目录
想必有小伙伴也想跟我一样体验下部署大语言模型, 但碍于经济实力, 不过民间上出现了大量的量化模型, 我们平民也能体验体验啦~, 该模型可以在笔记本电脑上部署, 确保你电脑至少有16G运行内存
开原地址:GitHub - ymcui/Chinese-LLaMA-Alpaca: 中文LLaMA&Alpaca大语言模型+本地CPU部署 (Chinese LLaMA & Alpaca LLMs)
Linux和Mac的教程在开源的仓库中有提供,当然如果你是M1的也可以参考以下文章:
https://gist.github.com/cedrickchee/e8d4cb0c4b1df6cc47ce8b18457ebde0
最好是有代理, 不然你下载东西可能失败, 我为了下个模型花了一天时间, 痛哭~
我们需要先在电脑上安装以下环境:
下载地址:Git - Downloading Package

下载好安装包后打开, 一直点下一步安装即可...
在cmd窗口输入以下如果有版本号显示说明已经安装成功
git -v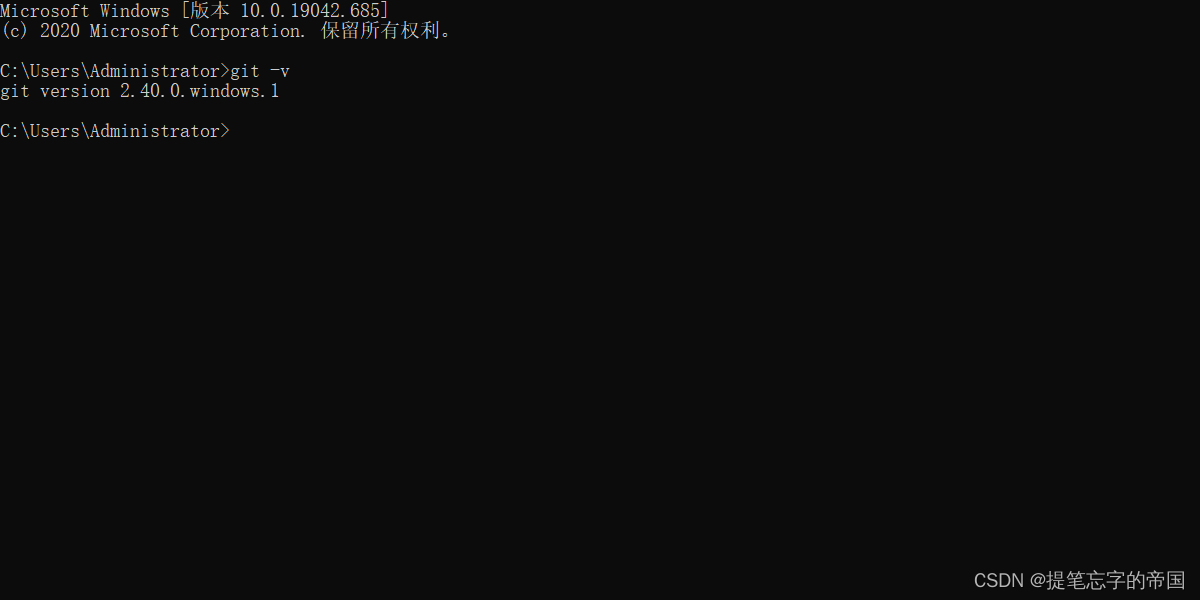
我这里使用Anaconda3来使用Python, Anaconda3是什么?
如果你熟悉docker, 那么你可以把docker的概念带过来, docker可以创建很多个容器, 每个容器的环境可能一样也可能不一样, Anaconda3也是一样的, 它可以创建很多个不同的Python版本, 互相不冲突, 想用哪个版本就切换到哪个版本...
Anaconda3下载地址:Anaconda | Anaconda Distribution
安装步骤参考:





等待安装好后一直点next, 直到点Finish关闭即可
在cmd窗口输入以下命令, 显示版本号则说明安装成功
conda -V
接下来我们在cmd窗口输入以下命令创建一个python3.9的环境
conda create --name py39 python=3.9 -y--name后面的py39是环境名字, 可以自己任意起, 切换环境的时候需要它
python=3.9是指定python版本
添加-y后就不需要手动输入y去确认安装了

查看有哪些环境的命令:
conda info -e
激活/切换环境的命令:
conda activate py39要使用哪个环境的话换成对应名字即可

进入环境后你就可以在这输入python相关的命令了, 如:

要退出环境的话输入:
conda deactivate当我退出环境后再查看python版本的话会提示我不是内部或外部命令,也不是可运行的程序
或批处理文件。如:

这是一个编译工具, 我们需要使用它去编译llama.cpp, 量化模型需要用到, 不量化模型个人电脑跑不起来, 觉得量化这个概念不理解的可以理解为压缩, 这种概念是不对的, 只是为了帮助你更好的理解.
在安装之前我们需要安装mingw, 避免编译时找不到编译环境, 按下win+r快捷键输入powershell
输入命令安装scoop, 这是一个包管理器, 我们使用它来下载安装mingw:
iex "& {$(irm get.scoop.sh)} -RunAsAdmin"安装好后分别运行下面两个命令(添加库):
scoop bucket add extrasscoop bucket add main输入命令安装mingw
scoop install mingw到这就已经安装好mingw了, 如果报错了请评论, 我看到了会回复
接下来安装Cmake
安装参考:



安装好后点Finish即可
我们需要下载两个模型, 一个是原版的LLaMA模型, 一个是扩充了中文的模型, 后续会进行一个合并模型的操作
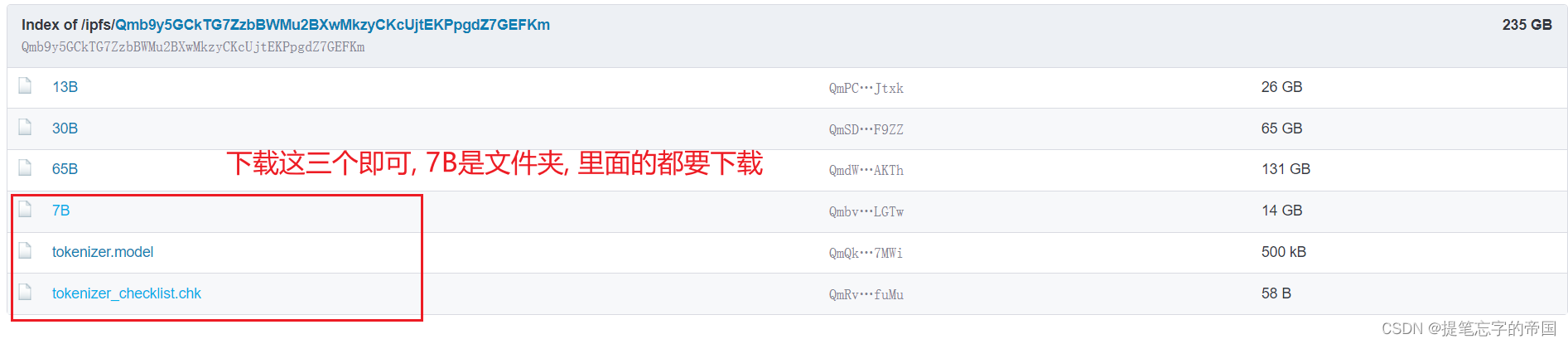
建议在D盘上新建一个文件夹, 在里面进行下载操作, 如下:
在弹出的框中分别输入以下命令:
git lfs installgit clone https://huggingface.co/ziqingyang/chinese-alpaca-lora-7b这里可能会因为网络问题一直失败......一直重试就行, 有别的问题请评论, 看到会回复
终于写到这里了, 累~
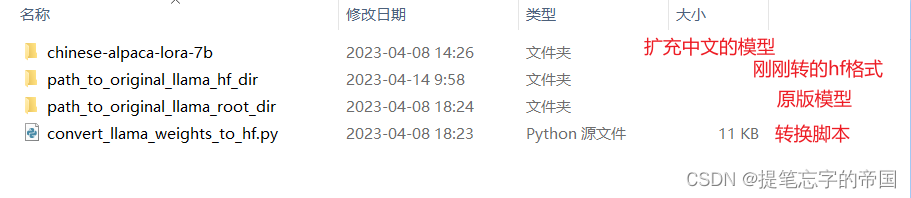
在你下载了模型的目录内打开cmd窗口, 如下:

这里我先说下这图片中的两个目录里文件是啥吧
先是chinese-alpaca-lora-7b目录, 这个目录一般你下载下来就不用动了, 格式如下:
chinese-alpaca-lora-7b/
- adapter_config.json
- adapter_model.bin
- special_tokens_map.json
- tokenizer_config.json
- tokenizer.model
然后是path_to_original_llama_root_dir目录, 这个文件夹需要创建, 保持一致的文件名, 目录内的格式如下:
path_to_original_llama_root_dir/
- 7B/ #这是一个名为7B的文件夹
- checklist.chk
- consolidated.00.pth
- params.json
- tokenizer_checklist.chk
- tokenizer.model
自行按照上面的格式存放
打开窗口后需要先激活python环境, 使用的就是前面装Anaconda3
# 不记得有哪些环境的先运行以下命令
conda info -e
# 然后激活你需要的环境 我的环境名是py39
conda activate py39切换好后分别执行以下命令安装依赖库
pip install git+https://github.com/huggingface/transformers
pip install sentencepiece==0.1.97
pip install peft==0.2.0执行命令安装成功后会有Successfully的字眼
接下来需要将原版模型转HF格式, 需要借助最新版🤗transformers提供的脚本convert_llama_weights_to_hf.py
在目录内新建一个convert_llama_weights_to_hf.py文件, 用记事本打开后把以下代码粘贴进去
注意:我这里是为了方便直接拷贝出来了,脚本可能会更新,建议直接去以下地址拷贝最新的:
transformers/convert_llama_weights_to_hf.py at main · huggingface/transformers · GitHub
# Copyright 2022 EleutherAI and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import gc
import json
import math
import os
import shutil
import warnings
import torch
from transformers import LlamaConfig, LlamaForCausalLM, LlamaTokenizer
try:
from transformers import LlamaTokenizerFast
except ImportError as e:
warnings.warn(e)
warnings.warn(
"The converted tokenizer will be the `slow` tokenizer. To use the fast, update your `tokenizers` library and re-run the tokenizer conversion"
)
LlamaTokenizerFast = None
"""
Sample usage:
```
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
```
Thereafter, models can be loaded via:
```py
from transformers import LlamaForCausalLM, LlamaTokenizer
model = LlamaForCausalLM.from_pretrained("/output/path")
tokenizer = LlamaTokenizer.from_pretrained("/output/path")
```
Important note: you need to be able to host the whole model in RAM to execute this script (even if the biggest versions
come in several checkpoints they each contain a part of each weight of the model, so we need to load them all in RAM).
