文章目录
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
LeNet模型是在1998年提出的一种图像分类模型,应用于支票或邮件编码上的手写数字的识别,也被认为是最早的卷积神经网络(CNN),为后续CNN的发展奠定了基础,作者LeCun Y也被誉为卷积神经网络之父。LeNet之后一直直到2012年的AlexNet模型在ImageNet比赛上表现优秀,使得沉寂了14年的卷积神经网络再次成为研究热点。
LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
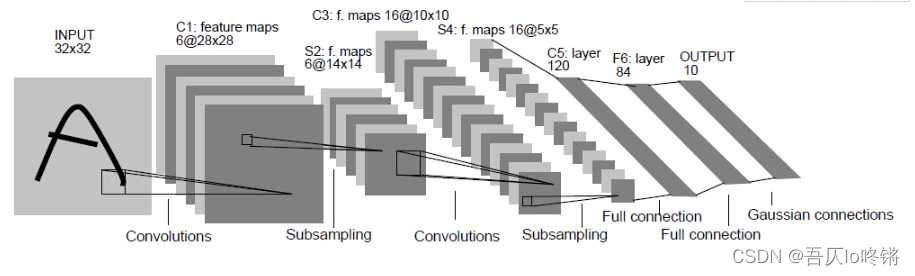
LeNet模型结构如下:
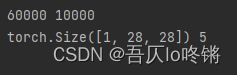
使用torchversion内置的MNIST数据集,训练集大小60000,测试集大小10000,图像大小是1×28×28,包括数字0~9共10个类。官网:http://yann.lecun.com/exdb/mnist/
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import torchvision
mnist_train = torchvision.datasets.MNIST(root='./datasets/',
train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.MNIST(root='./datasets/',
train=False, download=True, transform=transforms.ToTensor())
print(len(mnist_train), len(mnist_test)) # 打印训练/测试集大小
feature, label = mnist_train[0]
print(feature.shape, label) # 打印图像大小和标签
dataloader = DataLoader(mnist_test, batch_size=64, num_workers=0) # 每次批量加载64张
step = 0
writer = SummaryWriter(log_dir='runs/mnist') # 可视化
for data in dataloader:
features, labels = data
writer.add_images(tag='train', img_tensor=features, global_step=step)
step += 1
writer.close()
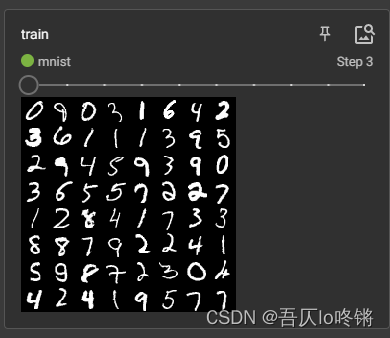
可视化部分可参考我这篇博客:深度学习-Tensorboard可视化面板
此外,还可以使用torchversion内置的FashionMNIST数据集,包括衣服、包等10类图像,也是1×28×28,各60000、10000张。
使用Pytoch进行搭建和测试。
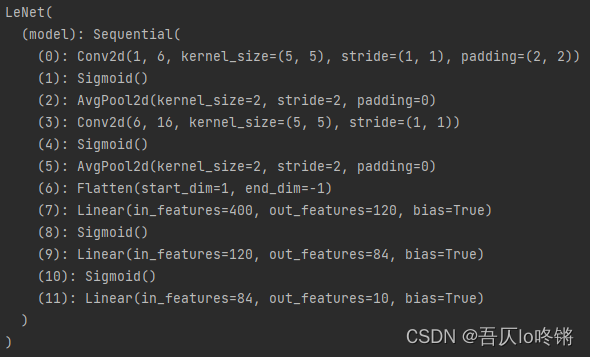
在第一个卷积层C1设置padding为2,因为数据集是28×28大小,原模型是32×32大小。
import torch
from torch import nn, optim
class LeNet(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model = nn.Sequential( # (-1,1,28,28)
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2), # (-1,6,28,28)
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), # (-1,6,14,14)
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5), # (-1,16,10,10)
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), # (-1,16,5,5)
nn.Flatten(),
nn.Linear(in_features=16 * 5 * 5, out_features=120), # (-1,120)
nn.Sigmoid(),
nn.Linear(120, 84), # (-1,84)
