distinct用来查询不重复记录的条数,用count(distinct id)来返回不重复字段的条数。用法注意:
后面的所有参数的拼接取不重复的记录,即查出的参数拼接每行记录都是唯一的distinct支持单列、多列的去重方式。
作用于单列
select distinct name from A //对A表的name去重然后显示
作用于多列
select distinct id,name from A //对A表的id和name去重然后显示
配合count使用
select count(distinct name) from A //对A表的不同的name进行计数
按顺序去重时,order by 的列必须出现在 distinct 中
出错代码
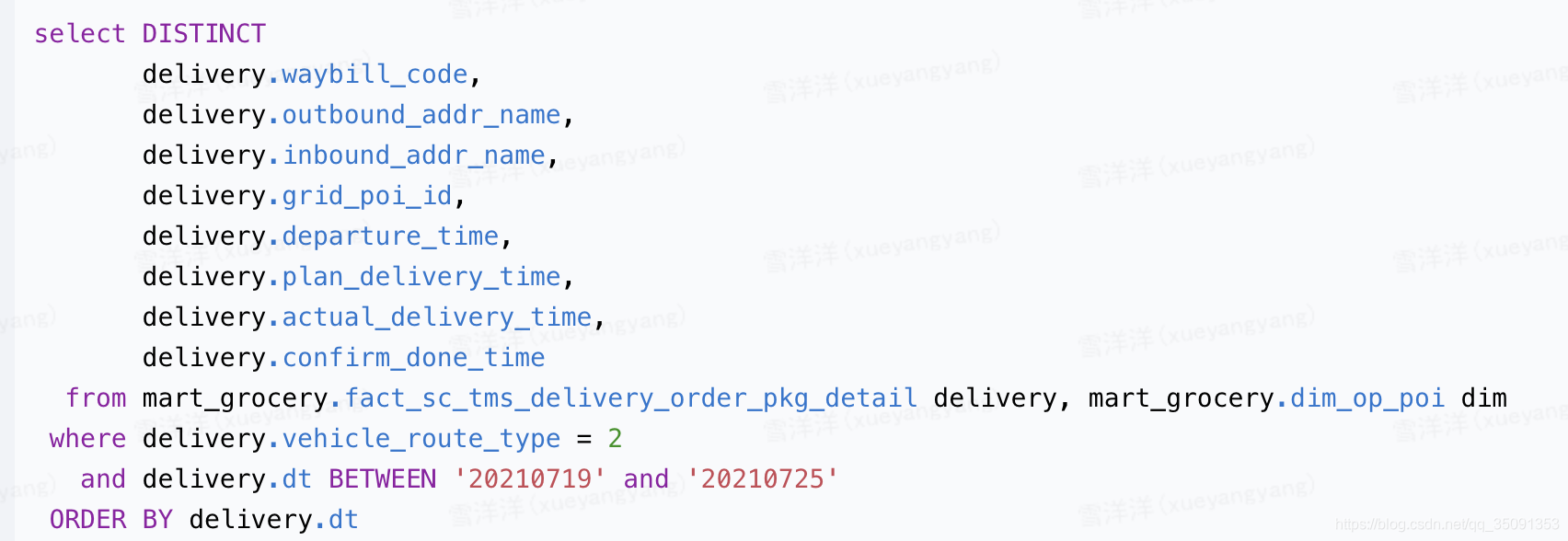
改正后的代码
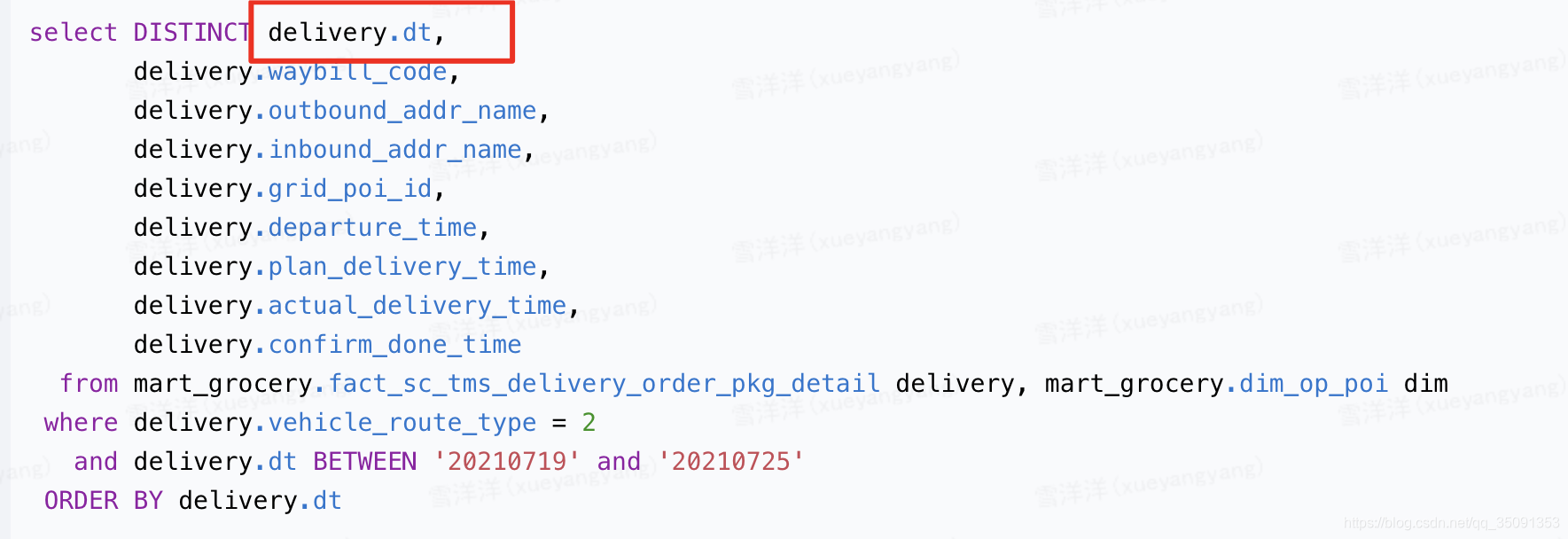
讨论:若不使用Distinct关键字,则order by后面的字段不一定要放在seletc中
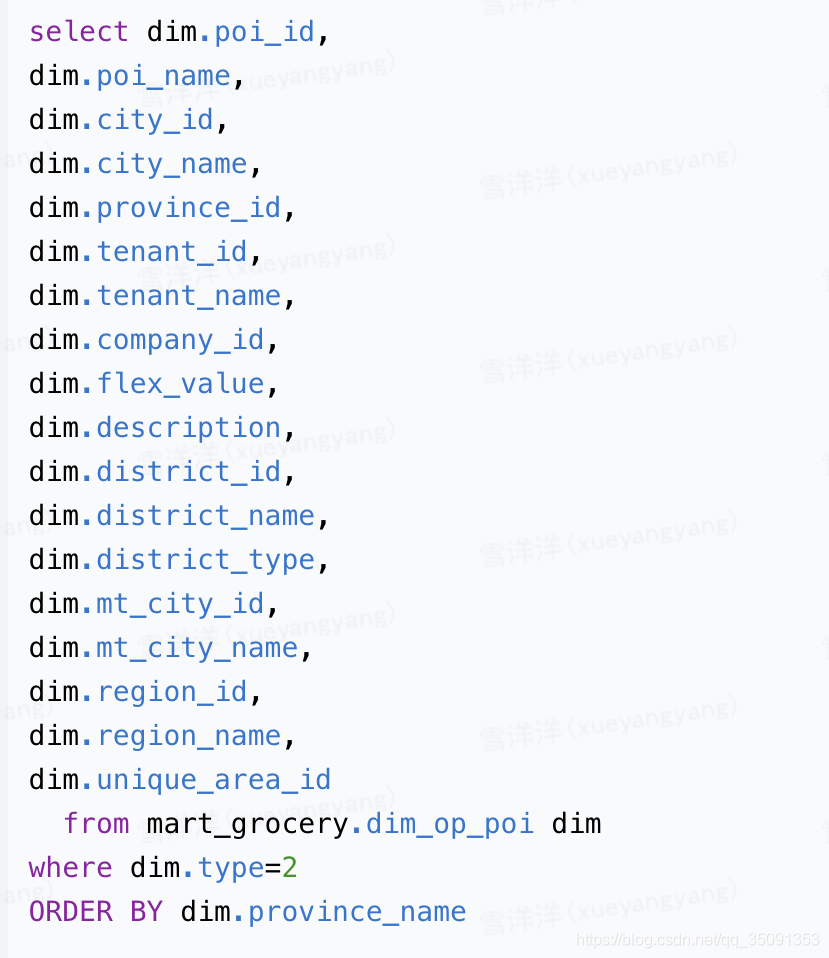
