一、虚拟机安装CentOS7并配置共享文件夹
二、CentOS 7 上hadoop伪分布式搭建全流程完整教程
三、本机使用python操作hdfs搭建及常见问题
四、mapreduce搭建
五、mapper-reducer编程搭建
六、hive数据仓库安装
mapreduce搭建
cd /usr/local/hadoop/etc/hadoop/
cp mapred-site.xml.template mapred-site.xml
编辑mapred-site.xml
sudo gedit mapred-site.xml
替换
<configuration>
</configuration>
为
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
sudo gedit yarn-site.xml
configuration内容替换如下
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
删除/home/huangqifa/data(core-site.xml、hdfs-site.xml中的存储路径)
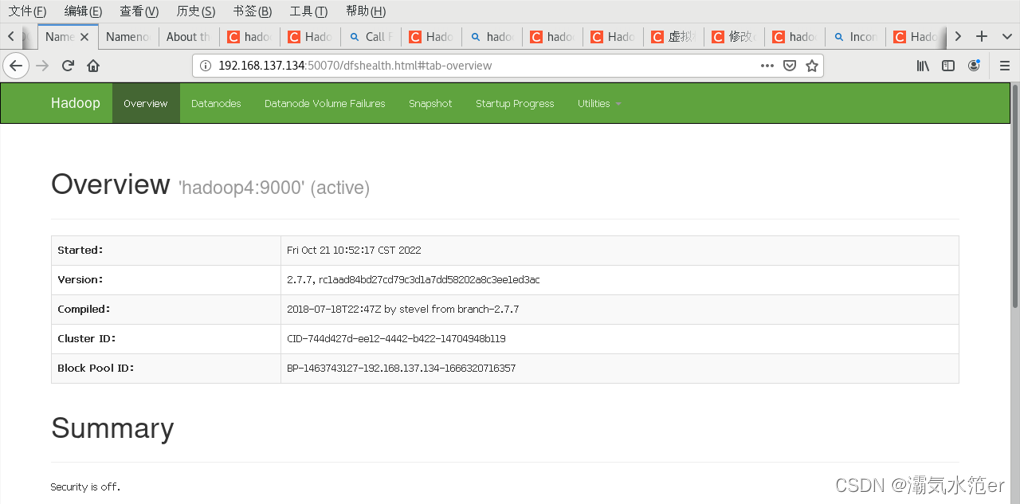
hadoop namenode -format
sh /usr/local/hadoop/sbin/start-all.sh
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
[huangqifa@hadoop4 ~]$ jps
3012 NameNode
3562 ResourceManager
4044 Jps
3869 NodeManager
3374 SecondaryNameNode
3167 DataNode
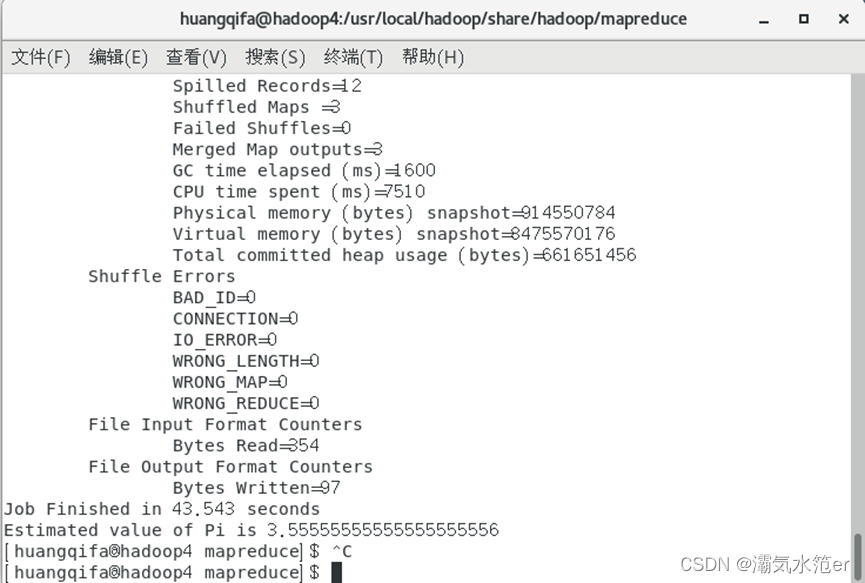
cd /usr/local/hadoop/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-2.7.7.jar pi 3 3
其中第一个3的含义是指开启3个map任务,第二个3是每个map里面投掷3次,这两个参数可以修改
参考网址:https://blog.csdn.net/jjjjjjabnannnan/article/details/110239351
(二十二)-框架主入口main.py设计&log日志调用和生成1测试目的2测试需求3需求分析4详细设计4.1新建存放日志目录log4.1.1配置config.py中写入log的目录4.2`baseInfo.py`中加入日志4.3`test_gedit.py`中加入日志4.4主函数入口main.py中调用日志5调用日志主函数main.py源码6`baseInfo.py`源码7`test_gedit.py`源码8运行效果9目前框架结构1测试目的组织运行所有的测试用例,并调用日志模块,便于问题定位。
(1)为什么写这个话题(Why)读万卷书不如行千里路。这次搭建MQTT服务,遇到了一些误解,特此记录备忘。主要包括:(1)服务(Broker)的账户管理与网页管理平台的账户(2)与web应用的集成(Spring系)(2)ActiveMQ版本选择因为JAVA环境是JDK8,所以按兼容性考虑选择了ActiveMQ5.15的最后版本5.15.15。如果你是JDK11则可考虑ActiveMQ的最新版本5.17或5.18。ActiveMQ支持MQTTv3.1.1andv3.1。(3)ActiveMQ与web应用的集成主要介绍与Spring系的webapp集成(SpringBoot和SpringMVC)。
这篇文章,主要介绍如何使用SpringCloud微服务组件从0到1搭建一个微服务工程。目录一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件(2)微服务依赖1.2、搭建注册中心(1)引入依赖(2)配置文件(3)启动类1.3、搭建配置中心(1)引入依赖(2)配置文件(3)启动类1.4、搭建API网关(1)引入依赖(2)配置文件(3)启动类1.5、搭建服务提供者(1)引入依赖(2)配置文件(3)启动类1.6、搭建服务消费者(1)引入依赖(2)配置文件(3)启动类1.7、运行测试一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件这里主要是使用的SpringCloudNetflix
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我目前正在尝试搭建一个学习Ruby的开发环境。环境主要是为了掌握这门语言,但我很可能会在很长一段时间后转向使用Rails进行开发。以Web开发为目标,我想了解首选的Web服务器和数据库。我打算在虚拟机上设置环境,所以我不担心把它弄坏。因此,我愿意使用Linux发行版、OSX或Windows作为操作系统。我正从C#转向,所以我想在一定程度上被迫采用Ruby的
以太坊概论考察课更具课堂教学讲解,参考开放资料。使用所学的知识,创建项目并完成要求的内容。包含的功能和要求具体如下:一:安装并运行geth客户端1、下载安装geth首先下载geth:https://geth.ethereum.org/downloads/选择路径↓2、配置环境变量3、运行geth如下命令所示:查看geth命令。使用gethversion查看geth版本号,判断geth是否成功安装。如下命令所示:`gethversion`可以通过geth--help查看geth工具所支持的命令和相关参数,方便后期关于geth的操作。如下命令所示:geth--help运行结果如下:二:搭建get
目录一、下载Elasticsearch1.选择你要下载的Elasticsearch版本二、采用通用搭建集群的方法三、配置三台es1.上传压缩包到任意一台虚拟机中2.解压并修改配置文件(配置单台es)3.配置三台es集群4.设置后台启动和开机自启(可选)一、下载Elasticsearch1.选择你要下载的Elasticsearch版本es下载地址这里我下载的是二、采用通用搭建集群的方法集群搭建方法三、配置三台es1.上传压缩包到任意一台虚拟机中上传方式有两种第一种:使用xftp上传直接拖动过去就可以了。第二种:使用lrzsz先安装yum-yinstalllrzsz切换到要上传的位置cd/opt/
一、使用Yarn作为项目的包管理工具1、Yarn是什么?“Yarn是由Facebook、Google、Exponent和Tilde联合推出了一个新的JS包管理工具,正如官方文档中写的,Yarn是为了弥补npm的一些缺陷而出现的。”这句话让我想起了使用npm时的坑:npminstall的时候非常慢,特别是新的项目拉下来要等半天,删除node_modules,重新install的时候依旧如此。同一个项目,安装的时候无法保持一致性。由于package.json文件中版本号的特点,下面三个版本号在安装的时候代表的含义不同。 "5.0.3" 表示:安装指定的5.0.3版本"~5.0.3" 表示:安
SpringCloudAlibaba全集文章目录:零、手把手教你搭建SpringCloudAlibaba项目一、手把手教你搭建SpringCloudAlibaba之生产者与消费者二、手把手教你搭建SpringCloudAlibaba之Nacos服务注册中心三、手把手教你搭建SpringCloudAlibaba之Nacos服务配置中心四、手把手教你搭建SpringCloudAlibaba之Nacos服务集群配置五、手把手教你搭建SpringCloudAlibaba之Nacos服务持久化配置六、手把手教你搭建SpringCloudAlibaba之Sentinel实现流量实时监控七、手把手教你搭
【保姆级】Python最新版开发环境搭建,看这一篇就够了(适用于Python3.11.2安装)文章目录【保姆级】Python最新版开发环境搭建,看这一篇就够了(适用于Python3.11.2安装)一、Python解释器安装Windows安装步骤环境变量配置(非必要)MacOS安装步骤Linux安装步骤二、PyCharm安装三、创建Python工程工欲善其事必先利其器,在使用Python开发程序之前,在计算机上搭建Python开发环境是必不可少的环节,目前Python最新稳定版本是3.11.1,且支持到2027年,如下图所示本文手把手带你从0到1搭建Python最新版3.11.1开发环境,堪称保
文章目录实验二:HDFS+MapReduce数据处理与存储实验1.实验目的2.实验环境3.实验内容3.1HDFS部分3.1.1上传文件3.1.2下载文件3.1.3显示文件信息3.1.4显示目录信息3.1.5删除文件3.1.6移动文件3.2MapReduce部分3.2.0Mapreduce原理3.2.1合并和去重3.2.1.1编写Merge.java代码3.2.1.2编译执行3.2.2文件的排序3.2.2.1编写Sort.java代码3.2.2.2编译执行4.踩坑记录5.心得体会6.源码附录6.1Merge.java完整代码6.2Sort.java完整代码实验二:HDFS+MapReduce数据