"""
INTERMEDIATE_SIZE_MAP = {
"7B": 11008,
"13B": 13824,
"30B": 17920,
"65B": 22016,
}
NUM_SHARDS = {
"7B": 1,
"13B": 2,
"30B": 4,
"65B": 8,
}
def compute_intermediate_size(n):
return int(math.ceil(n * 8 / 3) + 255) // 256 * 256
def read_json(path):
with open(path, "r") as f:
return json.load(f)
def write_json(text, path):
with open(path, "w") as f:
json.dump(text, f)
def write_model(model_path, input_base_path, model_size):
os.makedirs(model_path, exist_ok=True)
tmp_model_path = os.path.join(model_path, "tmp")
os.makedirs(tmp_model_path, exist_ok=True)
params = read_json(os.path.join(input_base_path, "params.json"))
num_shards = NUM_SHARDS[model_size]
n_layers = params["n_layers"]
n_heads = params["n_heads"]
n_heads_per_shard = n_heads // num_shards
dim = params["dim"]
dims_per_head = dim // n_heads
base = 10000.0
inv_freq = 1.0 / (base ** (torch.arange(0, dims_per_head, 2).float() / dims_per_head))
# permute for sliced rotary
def permute(w):
return w.view(n_heads, dim // n_heads // 2, 2, dim).transpose(1, 2).reshape(dim, dim)
print(f"Fetching all parameters from the checkpoint at {input_base_path}.")
# Load weights
if model_size == "7B":
# Not shared
# (The sharded implementation would also work, but this is simpler.)
loaded = torch.load(os.path.join(input_base_path, "consolidated.00.pth"), map_location="cpu")
else:
# Sharded
loaded = [
torch.load(os.path.join(input_base_path, f"consolidated.{i:02d}.pth"), map_location="cpu")
for i in range(num_shards)
]
param_count = 0
index_dict = {"weight_map": {}}
for layer_i in range(n_layers):
filename = f"pytorch_model-{layer_i + 1}-of-{n_layers + 1}.bin"
if model_size == "7B":
# Unsharded
state_dict = {
f"model.layers.{layer_i}.self_attn.q_proj.weight": permute(
loaded[f"layers.{layer_i}.attention.wq.weight"]
),
f"model.layers.{layer_i}.self_attn.k_proj.weight": permute(
loaded[f"layers.{layer_i}.attention.wk.weight"]
),
f"model.layers.{layer_i}.self_attn.v_proj.weight": loaded[f"layers.{layer_i}.attention.wv.weight"],
f"model.layers.{layer_i}.self_attn.o_proj.weight": loaded[f"layers.{layer_i}.attention.wo.weight"],
f"model.layers.{layer_i}.mlp.gate_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w1.weight"],
f"model.layers.{layer_i}.mlp.down_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w2.weight"],
f"model.layers.{layer_i}.mlp.up_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w3.weight"],
f"model.layers.{layer_i}.input_layernorm.weight": loaded[f"layers.{layer_i}.attention_norm.weight"],
f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[f"layers.{layer_i}.ffn_norm.weight"],
}
else:
# Sharded
# Note that in the 13B checkpoint, not cloning the two following weights will result in the checkpoint
# becoming 37GB instead of 26GB for some reason.
state_dict = {
f"model.layers.{layer_i}.input_layernorm.weight": loaded[0][
f"layers.{layer_i}.attention_norm.weight"
].clone(),
f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[0][
f"layers.{layer_i}.ffn_norm.weight"
].clone(),
}
state_dict[f"model.layers.{layer_i}.self_attn.q_proj.weight"] = permute(
torch.cat(
[
loaded[i][f"layers.{layer_i}.attention.wq.weight"].view(n_heads_per_shard, dims_per_head, dim)
for i in range(num_shards)
],
dim=0,
).reshape(dim, dim)
)
state_dict[f"model.layers.{layer_i}.self_attn.k_proj.weight"] = permute(
torch.cat(
[
loaded[i][f"layers.{layer_i}.attention.wk.weight"].view(n_heads_per_shard, dims_per_head, dim)
for i in range(num_shards)
],
dim=0,
).reshape(dim, dim)
)
state_dict[f"model.layers.{layer_i}.self_attn.v_proj.weight"] = torch.cat(
[
loaded[i][f"layers.{layer_i}.attention.wv.weight"].view(n_heads_per_shard, dims_per_head, dim)
for i in range(num_shards)
],
dim=0,
).reshape(dim, dim)
state_dict[f"model.layers.{layer_i}.self_attn.o_proj.weight"] = torch.cat(
[loaded[i][f"layers.{layer_i}.attention.wo.weight"] for i in range(num_shards)], dim=1
)
state_dict[f"model.layers.{layer_i}.mlp.gate_proj.weight"] = torch.cat(
[loaded[i][f"layers.{layer_i}.feed_forward.w1.weight"] for i in range(num_shards)], dim=0
)
state_dict[f"model.layers.{layer_i}.mlp.down_proj.weight"] = torch.cat(
[loaded[i][f"layers.{layer_i}.feed_forward.w2.weight"] for i in range(num_shards)], dim=1
)
state_dict[f"model.layers.{layer_i}.mlp.up_proj.weight"] = torch.cat(
[loaded[i][f"layers.{layer_i}.feed_forward.w3.weight"] for i in range(num_shards)], dim=0
)
state_dict[f"model.layers.{layer_i}.self_attn.rotary_emb.inv_freq"] = inv_freq
for k, v in state_dict.items():
index_dict["weight_map"][k] = filename
param_count += v.numel()
torch.save(state_dict, os.path.join(tmp_model_path, filename))
filename = f"pytorch_model-{n_layers + 1}-of-{n_layers + 1}.bin"
if model_size == "7B":
# Unsharded
state_dict = {
"model.embed_tokens.weight": loaded["tok_embeddings.weight"],
"model.norm.weight": loaded["norm.weight"],
"lm_head.weight": loaded["output.weight"],
}
else:
state_dict = {
"model.norm.weight": loaded[0]["norm.weight"],
"model.embed_tokens.weight": torch.cat(
[loaded[i]["tok_embeddings.weight"] for i in range(num_shards)], dim=1
),
"lm_head.weight": torch.cat([loaded[i]["output.weight"] for i in range(num_shards)], dim=0),
}
for k, v in state_dict.items():
index_dict["weight_map"][k] = filename
param_count += v.numel()
torch.save(state_dict, os.path.join(tmp_model_path, filename))
# Write configs
index_dict["metadata"] = {"total_size": param_count * 2}
write_json(index_dict, os.path.join(tmp_model_path, "pytorch_model.bin.index.json"))
config = LlamaConfig(
hidden_size=dim,
intermediate_size=compute_intermediate_size(dim),
num_attention_heads=params["n_heads"],
num_hidden_layers=params["n_layers"],
rms_norm_eps=params["norm_eps"],
)
config.save_pretrained(tmp_model_path)
# Make space so we can load the model properly now.
del state_dict
del loaded
gc.collect()
print("Loading the checkpoint in a Llama model.")