nn.Sigmoid(),
nn.Linear(in_features=84, out_features=10) # (-1,10)
)
def forward(self, x):
return self.model(x)
leNet = LeNet()
print(leNet)
import torch
import torchvision
from torch.utils.data import DataLoader
from torchvision import transforms
from torch import nn
from torch.utils.tensorboard import SummaryWriter
class LeNet(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model = nn.Sequential( # (-1,1,28,28)
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2), # (-1,6,28,28)
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), # (-1,6,14,14)
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5), # (-1,16,10,10)
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), # (-1,16,5,5)
nn.Flatten(),
nn.Linear(in_features=16 * 5 * 5, out_features=120), # (-1,120)
nn.Sigmoid(),
nn.Linear(120, 84), # (-1,84)
nn.Sigmoid(),
nn.Linear(in_features=84, out_features=10) # (-1,10)
)
def forward(self, x):
return self.model(x)
# 创建模型
leNet = LeNet()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
leNet = leNet.to(device) # 若支持GPU加速
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.Adam(leNet.parameters(), lr=learning_rate)
total_train_step = 0 # 总训练次数
epoch = 10 # 训练轮数
writer = SummaryWriter(log_dir='./runs/LeNet/')
# 数据
mnist_train = torchvision.datasets.MNIST(root='./datasets/',
train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.MNIST(root='./datasets/',
train=False, download=True, transform=transforms.ToTensor())
dataloader_train = DataLoader(mnist_train, batch_size=64, num_workers=0) # 每次批量加载64张
dataloader_test = DataLoader(mnist_test, batch_size=64, num_workers=0) # 每次批量加载64张
for i in range(epoch):
print("-----第{}轮训练开始-----".format(i + 1))
leNet.train() # 训练模式
train_loss = 0
for data in dataloader_train:
imgs, labels = data
imgs = imgs.to(device) # 适配GPU/CPU
labels = labels.to(device)
outputs = leNet(imgs)
loss = loss_fn(outputs, labels)
optimizer.zero_grad() # 清空之前梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
