1.MultipartFile 概述
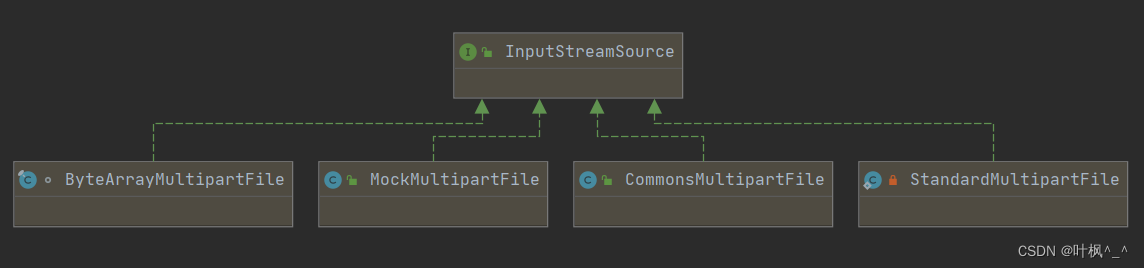
MultipartFile是SpringMVC提供简化文件流操作的接口,该接口实现类有如下几个
在不使用框架之前,都是使用原生的HttpServletRequest来接收上传的数据的,如下所示:
public String fileSave(HttpServletRequest request, HttpServletResponse response){
MultipartHttpServletRequest msr = (MultipartHttpServletRequest) request;
MultipartFile targetFile = msr.getFile("file");
}
此处附上处理文件的一般操作
// MultipartFile targetFile
// 文件写入路径 每次写文件的时候要保证 路径唯一 不会发生写入文件覆盖的问题
String fileName = targetFile.getOriginalFilename();
LOGGER.info("fileOnlineShowServiceImpl ==> fileSave() fileName : {}", fileName);
// 临时将文件存放本地存储位置
String tempFilePath = downloadPath + File.separator + ToolsUtil.createUUID() + "_" + fileName;
// 将文件写入到本地 localPath
targetFile.transferTo(new File(tempFilePath));
LOGGER.info("fileOnlineShowServiceImpl ==> fileSave() tempFilePath : {}", tempFilePath);
// 将内存的文件上传阿里云OSS,并转换成图片,返回对应的信息
Map<String, String> fileInfoMaps = fileDealWithService.dealWithFileService(ComonConstant.DIGIT_LONG_ONE, tempFilePath, Boolean.TRUE);
// 将写入后的数据新增到数据记录表中
addNewRecorde(fileSaveReqDTO, fileInfoMaps , yhSystemUsers);
文件是以二进制流传递到后端的,然后需要我们自己转换为File类。使用MultipartFile接口中提供的实现方法,我们对文件处理的操作就会变得很便捷。MultipartFile接口方法如下:
package org.springframework.web.multipart;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.nio.file.Files;
import java.nio.file.Path;
import org.springframework.core.io.InputStreamSource;
import org.springframework.core.io.Resource;
import org.springframework.lang.Nullable;
import org.springframework.util.FileCopyUtils;
public interface MultipartFile extends InputStreamSource {
//返回参数的名称
String getName();
// 获取源文件的名称
@Nullable
String getOriginalFilename();
// 返回文件的内容类型
@Nullable
String getContentType();
// 判断文件内容是否为空
boolean isEmpty();
// 返回文件大小 以字节为单位
long getSize();
// 将文件内容转化成一个byte[] 返回
byte[] getBytes() throws IOException;
// 返回输入的文件流
InputStream getInputStream() throws IOException;
default Resource getResource() {
return new MultipartFileResource(this);
}
void transferTo(File var1) throws IOException, IllegalStateException;
// 将MultipartFile 转换换成 File 写入到指定路径
default void transferTo(Path dest) throws IOException, IllegalStateException {
FileCopyUtils.copy(this.getInputStream(), Files.newOutputStream(dest));
}
}
2.MultipartFile 转File
知悉了MultipartFile 后,我们知道MultipartFile 内部提供了MultipartFile 转File.
// 临时将文件存放本地存储位置
String tempFilePath = downloadPath + File.separator + ToolsUtil.createUUID() + "_" + fileName;
// 将文件写入到本地 downloadPath
targetFile.transferTo(new File(tempFilePath));
同时想必大家平时也经常做过类似的处理,常见的如下操作:
public void writeFileToLocal(MultipartFile targetFile) {
//开始时间
LocalDateTime startTime = LocalDateTime.now();
BufferedInputStream bufferedReader = null;
BufferedOutputStream bufferedWriter = null;
try {
bufferedReader = new BufferedInputStream(targetFile.getInputStream());
bufferedWriter = new BufferedOutputStream(new FileOutputStream(downloadPath + File.separator +targetFile.getOriginalFilename()));
int len=0;
//字节缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
while ((len = bufferedReader.read(buffer.array())) != -1) {
bufferedWriter.write(buffer.array(),0,len);
bufferedWriter.flush();
}
LOGGER.info("writeFileToLocal ==> 耗时:" + Duration.between(startTime, LocalDateTime.now()).toMillis());
} catch (Exception e) {
LOGGER.info("writeFileToLocal 文件写入失败");
}finally {
if (null != bufferedReader) {
try {
bufferedReader.close();
} catch (IOException e) {
LOGGER.info("writeFileToLocal 文件写入失败");
}
}
if (null != bufferedWriter) {
try {
bufferedWriter.close();
} catch (IOException e) {
LOGGER.info("writeFileToLocal 文件写入失败");
}
}
}
}
3.File 转 MultipartFile
概述中有讲到Spring提供了MultipartFile 接口四个实现类,我们只需将File对象传入到对应实现类的构造方法中,即可实现File 转 MultipartFile,此处提供一个案例如下所示:
File file = new File(filePath); // 文件路径
FileInputStream input = new FileInputStream(file);
// File 转 MultipartFile
MultipartFile targetFiles = new MockMultipartFile("targetFiles",file.getName(),null,IOUtils.toByteArray(input));
String fileName = targetFiles.getOriginalFilename(); // 源文件名
我们经常会去对路径提取文件名,以及文件类型,下面贴出集中lang3提供的常用的方法
(1).substringAfter
// 切割文件路径 获取"_"后的文件名
String textType = "Af_yta_sder.pdf";
String subRet = StringUtils.substringAfter(textType, "_");
System.out.println("subRet = " + subRet );
输出结果:
subRet = yta_sder.pdf
(2).substringAfterLast
// 获取最后一个"."切割符后的字符串 往往用作获取文件类型
String textType = "Af_yta_sder.pdf";
String subRet = StringUtils.substringAfterLast(textType, ".");
System.out.println("subRet = " + subRet );
输出结果:
subRet = pdf
(3).substringBefore
// 获取"."切割符前的字符串 往往用作获取文件名
String textType = "Af_yta_sder.pdf";
String subRet = StringUtils.substringBefore(textType, ".");
System.out.println("subRet = " + subRet );
输出结果:
subRet = Af_yta_sder
(4).substringBeforeLast
// 获取最后一个切割符"_"前的字符串
String textType = "Af_yta_sder.pdf";
String subRet = StringUtils.substringBeforeLast(textType, "_");
System.out.println("subRet = " + subRet );
subRet = Af_yta
其他类似的方法大同小异,此处就不一一列举了.
从给定URL下载文件并立即将其上传到AmazonS3的更直接的方法是什么(+将有关文件的一些信息保存到数据库中,例如名称、大小等)?现在,我既不使用Paperclip,也不使用Carrierwave。谢谢 最佳答案 简单明了:require'open-uri'require's3'amazon=S3::Service.new(access_key_id:'KEY',secret_access_key:'KEY')bucket=amazon.buckets.find('image_storage')url='http://www.ex
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳
CSV.open(name,"r").eachdo|row|putsrowend我得到以下错误:CSV::MalformedCSVErrorUnquotedfieldsdonotallow\ror\n文件名是一个.txt制表符分隔文件。我是专门做的。我有一个.csv文件,我转到excel,并将文件保存为.txt制表符分隔的文件。所以它是制表符分隔的。CSV.open不应该能够读取制表符分隔的文件吗? 最佳答案 尝试像这样指定字段分隔符:CSV.open("name","r",{:col_sep=>"\t"}).eachdo|row|
我正在尝试编写一个将文件上传到AWS并公开该文件的Ruby脚本。我做了以下事情:s3=Aws::S3::Resource.new(credentials:Aws::Credentials.new(KEY,SECRET),region:'us-west-2')obj=s3.bucket('stg-db').object('key')obj.upload_file(filename)这似乎工作正常,除了该文件不是公开可用的,而且我无法获得它的公共(public)URL。但是当我登录到S3时,我可以正常查看我的文件。为了使其公开可用,我将最后一行更改为obj.upload_file(file
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
这个问题在这里已经有了答案:Whatdoes`if__FILE__==$0`meaninRuby(6个答案)关闭6年前。我在审查Ruby代码时偶然发现了这个语法。代码是:if__FILE__==$PROGRAM_NAME#somecode...end我想__FILE__是一个变量,可以让我获取我所在文件的名称?但是$PROGRAM_NAME简化了什么?另外,为什么这个if语句是必需的,因为程序可以使用或不使用它?
我在我正在处理的一些代码中发现了这一点。它旨在解决从磁盘读取key文件的要求。在生产环境中,key文件的内容位于环境变量中。旧代码:key=File.read('path/to/key.pem')新代码:key=File.read('|echo$KEY_VARIABLE')这是如何工作的? 最佳答案 来自IOdocs:Astringstartingwith“|”indicatesasubprocess.Theremainderofthestringfollowingthe“|”isinvokedasaprocesswithappro
我有这个代码File.open(file_name,'r'){|file|file.read}但是Rubocop发出警告:Offenses:Style/SymbolProc:Pass&:readasargumenttoopeninsteadofablock.你是怎么做到的? 最佳答案 我刚刚创建了一个名为“t.txt”的文件,其中包含“Hello,World\n”。我们可以按如下方式阅读。File.open('t.txt','r',&:read)#=>"Hello,World\n"顺便说一下,由于第二个参数的默认值是'r',所以这样
我有以下代码,它下载一个文件,然后将文件的内容读入一个变量。使用该变量,它执行一个命令。这个配方不会收敛,因为/root/foo在编译阶段不存在。我可以通过多个聚合和一个来解决这个问题ifFile.exist但我想用一个收敛来完成它。关于如何做到这一点有什么想法吗?execute'download_joiner'docommand"awss3cps3://bucket/foo/root/foo"not_if{::File.exist?('/root/foo')}endpassword=::File.read('/root/foo').chompexecute'join_domain'd
我创建了一个文件,这样我就可以在lib/foo/bar_woo.rb中的许多模型之间共享一个方法。在bar_woo.rb中,我定义了以下内容:moduleBarWoodefhelloputs"hello"endend然后在我的模型中我正在做类似的事情:defMyModel解释器提示它期望bar_woo.rb定义Foo::BarWoo。《使用Rails进行敏捷Web开发》一书指出,如果文件包含类或模块,并且文件使用类或模块名称的小写形式命名,那么Rails将自动加载文件。因此我不需要它。定义代码的正确方法是什么,在我的模型中调用代码的正确方法是什么? 最佳答案