文章目录
栈也是一种线性表,数据在逻辑上挨着存储。只允许在固定的一端进行插入和删除元素。进行插入和删除操作的一端叫栈顶,另一端叫栈底。符合LIFO 先进后出。
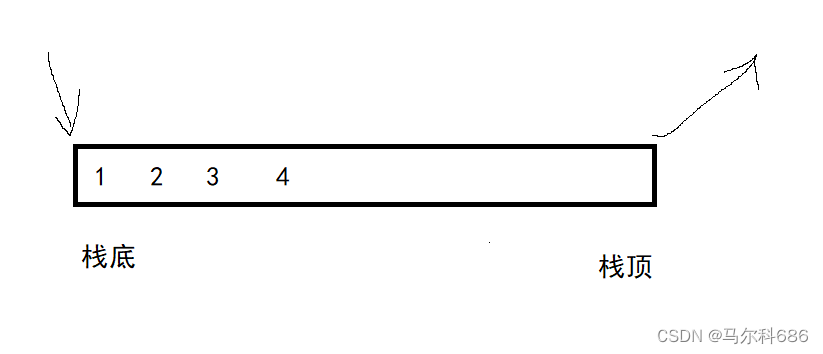
压栈:插入操作。
出栈:删除操作。
栈的实现用数组实现更好,因为完美符合数组的尾插尾删。
数组的缓存利用率高一点。
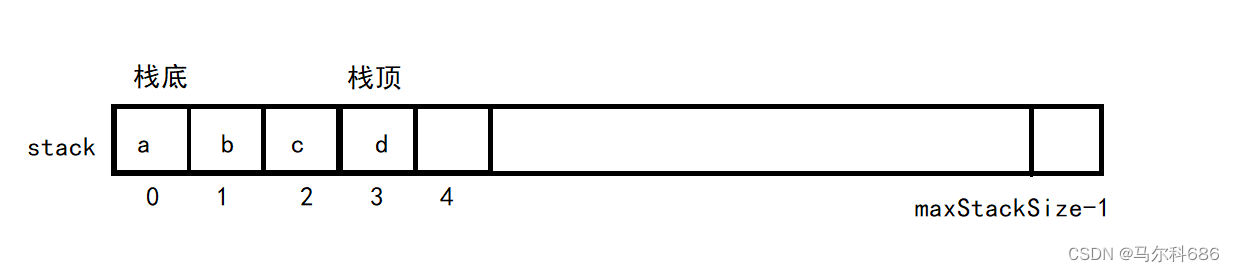
小练习:

支持动态增长的栈:
typedef int STDataType;
typedef struct Stack
{
STDataType* _a;
int _top; // 栈顶
int _capacity; // 容量
}Stack;
初始化栈:
void StackInit(ST* ps)
{
assert(ps);
ps->a = NULL;
ps->top = ps->capacity = 0;
}
入栈:进栈(栈的插入操作),若栈未满,则将x加入使之成为新栈顶。
void StackPush(ST* ps, STDataType x)
{
assert(ps);
if (ps->top == ps->capacity)
{
int newCapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
STDataType* tmp = (STDataType*)realloc(ps->a, newCapacity * sizeof(STDataType));
if (tmp == NULL)
{
perror("realloc fail");
exit(-1);
}
ps->a = tmp;
ps->capacity = newCapacity;
}
ps->a[ps->top] = x;
ps->top++;
}
出栈:出栈(栈的删除操作),若栈非空,则弹出栈顶元素,并用x返回。
void StackPop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
--ps->top;
}
获取栈顶元素:
STDataType StackTop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
return ps->a[ps->top - 1];
}
获取栈中有效元素个数:
int StackSize(ST* ps)
{
assert(ps);
return ps->top;
}
销毁栈:栈销毁,并释放占用的存储空间
void StackDestroy(ST* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->capacity = ps->top = 0;
}
检测栈是否为空,如果为空返回非零结果,如果不为空返回0:
bool StackEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
}
Stack.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
void StackInit(ST* ps);
void StackDestroy(ST* ps);
void StackPush(ST* ps, STDataType x);
void StackPop(ST* ps);
STDataType StackTop(ST* ps);
bool StackEmpty(ST* ps);
int StackSize(ST* ps);
Stack.c
#include "Stack.h"
void StackInit(ST* ps)
{
assert(ps);
ps->a = NULL;
ps->top = ps->capacity = 0;
}
void StackDestroy(ST* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->capacity = ps->top = 0;
}
void StackPush(ST* ps, STDataType x)
{
assert(ps);
if (ps->top == ps->capacity)