total_train_step += 1 # 更新步数
train_loss += loss.item()
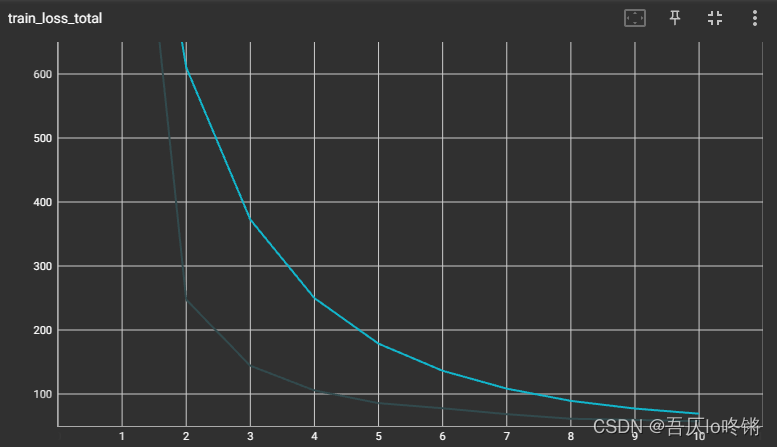
writer.add_scalar("train_loss_detail", loss.item(), total_train_step)
writer.add_scalar("train_loss_total", train_loss, i + 1)
torch.save(leNet, "./models/LeNet.pkl") # 保存模型
#leNet = torch.load("./models/LeNet") 加载模型
writer.close()
(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/
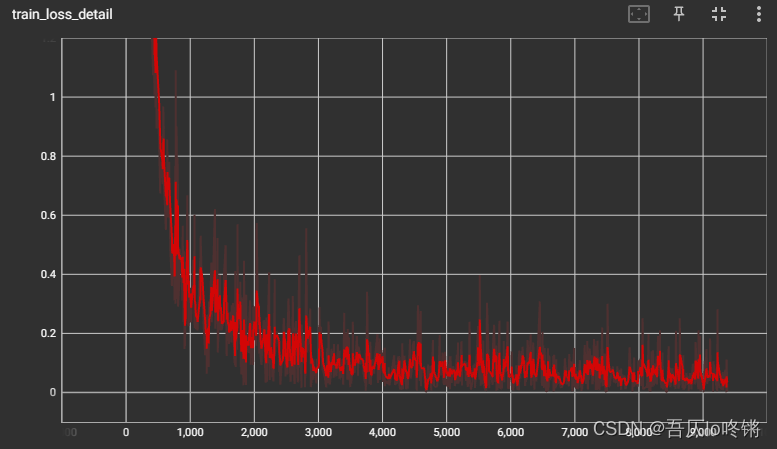
由于打印了每轮各个批次64张图的损失,不同批次损失不同,所以上下震荡大,但总体仍是减少收敛的。
leNet.eval() # 测试模式
total_test_loss = 0 # 当前轮次模型测试所得损失
total_accuracy = 0 # 当前轮次精确率
with torch.no_grad(): # 关闭梯度反向传播
for data in dataloader_test:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = leNet(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
writer.add_scalar("test_loss", total_test_loss, i+1)
writer.add_scalar("test_accuracy", total_accuracy/len(mnist_test), i+1)
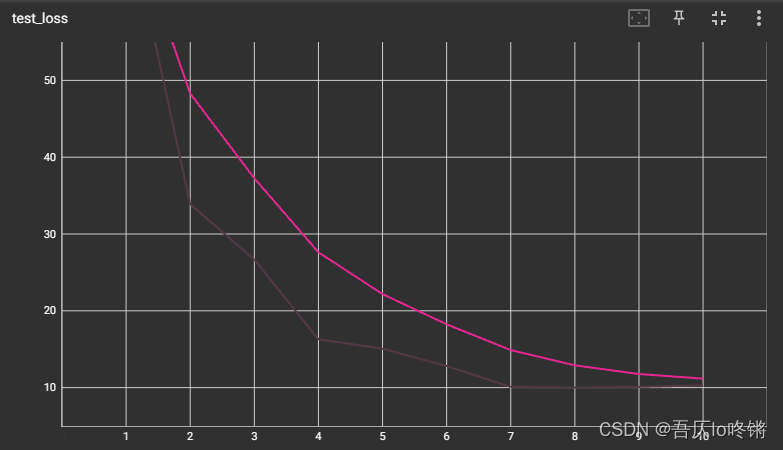
随着训练轮数增加,对应模型测试的损失减少并收敛。
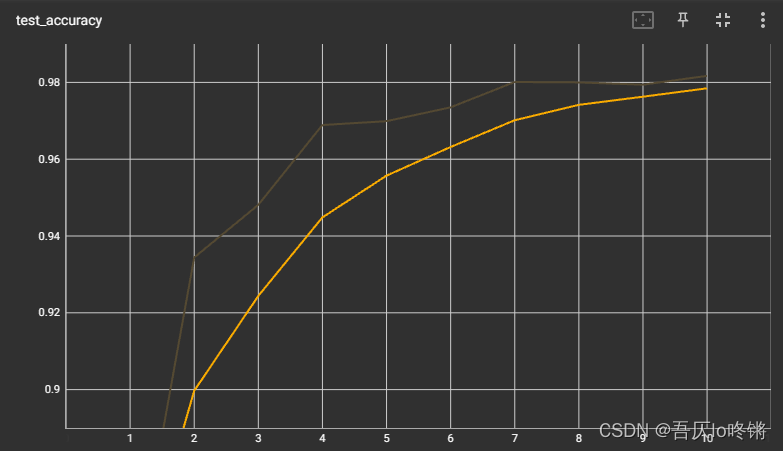
精确率在几轮后就趋于98%以上,就是说感受到了来自98年的科技~
最后,附完整代码:
import torch
import torchvision
from torch.utils.data import DataLoader
from torchvision import transforms
from torch import nn
from torch.utils.tensorboard import SummaryWriter
class LeNet(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model = nn.Sequential( # (-1,1,28,28)
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2), # (-1,6,28,28)
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), # (-1,6,14,14)
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5), # (-1,16,10,10)
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), # (-1,16,5,5)
nn.Flatten(),
nn.Linear(in_features=16 * 5 * 5, out_features=120), # (-1,120)
nn.Sigmoid(),
nn.Linear(120, 84), # (-1,84)
nn.Sigmoid(),
nn.Linear(in_features=84, out_features=10) # (-1,10)
)
def forward(self, x):
return self.model(x)
# 创建模型
leNet = LeNet()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
leNet = leNet.to(device) # 若支持GPU加速
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.Adam(leNet.parameters(), lr=learning_rate)
total_train_step = 0 # 总训练次数
epoch = 10 # 训练轮数
writer = SummaryWriter(log_dir='./runs/LeNet/')
# 数据
mnist_train = torchvision.datasets.MNIST(root='./datasets/',
train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.MNIST(root='./datasets/',
train=False, download=True, transform=transforms.ToTensor())
dataloader_train = DataLoader(mnist_train, batch_size=64, num_workers=0) # 每次批量加载64张
dataloader_test = DataLoader(mnist_test, batch_size=64, num_workers=0) # 每次批量加载64张
for i in range(epoch):
print("-----第{}轮训练开始-----".format(i + 1))
leNet.train() # 训练模式
train_loss = 0
for data in dataloader_train:
imgs, labels = data
imgs = imgs.to(device) # 适配GPU/CPU
labels = labels.to(device)
outputs = leNet(imgs)
loss = loss_fn(outputs, labels)
optimizer.zero_grad() # 清空之前梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
total_train_step += 1 # 更新步数
train_loss += loss.item()
writer.add_scalar("train_loss", loss.item(), total_train_step)
writer.add_scalar("train_loss", train_loss, i + 1)
leNet.eval() # 测试模式
total_test_loss = 0 # 当前轮次模型测试所得损失
total_accuracy = 0 # 当前轮次精确率
with torch.no_grad(): # 关闭梯度反向传播
for data in dataloader_test:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = leNet(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
writer.add_scalar("test_loss", total_test_loss, i+1)
writer.add_scalar("test_accuracy", total_accuracy/len(mnist_test), i+1)
torch.save(leNet, "./models/LeNet.pkl") # 保存模型
#leNet = torch.load("./models/LeNet") 加载模型
writer.close()
原创不易,请勿转载(
本不富裕的访问量雪上加霜)
博主首页:https://wzlodq.blog.csdn.net/
来都来了,不评论两句吗👀
如果文章对你有帮助,记得一键三连❤
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir
我的问题的一个例子是体育游戏。一场体育比赛有两支球队,一支主队和一支客队。我的事件记录模型如下:classTeam"Team"has_one:away_team,:class_name=>"Team"end我希望能够通过游戏访问一个团队,例如:Game.find(1).home_team但我收到一个单元化常量错误:Game::team。谁能告诉我我做错了什么?谢谢, 最佳答案 如果Gamehas_one:team那么Rails假设您的teams表有一个game_id列。不过,您想要的是games表有一个team_id列,在这种情况下
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称