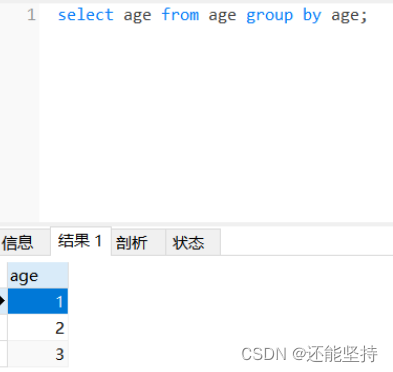
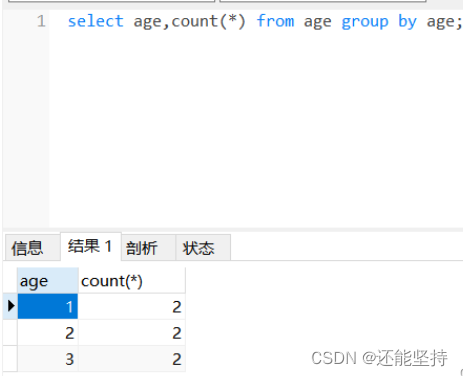
GROUP BY 语句根据一个或多个列对结果集进行分组。在分组的列上我们可以使用 COUNT, SUM, AVG,等函数,形式为select 重复的字段名 from 表名 group by 重复的字段名;
ROW_NUMBER() OVER 或 GROUP BY 和 COLLECT_SET/COLLECT_LIST说到要去重,自然会想到 DISTINCT,但是在 Hive SQL 里,它有两个问题:
DISTINCT 的两个问题,用 ROW_NUMBER() OVER 可解。比如,如果我们要按 key1 和 key2 两列为 key 去重,就会写出这样的代码:
WITH temp_table AS (
SELECT
key1,
key2,
[columns]...,
ROW_NUMBER() OVER (
PARTITION BY key1, key2
ORDER BY column ASC
) AS rn
FROM
table
)
SELECT
key1,
key2,
[columns]...