{
int newCapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
STDataType* tmp = (STDataType*)realloc(ps->a, newCapacity * sizeof(STDataType));
if (tmp == NULL)
{
perror("realloc fail");
exit(-1);
}
ps->a = tmp;
ps->capacity = newCapacity;
}
ps->a[ps->top] = x;
ps->top++;
}
void StackPop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
--ps->top;
}
STDataType StackTop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
return ps->a[ps->top - 1];
}
bool StackEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
}
int StackSize(ST* ps)
{
assert(ps);
return ps->top;
}
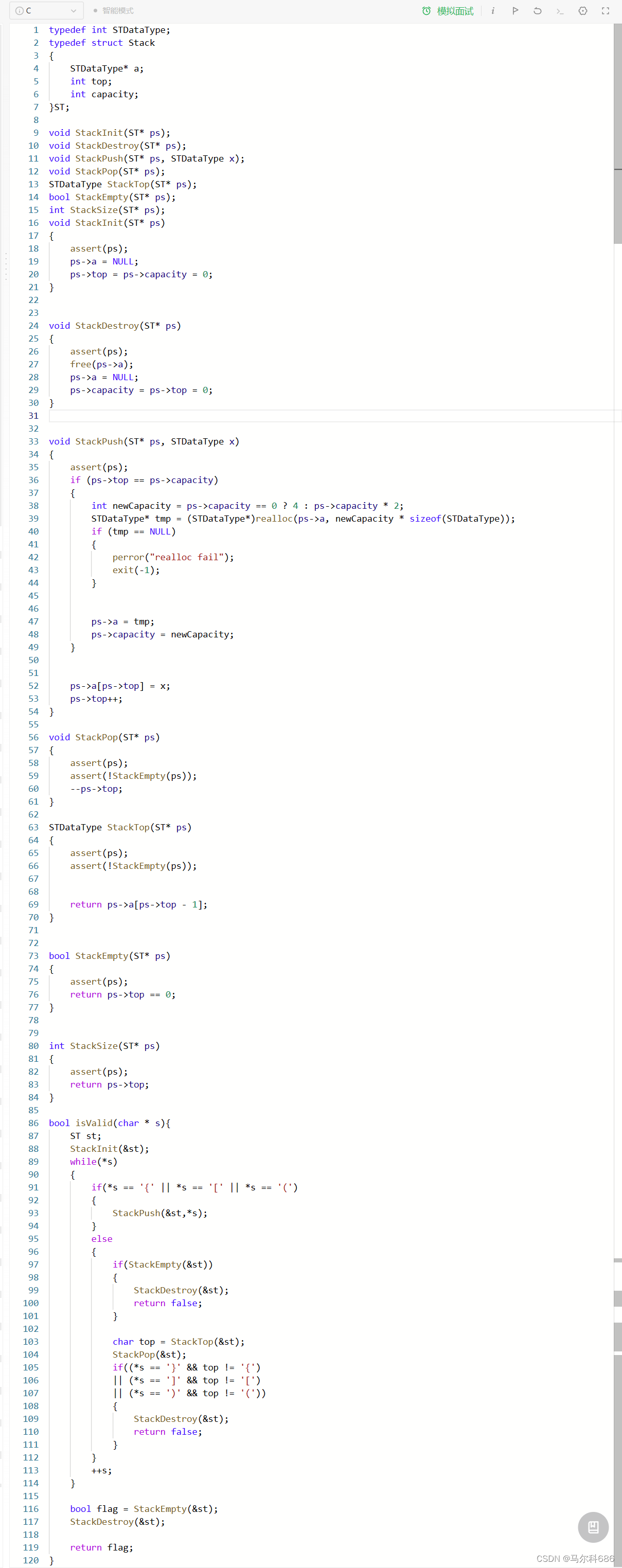
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out)
入队列:进行插入操作的一端称为队尾。
出队列:进行删除操作的一端称为队头。
队列用链表的结构实现更优
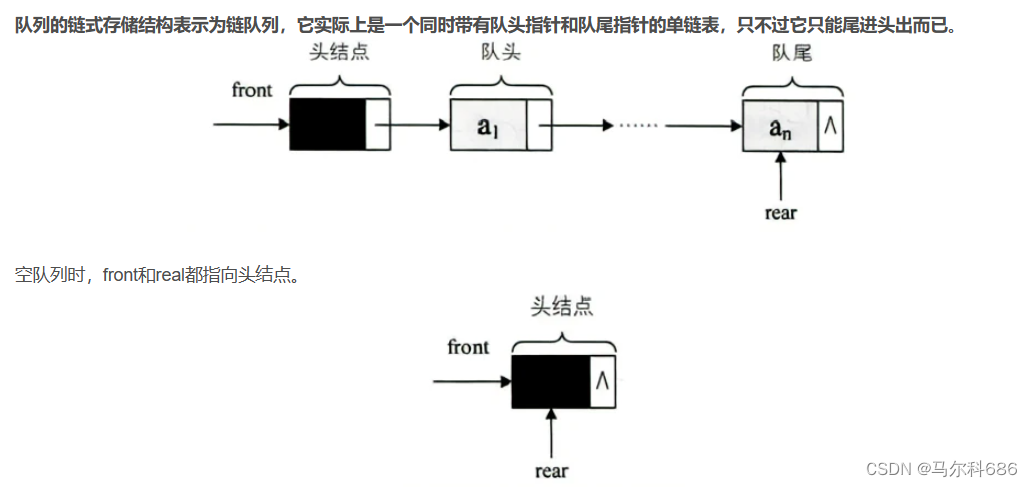
链式结构:表示队列
typedef struct QListNode
{
struct QListNode* _pNext;
QDataType _data;
}QNode;
队列的结构:
typedef struct Queue
{
QNode* head;
QNode* tail;
int size;
}Queue;
初始化队列:
void QueueInit(Queue* pq)
{
assert(pq);
pq->head = pq->tail = NULL;
pq->size = 0;
}
队尾入队列:
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
else
{
newnode->data = x;
newnode->next = NULL;
}
if (pq->tail == NULL)
{
pq->head = pq->tail = newnode;
}
else
{
pq->tail->next = newnode;
pq->tail = newnode;
}
pq->size++;
}
队头出队列:
void QueuePop(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
if (pq->head->next == NULL)
{
free(pq->head);
pq->head = pq->tail = NULL;
}
else
{
QNode* del = pq->head;
pq->head = pq->head->next;
free(del);
del = NULL;
}
pq->size--;
}
获取队列头部元素:
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->head->data;
}
获取队列队尾元素:
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->tail->data;
}
获取队列中有效元素个数:
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}
检测队列是否为空,如果为空返回非零结果,如果非空返回0:
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->head == NULL && pq->tail == NULL;
}
销毁队列:
void QueueDestroy(Queue* pq)
{
assert(pq);
QNode* cur = pq->head;
while (cur)
{
QNode* del = cur;
cur = cur->next;
free(del);
}
pq->head = pq->tail = NULL;
}
Queue.h
#pragma once
#include <stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
typedef int QDataType;
typedef struct QueueNode
{
struct QueueNode* next;
QDataType data;
}QNode;
typedef struct Queue
{
QNode* head;
QNode* tail;
int size;
}Queue;
void QueueInit(Queue* pq);
void QueueDestroy(Queue* pq);
void QueuePush(Queue* pq, QDataType x);
QDataType QueueFront(Queue* pq);
QDataType QueueBack(Queue* pq);
bool QueueEmpty(Queue* pq);
int QueueSize(Queue* pq);
Queue.c
#include"Queue.h"
void QueueInit(Queue* pq)
{
assert(pq);
pq->head = pq->tail = NULL;
pq->size = 0;
}
void QueueDestroy(Queue* pq)
{
assert(pq);
QNode* cur = pq->head;
while (cur)
{
QNode* del = cur;
cur = cur->next;
free(del);
}
pq->head = pq->tail = NULL;
}
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
else
{
newnode->data = x;
newnode->next = NULL;
}
if (pq->tail == NULL)
{
pq->head = pq->tail = newnode;
}
else
{
pq->tail->next = newnode;
pq->tail = newnode;
}
pq->size++;
}
void QueuePop(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
if (pq->head->next == NULL)
{
free(pq->head);
pq->head = pq->tail = NULL;
}
else
{
QNode* del = pq->head;
pq->head = pq->head->next;
free(del);
del = NULL;
}
pq->size--;
}
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->head->data;
}
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->tail->data;
}
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->head == NULL && pq->tail == NULL;
}
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}
题目链接:
1.https://leetcode.cn/problems/valid-parentheses/
题目链接:
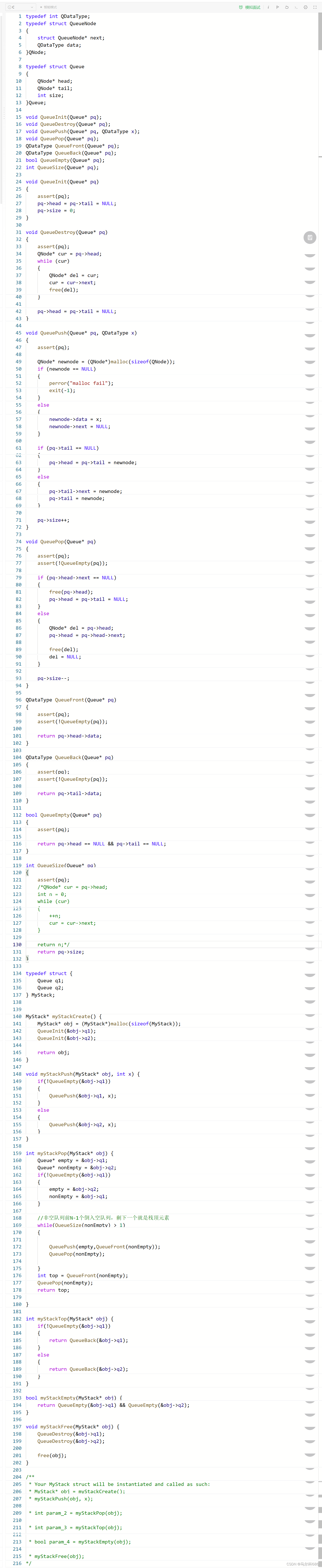
2.https://leetcode.cn/problems/implement-stack-using-queues/

我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit