好难为了看到这个页面
ChatGLM-6B 是基于清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同训练的语言模型开发的一个开源的类 ChatGPT 模型,
ChatGLM(alpha内测版:QAGLM)是一个初具问答和对话功能的中英双语模型,当前仅针对中文优化,多轮和逻辑能力相对有限,但其仍在持续迭代进化过程中,敬请期待模型涌现新能力。中英双语对话 GLM 模型: ChatGLM-6B,结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。经过约 1T 标识符的中英双语训练,辅以监督微调、 反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 虽然规模不及千亿模型,但大大降低了用户部署的门槛,并且已经能生成相当符合人类偏好的回答。
ChatGLM-6B 是一个具有62亿参数的中英双语语言模型。通过使用与 ChatGLM(chatglm.cn)相同的技术,ChatGLM-6B 初具中文问答和对话功能,并支持在单张 2080Ti 上进行推理使用。具体来说,ChatGLM-6B 有如下特点:
充分的中英双语预训练: ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
优化的模型架构和大小: 吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统FFN结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
参数精度 | 占用显存 | 代码 |
FP16 | 13GB | .half().cuda() |
INT8 | 10GB | .half().quantize(8).cuda() |
INT4 | 6GB | .half().quantize(4).cuda() |
更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
人类意图对齐训练: 使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
因此,ChatGLM-6B 具备了一定条件下较好的对话与问答能力。当然,ChatGLM-6B 也有相当多已知的局限和不足。第一,模型容量较小:6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;她也不擅长逻辑类问题(如数学、编程)的解答。第二,可能会产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。第三,较弱的多轮对话能力:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成,以及多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。
torch 版本 要>=1.12.0
安装 icetk 冲突,安装 icetk 依赖 cpu版torch 2.0 ,解决办法迂回 先装 icetk,在安装GPU版torch.
3.transformers>= 4.23.1 推荐 transformers==4.26.1
新建文件夹 'THUDM'->'chatglm-6b'两个文件夹 把下载内容全部放里面,chatglm-6b
安装先装 icetk,在安装GPU版torch.
pip install protobuf==3.20.0 transformers==4.26.1 icetk cpm_kernels -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com在安装GPU版torch.这里我是用浏览器下载的 torch GPU whl包在本地安装
pip install torch-1.13.1+cu117-cp310-cp310-win_amd64.whl -i https://download.pytorch.org/whl/torch/ --trusted-host download.pytorch.org
import os
from transformers import AutoTokenizer, AutoModel
# 获取当前文件所在的目录路径
current_dir = os.path.dirname(os.path.abspath(__file__))
# 将当前目录和'model'连接起来,获得'model'文件夹的完整路径
model_path = os.path.join(current_dir, 'THUDM','chatglm-6b')
# 确认路径是否正确
print(model_path)
print(model_path)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().quantize(4).cuda() # 这里进行了int4量化。
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
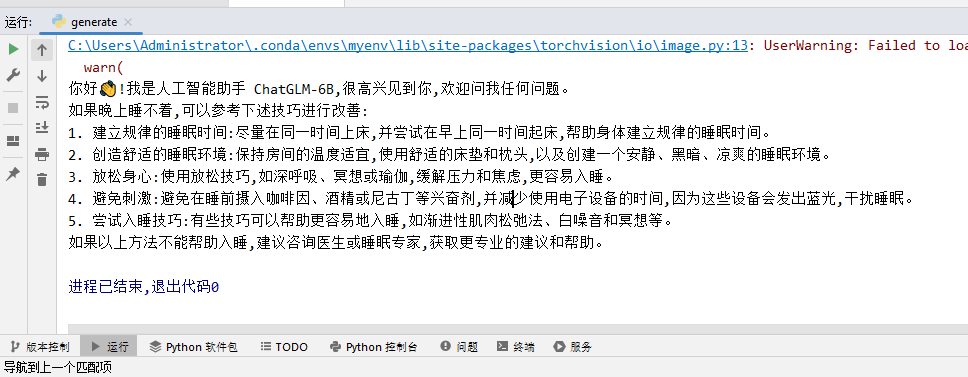
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
'''
trust_remote_code=False 的意思是,即使在本地目录中没有找到分词器和模型文件,也不会从远程存储库下载它们。如果找不到这些文件,会抛出错误。因此,将trust_remote_code设置为False可以确保从本地路径加载模型和分词器。
在 PyTorch 中,half() 是将张量数据类型转换为 16 位浮点型(即半精度浮点型)的方法。半精度浮点型比单精度浮点型占用更少的内存空间,但相应的精度也会受到一定的影响。
在给定模型的情况下,将模型的参数和计算结果使用半精度浮点型进行存储和计算可以显著减少 GPU 内存的使用,从而允许更大的 batch size 和更深的网络结构,加速训练过程。但需要注意的是,在某些场景下,使用半精度浮点型可能会降低模型的精度和收敛速度,因此需要根据具体情况进行权衡和选择。
'''
欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序
用户: 7年前,妈妈的年龄是儿子的6倍,儿子今年12岁,妈妈今年几岁?