model = LlamaForCausalLM.from_pretrained(tmp_model_path, torch_dtype=torch.float16, low_cpu_mem_usage=True)
# Avoid saving this as part of the config.
del model.config._name_or_path
print("Saving in the Transformers format.")
model.save_pretrained(model_path)
shutil.rmtree(tmp_model_path)
def write_tokenizer(tokenizer_path, input_tokenizer_path):
# Initialize the tokenizer based on the `spm` model
tokenizer_class = LlamaTokenizer if LlamaTokenizerFast is None else LlamaTokenizerFast
print("Saving a {tokenizer_class} to {tokenizer_path}")
tokenizer = tokenizer_class(input_tokenizer_path)
tokenizer.save_pretrained(tokenizer_path)
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"--input_dir",
help="Location of LLaMA weights, which contains tokenizer.model and model folders",
)
parser.add_argument(
"--model_size",
choices=["7B", "13B", "30B", "65B", "tokenizer_only"],
)
parser.add_argument(
"--output_dir",
help="Location to write HF model and tokenizer",
)
args = parser.parse_args()
if args.model_size != "tokenizer_only":
write_model(
model_path=args.output_dir,
input_base_path=os.path.join(args.input_dir, args.model_size),
model_size=args.model_size,
)
spm_path = os.path.join(args.input_dir, "tokenizer.model")
write_tokenizer(args.output_dir, spm_path)
if __name__ == "__main__":
main()在cmd窗口执行命令:
python convert_llama_weights_to_hf.py --input_dir path_to_original_llama_root_dir --model_size 7B --output_dir path_to_original_llama_hf_dir经过漫长的等待....
接下来合并输出PyTorch版本权重(.pth文件),使用merge_llama_with_chinese_lora.py脚本
在目录新建一个merge_llama_with_chinese_lora.py文件, 用记事本打开将以下代码粘贴进去
注意:我这里是为了方便直接拷贝出来了,脚本可能会更新,建议直接去以下地址拷贝最新的:
Chinese-LLaMA-Alpaca/merge_llama_with_chinese_lora.py at main · ymcui/Chinese-LLaMA-Alpaca · GitHub
"""
Borrowed and modified from https://github.com/tloen/alpaca-lora
"""
import argparse
import os
import json
import gc
import torch
import transformers
import peft
from peft import PeftModel
parser = argparse.ArgumentParser()
parser.add_argument('--base_model',default=None,required=True,type=str,help="Please specify a base_model")
parser.add_argument('--lora_model',default=None,required=True,type=str,help="Please specify a lora_model")
# deprecated; the script infers the model size from the checkpoint
parser.add_argument('--model_size',default='7B',type=str,help="Size of the LLaMA model",choices=['7B','13B'])
parser.add_argument('--offload_dir',default=None,type=str,help="(Optional) Please specify a temp folder for offloading (useful for low-RAM machines). Default None (disable offload).")
parser.add_argument('--output_dir',default='./',type=str)
args = parser.parse_args()
assert (
"LlamaTokenizer" in transformers._import_structure["models.llama"]
), "LLaMA is now in HuggingFace's main branch.\nPlease reinstall it: pip uninstall transformers && pip install git+https://github.com/huggingface/transformers.git"
from transformers import LlamaTokenizer, LlamaForCausalLM
BASE_MODEL = args.base_model
LORA_MODEL = args.lora_model
output_dir = args.output_dir
assert (
BASE_MODEL
), "Please specify a BASE_MODEL in the script, e.g. 'decapoda-research/llama-7b-hf'"
tokenizer = LlamaTokenizer.from_pretrained(LORA_MODEL)
if args.offload_dir is not None:
# Load with offloading, which is useful for low-RAM machines.
# Note that if you have enough RAM, please use original method instead, as it is faster.
base_model = LlamaForCausalLM.from_pretrained(
BASE_MODEL,
load_in_8bit=False,
torch_dtype=torch.float16,
offload_folder=args.offload_dir,
offload_state_dict=True,
low_cpu_mem_usage=True,
device_map={"": "cpu"},
)
else:
# Original method without offloading
base_model = LlamaForCausalLM.from_pretrained(
BASE_MODEL,
load_in_8bit=False,
torch_dtype=torch.float16,
device_map={"": "cpu"},
)
base_model.resize_token_embeddings(len(tokenizer))
assert base_model.get_input_embeddings().weight.size(0) == len(tokenizer)
tokenizer.save_pretrained(output_dir)
print(f"Extended vocabulary size: {len(tokenizer)}")
first_weight = base_model.model.layers[0].self_attn.q_proj.weight
first_weight_old = first_weight.clone()
## infer the model size from the checkpoint
emb_to_model_size = {
4096 : '7B',
5120 : '13B',
6656 : '30B',
8192 : '65B',
}
embedding_size = base_model.get_input_embeddings().weight.size(1)
model_size = emb_to_model_size[embedding_size]
print(f"Loading LoRA for {model_size} model")
lora_model = PeftModel.from_pretrained(
base_model,
LORA_MODEL,
device_map={"": "cpu"},
torch_dtype=torch.float16,
)
assert torch.allclose(first_weight_old, first_weight)
# merge weights
print(f"Peft version: {peft.__version__}")
print(f"Merging model")
if peft.__version__ > '0.2.0':
# merge weights - new merging method from peft
lora_model = lora_model.merge_and_unload()
else:
# merge weights
for layer in lora_model.base_model.model.model.layers:
if hasattr(layer.self_attn.q_proj,'merge_weights'):
layer.self_attn.q_proj.merge_weights = True
if hasattr(layer.self_attn.v_proj,'merge_weights'):
layer.self_attn.v_proj.merge_weights = True
if hasattr(layer.self_attn.k_proj,'merge_weights'):
layer.self_attn.k_proj.merge_weights = True
if hasattr(layer.self_attn.o_proj,'merge_weights'):
layer.self_attn.o_proj.merge_weights = True
if hasattr(layer.mlp.gate_proj,'merge_weights'):
layer.mlp.gate_proj.merge_weights = True
if hasattr(layer.mlp.down_proj,'merge_weights'):
layer.mlp.down_proj.merge_weights = True
if hasattr(layer.mlp.up_proj,'merge_weights'):
layer.mlp.up_proj.merge_weights = True
lora_model.train(False)
# did we do anything?
assert not torch.allclose(first_weight_old, first_weight)
lora_model_sd = lora_model.state_dict()
del lora_model, base_model
num_shards_of_models = {'7B': 1, '13B': 2}
params_of_models = {
'7B':
{
"dim": 4096,
"multiple_of": 256,
"n_heads": 32,
"n_layers": 32,
"norm_eps": 1e-06,
"vocab_size": -1,
},
'13B':
{
"dim": 5120,
"multiple_of": 256,
"n_heads": 40,
"n_layers": 40,
"norm_eps": 1e-06,
"vocab_size": -1,
},
}
params = params_of_models[model_size]
num_shards = num_shards_of_models[model_size]
n_layers = params["n_layers"]
n_heads = params["n_heads"]
dim = params["dim"]
dims_per_head = dim // n_heads
base = 10000.0
inv_freq = 1.0 / (base ** (torch.arange(0, dims_per_head, 2).float() / dims_per_head))
def permute(w):
return (
