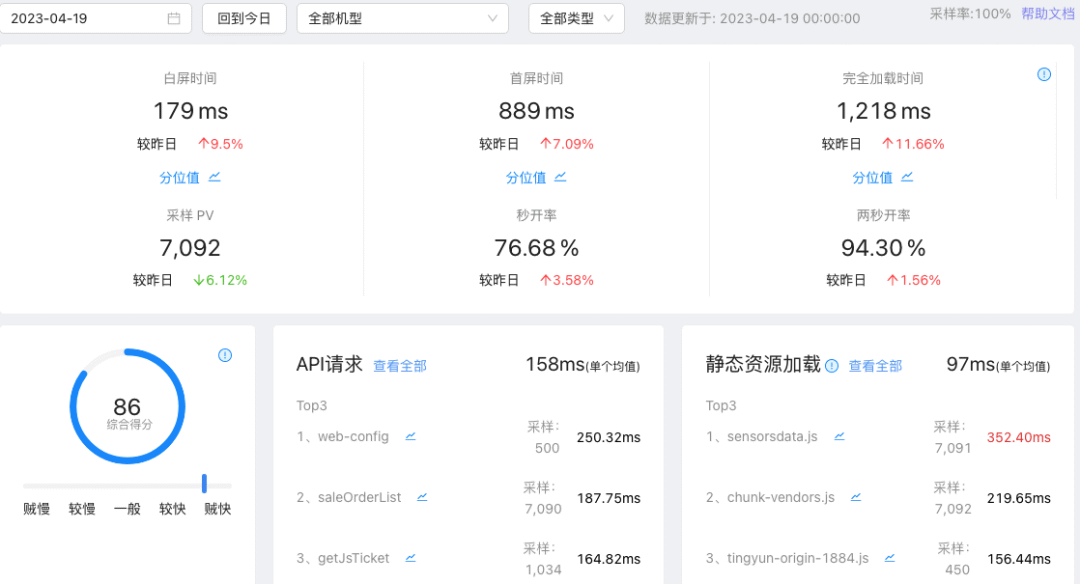
性能数据查询
在B端项目中,页面性能统计是非常有必要的,因为可以帮助我们了解实际用户的具体页面的加载速度、用户体验,以便了解当前页面的质量,并且为优化页面性能提供方向,从而提高用户满意度。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
require'mechanize'agent=Mechanize.newlogin=agent.get('http://www.schoolnet.ch/DE/HomeDE.htm')agent.clicklogin.link_withtext:/Login/然后我得到Mechanize::UnsupportedSchemeError。 最佳答案 Mechanize不支持javascript但您可以将搜索字段添加到表单并为其分配搜索词并使用mechanize提交表单form=page.forms.firstform.add_fie
我正在尝试创建一个带有项目符号字符的Ruby1.9.3字符串。str="•"+"helloworld"但是,当我输入它时,我收到有关非ASCII字符的语法错误。我该怎么做? 最佳答案 你可以把Unicode字符放在那里。str="\u2022"+"helloworld" 关于ruby-如何在Ruby字符串中插入项目符号字符?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1195