ChatGLM-6B:7年前儿子的年龄是 $12-7=5$ 岁,那时妈妈的年龄是 $5 \times 6 = 30$ 岁。
现在,7年过去了,妈妈的年龄应该是 $30+7=37$ 岁,因此,可以得出结论:妈妈今年37岁。
用户: numbers由几个字母组成
ChatGLM-6B:"numbers" 由三个字母组成。
用户: 小明45元卖出一顶帽子,收到一张100元假钞,找零55元,帽子进货价15元一顶,如果小明不知道他收到的是一张假钞,请问小明亏了多少钱?
ChatGLM-6B:小明的利润是 $45 - 100 = -55$ 元。
小明收到了一张假钞,导致他实际支付的金额为 $100 - 55 = 45$ 元,但找零只有 $55$ 元,因此小明实际损失了 $45 - 55 = -10$ 元。
因此,小明亏了 $-10$ 元。
用户: 32+9.4=
ChatGLM-6B:32+9.4=41.4
用户: 有一串彩珠,按2红3绿4黄的顺序依次排列,第600颗是什么颜色?
ChatGLM-6B:这串彩珠按照2红3绿4黄的顺序排列,总共有2+3+4=9颗珠子。
要找到第600颗珠子的颜色,我们可以计算出前600颗珠子中红、绿、黄三种颜色各有多少颗珠子。
首先,计算前600颗珠子中红颜色有多少颗:2颗珠子/颗彩珠(2红3绿4黄)=2/3(红+绿+黄)。
因此,前600颗珠子中红颜色有 $2/3 \times 600 = 400$ 颗珠子。
接下来,计算前600颗珠子中绿颜色有多少颗:3颗珠子/颗彩珠(2红3绿4黄)=3/4(红+绿+黄)。
因此,前600颗珠子中绿颜色有 $3/4 \times 600 = 900$ 颗珠子。
最后,计算前600颗珠子中黄色有多少颗:4颗珠子/颗彩珠(2红3绿4黄)=4/5(红+绿+黄)。
因此,前600颗珠子中黄色有 $4/5 \times 600 = 800$ 颗珠子。
所以,第600颗珠子的颜色是黄色。
用户: 用python语言Pillow库画一幅自然风景的图的代码
ChatGLM-6B:以下是使用Python的Pillow库绘制自然风景图的示例代码:
```python
import PIL
# 初始化Pillow库
PIL = PIL.init()
# 导入绘图函数
def draw(size, canvas, fill, color):
for x in range(size[0], size[1]):
for y in range(size[0], size[1]):
# 获取像素值
像素值 = (x * 256) + (y * 256)
# 绘制像素值
canvas.draw(像素值, fill=fill, color=color)
# 设置绘图尺寸
size = (400, 400)
# 绘制自然风景图
draw(size, canvas, fill='green', color='red')
draw(size, canvas, fill='yellow', color='blue')
draw(size, canvas, fill='orange', color='black')
# 保存绘图结果
canvas.tostring(size, format='png')
```
运行这段代码会提示选择输出文件格式(png、jpg等),选择保存路径并输出绘图结果。您可以根据自己的喜好选择不同的输出格式和保存路径。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
Ruby是否有逐步调试器,类似于Perl的“perl-d”? 最佳答案 ruby-debug(对于ruby1.8),debugger(对于ruby1.9),byebug(对于ruby2.0)以及trepanning系列都有一个-x或--trace选项。在调试器内部,命令setlinetrace将打开或关闭线路跟踪。这是themanualforruby-debug原来的答案已经修改,因为数据噪声文章的链接,唉,不再有效了。还添加了ruby-debug的后继者 关于ruby-Ruby
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
假设您在Ruby中执行此操作:ar=[1,2]x,y=ar然后,x==1和y==2。是否有一种方法可以在我自己的类中定义,从而产生相同的效果?例如rb=AllYourCode.newx,y=rb到目前为止,对于这样的赋值,我所能做的就是使x==rb和y=nil。Python有这样一个特性:>>>classFoo:...def__iter__(self):...returniter([1,2])...>>>x,y=Foo()>>>x1>>>y2 最佳答案 是的。定义#to_ary。这将使您的对象被视为要分配的数组。irb>o=Obje
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
我使用Jekyll运行博客,并认为我会解决RedcarpetMarkdown解释器,因为它是developedandusedbyGitHub.好吧,我只是碰巧遇到了一个错误,去检查问题,然后foundthis.Maintainersays,"Asyouprobablyhavenoticed(harharharhar)Idon'thavetimetomaintainRedcarpetanymore.It'snotapriorityforme(IfindMarkdownthoroughlyboring)andit'snotapriorityforGitHub,becausewenolong
关于如何使用git设置类似Dropbox的服务,您有什么建议吗?您认为git是解决此问题的合适工具吗?我在考虑使用git+rush解决方案,你觉得怎么样? 最佳答案 检查这个开源项目:https://github.com/hbons/SparkleShare来自项目的自述文件:Howdoesitwork?SparkleSharecreatesaspecialfolderonyourcomputer.Youcanaddremotelyhostedfolders(or"projects")tothisfolder.Theseprojec