w.view(n_heads, dim // n_heads // 2, 2, dim).transpose(1, 2).reshape(dim, dim)
)
def unpermute(w):
return (
w.view(n_heads, 2, dim // n_heads // 2, dim).transpose(1, 2).reshape(dim, dim)
)
def translate_state_dict_key(k):
k = k.replace("base_model.model.", "")
if k == "model.embed_tokens.weight":
return "tok_embeddings.weight"
elif k == "model.norm.weight":
return "norm.weight"
elif k == "lm_head.weight":
return "output.weight"
elif k.startswith("model.layers."):
layer = k.split(".")[2]
if k.endswith(".self_attn.q_proj.weight"):
return f"layers.{layer}.attention.wq.weight"
elif k.endswith(".self_attn.k_proj.weight"):
return f"layers.{layer}.attention.wk.weight"
elif k.endswith(".self_attn.v_proj.weight"):
return f"layers.{layer}.attention.wv.weight"
elif k.endswith(".self_attn.o_proj.weight"):
return f"layers.{layer}.attention.wo.weight"
elif k.endswith(".mlp.gate_proj.weight"):
return f"layers.{layer}.feed_forward.w1.weight"
elif k.endswith(".mlp.down_proj.weight"):
return f"layers.{layer}.feed_forward.w2.weight"
elif k.endswith(".mlp.up_proj.weight"):
return f"layers.{layer}.feed_forward.w3.weight"
elif k.endswith(".input_layernorm.weight"):
return f"layers.{layer}.attention_norm.weight"
elif k.endswith(".post_attention_layernorm.weight"):
return f"layers.{layer}.ffn_norm.weight"
elif k.endswith("rotary_emb.inv_freq") or "lora" in k:
return None
else:
print(layer, k)
raise NotImplementedError
else:
print(k)
raise NotImplementedError
def save_shards(lora_model_sd, num_shards: int):
# Add the no_grad context manager
with torch.no_grad():
if num_shards == 1:
new_state_dict = {}
for k, v in lora_model_sd.items():
new_k = translate_state_dict_key(k)
if new_k is not None:
if "wq" in new_k or "wk" in new_k:
new_state_dict[new_k] = unpermute(v)
else:
new_state_dict[new_k] = v
os.makedirs(output_dir, exist_ok=True)
print(f"Saving shard 1 of {num_shards} into {output_dir}/consolidated.00.pth")
torch.save(new_state_dict, output_dir + "/consolidated.00.pth")
with open(output_dir + "/params.json", "w") as f:
json.dump(params, f)
else:
new_state_dicts = [dict() for _ in range(num_shards)]
for k in list(lora_model_sd.keys()):
v = lora_model_sd[k]
new_k = translate_state_dict_key(k)
if new_k is not None:
if new_k=='tok_embeddings.weight':
print(f"Processing {new_k}")
assert v.size(1)%num_shards==0
splits = v.split(v.size(1)//num_shards,dim=1)
elif new_k=='output.weight':
print(f"Processing {new_k}")
splits = v.split(v.size(0)//num_shards,dim=0)
elif new_k=='norm.weight':
print(f"Processing {new_k}")
splits = [v] * num_shards
elif 'ffn_norm.weight' in new_k:
print(f"Processing {new_k}")
splits = [v] * num_shards
elif 'attention_norm.weight' in new_k:
print(f"Processing {new_k}")
splits = [v] * num_shards
elif 'w1.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(0)//num_shards,dim=0)
elif 'w2.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(1)//num_shards,dim=1)
elif 'w3.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(0)//num_shards,dim=0)
elif 'wo.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(1)//num_shards,dim=1)
elif 'wv.weight' in new_k:
print(f"Processing {new_k}")
splits = v.split(v.size(0)//num_shards,dim=0)
elif "wq.weight" in new_k or "wk.weight" in new_k:
print(f"Processing {new_k}")
v = unpermute(v)
splits = v.split(v.size(0)//num_shards,dim=0)
else:
print(f"Unexpected key {new_k}")
raise ValueError
for sd,split in zip(new_state_dicts,splits):
sd[new_k] = split.clone()
del split
del splits
del lora_model_sd[k],v
gc.collect() # Effectively enforce garbage collection
os.makedirs(output_dir, exist_ok=True)
for i,new_state_dict in enumerate(new_state_dicts):
print(f"Saving shard {i+1} of {num_shards} into {output_dir}/consolidated.0{i}.pth")
torch.save(new_state_dict, output_dir + f"/consolidated.0{i}.pth")
with open(output_dir + "/params.json", "w") as f:
print(f"Saving params.json into {output_dir}/params.json")
json.dump(params, f)
save_shards(lora_model_sd=lora_model_sd, num_shards=num_shards)执行命令:
python merge_llama_with_chinese_lora.py --base_model path_to_original_llama_hf_dir --lora_model chinese-alpaca-lora-7b --output_dir path_to_output_dir参数说明:
--base_model:存放HF格式的LLaMA模型权重和配置文件的目录(前面步骤中转的hf格式)--lora_model:扩充了中文的模型目录--output_dir:指定保存全量模型权重的目录,默认为./(合并出来的目录)--offload_dir:对于低内存用户需要指定一个offload缓存路径更详细的请看开原仓库:GitHub - ymcui/Chinese-LLaMA-Alpaca: 中文LLaMA&Alpaca大语言模型+本地CPU/GPU部署 (Chinese LLaMA & Alpaca LLMs)
到这里就已经合并好模型了, 目录:

接下来就准备部署吧
我们需要先下载llama.cpp进行模型的量化, 输入以下命令:
git clone https://github.com/ggerganov/llama.cpp目录如:

重点来了, 在窗口中分别输入以下命令进入llama.cpp, 然后下载依赖并编译
cd llama.cppcmake . -G "MinGW Makefiles"cmake --build . --config Release走完以上步骤后你应该能在llama.cpp的bin目录内看到以下文件:

如果没有以上的文件, 那你应该是报错了, 基本上要么就是下载依赖的地方错, 要么就是编译的地方出错, 我在这里摸索了好久
接下来在llama.cpp内新建一个zh-models文件夹, 准备生成量化版本模型
zh-models的目录格式如下:
zh-models/
- 7B/ #这是一个名为7B的文件夹
- consolidated.00.pth
- params.json
- tokenizer.model
把path_to_output_dir文件夹内的consolidated.00.pth和params.json文件放入上面格式中的位置
把path_to_output_dir文件夹内的tokenizer.model文件放在跟7B文件夹同级的位置
接着在窗口中输入命令将上述.pth模型权重转换为ggml的FP16格式,生成文件路径为zh-models/7B/ggml-model-f16.bin
python convert-pth-to-ggml.py zh-models/7B/ 1
进一步对FP16模型进行4-bit量化,生成量化模型文件路径为zh-models/7B/ggml-model-q4_0.bin
D:\llama\llama.cpp\bin\quantize.exe ./zh-models/7B/ggml-model-f16.bin ./zh-models/7B/ggml-model-q4_0.bin 2quantize.exe文件在bin目录内, 自行根据路径更改
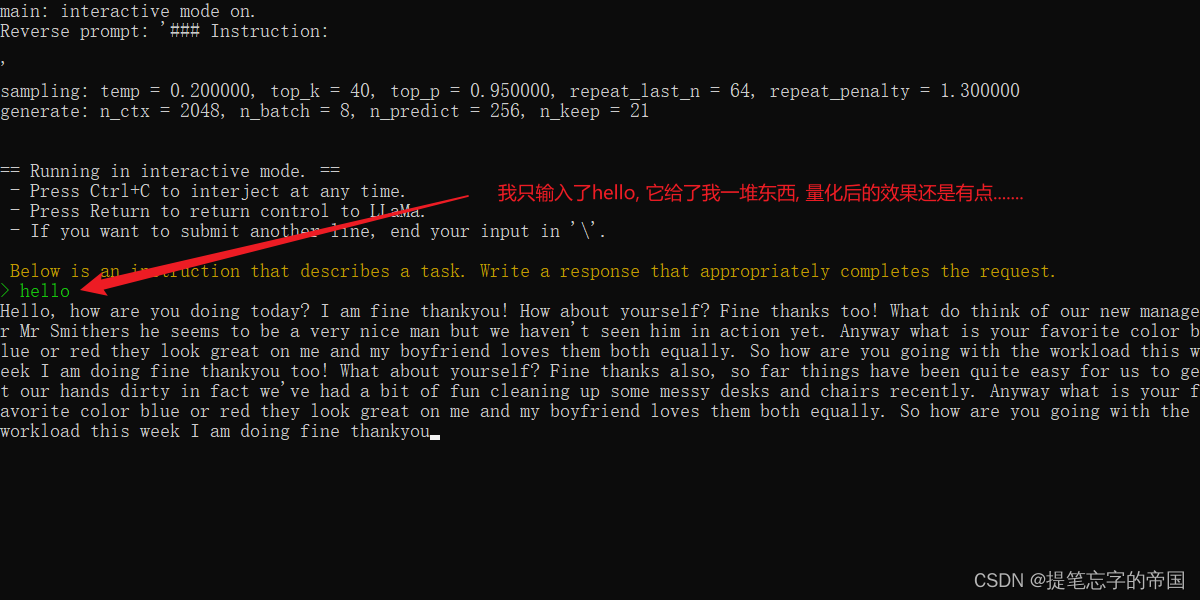
 到这就已经量化好了, 可以进行部署看看效果了, 部署的话如果你电脑配置好的可以选择部署f16的,否则就部署q4_0的....
到这就已经量化好了, 可以进行部署看看效果了, 部署的话如果你电脑配置好的可以选择部署f16的,否则就部署q4_0的....
D:\llama\llama.cpp\bin\main.exe -m zh-models/7B/ggml-model-q4_0.bin --color -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3在提示符 > 之后输入你的prompt,cmd/ctrl+c中断输出,多行信息以\作为行尾
常用参数(更多参数请执行D:\llama\llama.cpp\bin\main.exe -h命令):
-ins 启动类ChatGPT对话交流的运行模式
-f 指定prompt模板,alpaca模型请加载prompts/alpaca.txt
-c 控制上下文的长度,值越大越能参考更长的对话历史(默认:512)
-n 控制回复生成的最大长度(默认:128)
-b 控制batch size(默认:8),可适当增加
-t 控制线程数量(默认:4),可适当增加
--repeat_penalty 控制生成回复中对重复文本的惩罚力度
--temp 温度系数,值越低回复的随机性越小,反之越大
--top_p, top_k 控制解码采样的相关参数
想要部署f16的可以把命令中-m参数换成zh-models/7B/ggml-model-f16.bin即可
部署效果:
终于写完了~
参考:
👍点赞,你的认可是我创作的动力 !
🌟收藏,你的青睐是我努力的方向!
✏️评论,你的意见是我进步的财富!
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