FROM
temp_table
WHERE
rn = 1;
这样,Hive 会按 key1 和 key2 为 key,将数据打到不同的 mapper 上,然后对 key1 和 key2 都相同的一组数据,按 column 升序排列,并最终在每组中保留排列后的第一条数据。借此就完成了按 key1 和 key2 两列为 key 的去重任务。注意 PARTITION BY 在此起到的作用:
但显然,这样做十分不优雅(not-elegant),并且不难想见其效率比较低。
row_number() OVER (PARTITION BY
COL1ORDER BYCOL2) as num 表示根据COL1分组,在分组内部根据COL2排序,此函数计算的值num就表示每组内部排序后的顺序编号(组内连续的唯一的)
ROW_NUMBER() OVER 解法的一个核心是利用 PARTITION BY 对数据按 key 分组,同样的功能用 GROUP BY 也可以实现。但是,GROUP BY 需要与聚合函数搭配使用。我们需要考虑,什么样的聚合函数能实现或者间接实现这样的功能呢?不难想到有 COLLECT_SET 和 COLLECT_LIST。
SELECT
key1,
key2,
[COLLECT_LIST(column)[1] AS column]...
FROM
temp_table
GROUP BY
key1, key2
对于 key1 和 key2 以外的列,我们用 COLLECT_LIST 将他们收集起来,然后输出第一个收集进来的结果。这里使用 COLLECT_LIST 而非 COLLECT_SET 的原因在于 SET 内是无序的,因此你无法保证输出的 columns 都来自同一条数据。若对于此没有要求或限制,则可以使用 COLLECT_SET,它会更节省资源。
相比前一种办法,由于省略了排序和(可能的)落盘动作,所以效率会高不少。但是因为(可能)不落盘,所以 COLLECT_LIST 中的数据都会缓存在内存当中。如果重复数量特别大,这种方法可能会触发 OOM。此时应考虑将数据进一步打散,然后再合并;或者干脆换用前一种办法。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
我想了解Ruby方法methods()是如何工作的。我尝试使用“ruby方法”在Google上搜索,但这不是我需要的。我也看过ruby-doc.org,但我没有找到这种方法。你能详细解释一下它是如何工作的或者给我一个链接吗?更新我用methods()方法做了实验,得到了这样的结果:'labrat'代码classFirstdeffirst_instance_mymethodenddefself.first_class_mymethodendendclassSecond使用类#returnsavailablemethodslistforclassandancestorsputsSeco
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
设置:狂欢ruby1.9.2高线(1.6.13)描述:我已经相当习惯在其他一些项目中使用highline,但已经有几个月没有使用它了。现在,在Ruby1.9.2上全新安装时,它似乎不允许在同一行回答提示。所以以前我会看到类似的东西:require"highline/import"ask"Whatisyourfavoritecolor?"并得到:Whatisyourfavoritecolor?|现在我看到类似的东西:Whatisyourfavoritecolor?|竖线(|)符号是我的终端光标。知道为什么会发生这种变化吗? 最佳答案
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我有一个具有一些属性的模型:attr1、attr2和attr3。我需要在不执行回调和验证的情况下更新此属性。我找到了update_column方法,但我想同时更新三个属性。我需要这样的东西:update_columns({attr1:val1,attr2:val2,attr3:val3})代替update_column(attr1,val1)update_column(attr2,val2)update_column(attr3,val3) 最佳答案 您可以使用update_columns(attr1:val1,attr2:val2