近些年,HTAP 正在受到人们越来越多的关注,Gartner 在 2014 年提出了 HTAP 这个术语和它的定义:
Hybrid transaction/analytical processing (HTAP) is an emerging application architecture that ”breaks the wall“ between transaction processing and analytics. It enables more informed and ”in business real time“ decision making.
在此之前,市面上基本是 OLTP 和 OLAP 数据库的天下。
OLTP
第一个有效的面向事务的数据库在 1970 / 1980 年代开始广泛使用,它们后来被称为在线事务处理 (OLTP:Online Transaction Processing) 系统, 事务处理对单记录操作可靠性、准确性和速度要求非常高。
OLAP
随着数据量的增大,特别是互联网的发展,OLTP 数据库的工作负载越来越大,同时分析能力严重受限,我们需要一个能非常快速地在一个或多个数据库表中查找单个记录、多条记录或一种记录总数的数据库。OLAP 数据库同 OLTP 数据库在技术上也分道扬镳。
然而,针对不同数据场景选择对应的 TP / AP 系统也带来了相应的难题,因为 TP 和 AP 不是一套系统,在搭配使用时就会有数据传输的过程。在 一体化实时 HTAP 数据库 StoneDB,如何替换 MySQL 并实现近百倍性能提升的文章中,我们总结了业界通过 TP / ETL或数据迁移 / AP 结构来构建 HTAP 系统存在的一些问题:
Gartner 的最新报告表明,传统的 TP + AP 架构将事务和分析系统分开,业务实时响应的高需求意味着使用“过时”的数据已经不合时宜,商业时刻转瞬即逝。我们需要创建一套更简单的体系结构,让 TP + AP 及 ETL 过程被单个数据库所取代,消除数据副本,将数据存储在 OLTP 引擎中进行事务处理,然后将数据复制到 OLAP 引擎(可能多次)以进行分析。随着软硬件基础设施和数据库技术的不断进步,属于 HTAP 数据库系统的时代已经到来。
StoneDB 并不希望打造一个新的 StoneDB HTAP 生态。对于大部分数据库用户来说,最好的产品体验就是开箱即用,在一个黑盒系统中完成业务的平滑迁移,最大程度的降低用户学习成本和运维成本。而 MySQL 是世界上最流行的数据库,拥有庞大和成熟的生态。
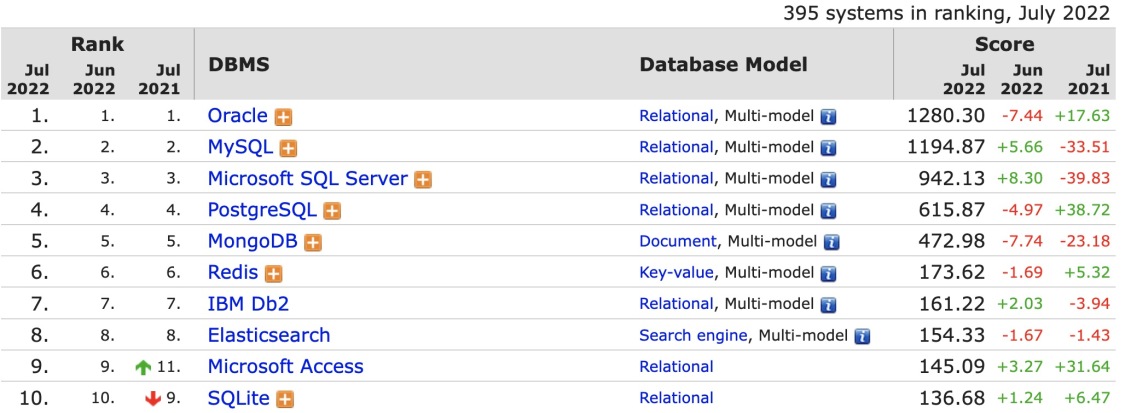
从 DB-Engines 排名上看到,MySQL 稳居第二,仅次于 Oracle。(下图来自 DB-Engines)
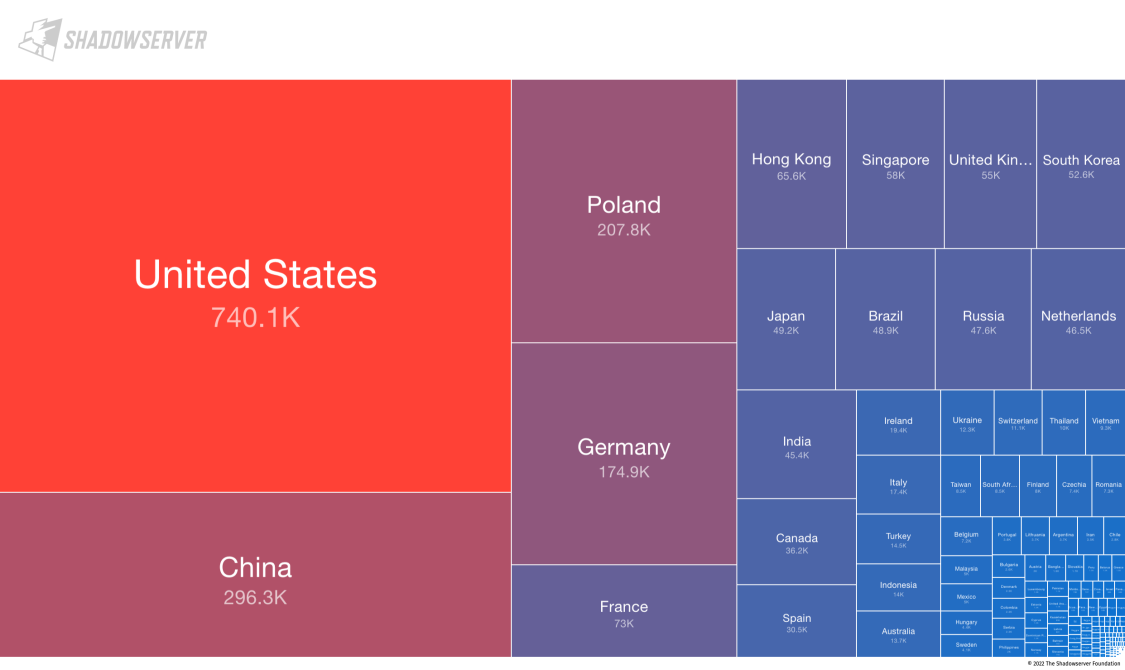
Shadowserver Foundation 在 5 月 31 日发布了一份全网的 MySQL扫描报告,超过 360 万个 MySQL 实例暴露在公网。这只是暴露出来的,我们可以推断,实际的装机量要远远大于这个数字。
我们以存储架构为特征对业界最新的 HTAP 数据库做一个概览:
从上述中可以看到,哪怕是最流行的开源数据库 MySQL,它的 HeatWave 也不开源。
StoneDB 就是希望打破这种局面,在开源这条道路上做一个探索,做一款由我们中国人主导的开源 HTAP 数据库。
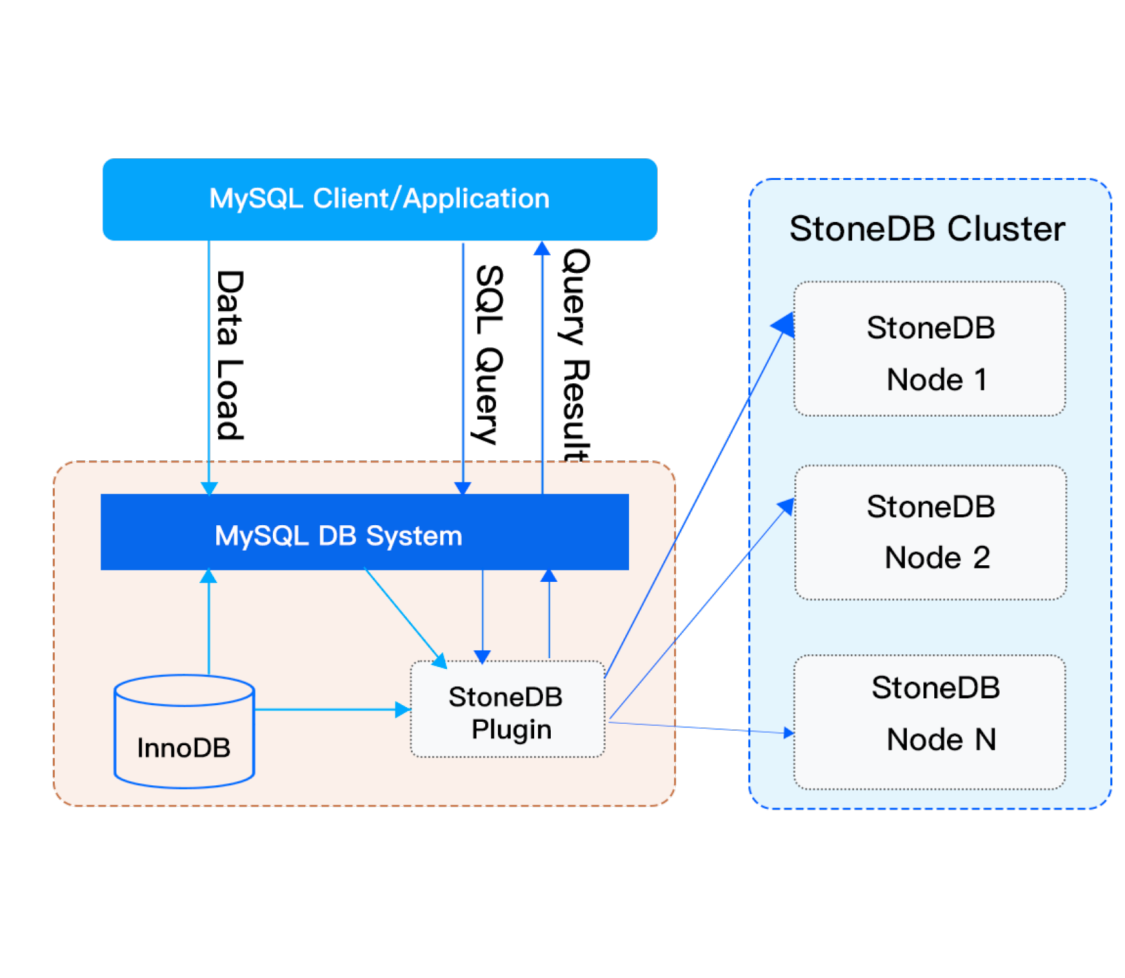
StoneDB 沿用并适配 MySQL sql 层,原生 100% 兼容 MySQL 协议和语法,我们先看下 StoneDB 官网提供的 2.0 架构图:
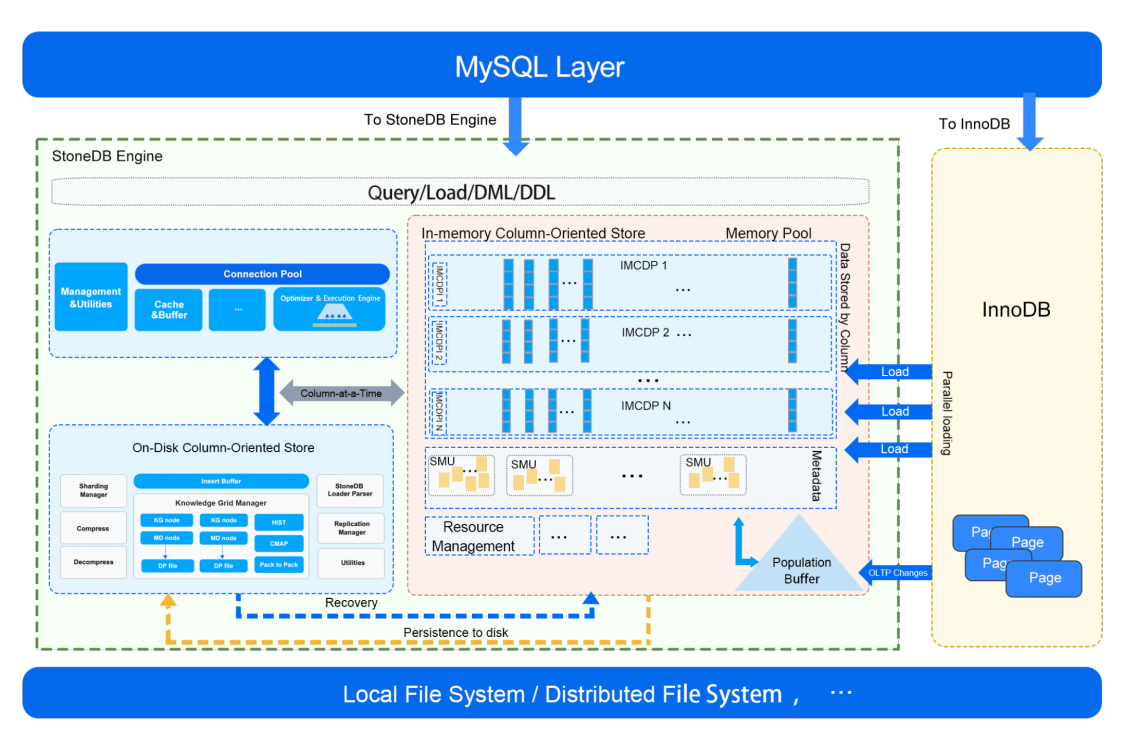
架构图中相关术语介绍:
IMCDP:In Memory Column Data Pack 的缩写,存储在内存中的列数据包。
IMCDPI:In Memory Column Data Pack Index 的缩写,用于保存 IMCDP 的元数据,包括:
SMU:snapshot meta unit 的缩写。
在 StoneDB 2.0 的设计中,会推出类似 MySQL HeatWave 的 In-Memory Column Store 引擎:基于磁盘的 RDBMS (MySQL 8.0)和分布式内存列存储(IMCS)来实现 HTAP。
StoneDB 在不改变 MySQL 原生的 OLTP 工作负载的前提下,深度集成 IMCS 集群以加速查询处理,事务在原生 MySQL 工作负载中执行。另外 StoneDB 会自行判断复杂查询并将其下推到 IMCS 引擎进行加速处理,经常访问的列将被加载到 IMCS 中,列数据从行存储中提取(由 InnoDB 并行加载到 IMCS),热数据驻留在 IMCS,冷数据落盘。
基于 IMCS 引擎我们将实现 AP 负载的全内存计算:
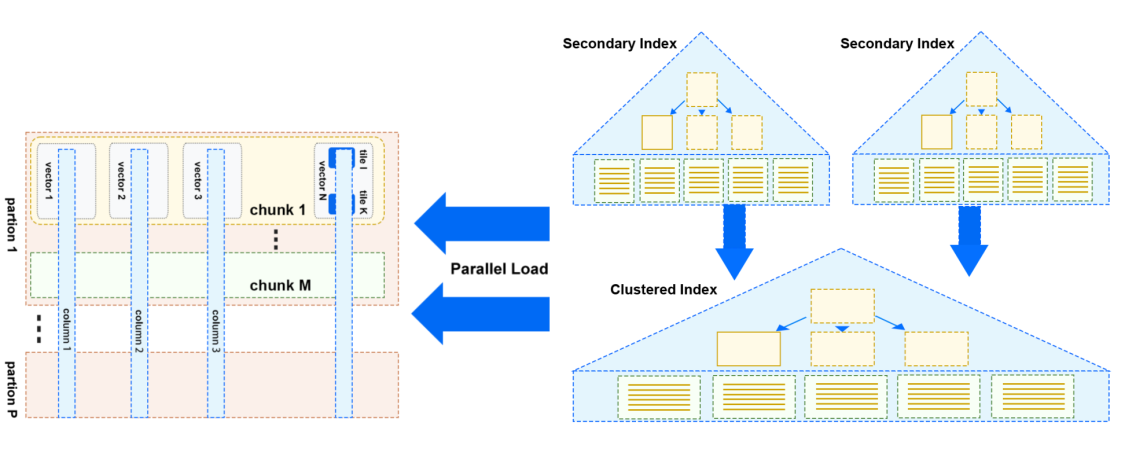
高效加载 TP 数据(From InnoDB)
上图是刚刚介绍了 StoneDB 2.0 架构中提到的从 InnoDB 并行加载数据的示意图。
与 HeatWave 采用的方案类似,通过并行扫描 TP 中的数据(主要是 InnoDB 表),将需要加载的数据按 partition ,chunk, vector, tile 的数据组织方式并行的加载至 IMCS 中,每个partion 中包括若干个 chunk,每个 chunk 中又包含若干个 vector,每个 vector 中包括了某列中的部分数据。同时,提供导入行为的监控能力,实时感知加载进度。在加载过程中通过非阻塞,无锁机制来实现高性能数据加载能力。
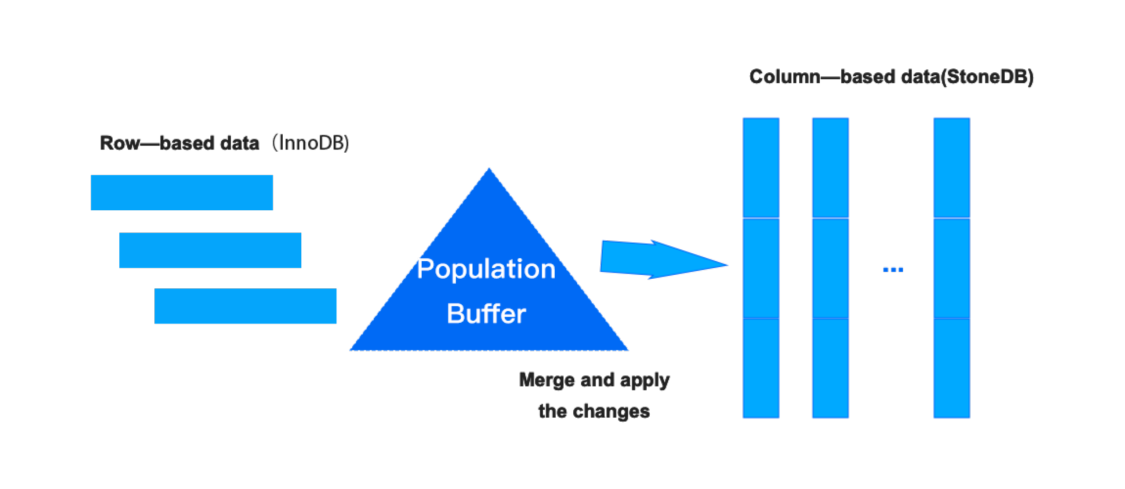
数据的更新
当 TP 中的数据发生变化后,将该项数据插入到 Population Buffer 中,并维护该数据的版本信息。当满足如下任一条件的时候,会将 Population Buffer 中的数据,依据版本信息依次与内存中的数据合并为最新的版本数据:
除了 Gartner 的原始定义,我们对 HTAP 更多视为一个集硬件、TP、AP、内存、云原生数据库技术、可扩展事务管理等多种功能的新兴架构,使事务处理和分析(HTAP)能够在同一套数据库上运行。
一个现代的 HTAP 数据库应该具备以下特性:
一致性:包含全面的 ACID 事务支持。数据密集型应用程序可以依靠它来保证数据一致性,从而提高开发人员的速度和用户体验。
高可用性:无论后端发生什么,用户都能进行 7x24 小时的访问。有一套内部机制来处理机器故障和网络问题等瞬时和永久性故障(比如宕机/脑裂),并且提供数据复制和细粒度数据放置功能,以确保数据高可用。并且提供滚动升级机制,避免集群扩展和架构升级等引发的停机对业务造成影响。
可扩展性:应用云原生技术,其计算和存储资源可以轻松扩展以应对业务的增长。按需且实时地添加新节点,以存储更多数据、处理更多读取和写入以及处理更复杂的查询。
实时性:数据库应支持任何实时更新,从而实现细粒度索引和并行查询执行。为了确保及时性,数据库架构必须同时利用行存储和列存储,并基于查询优化器选择最佳的数据访问路径。
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration
我已经找到了几个使用datamapper的示例,并且能够让它们正常工作。不过,所有这些示例都是针对sqlite数据库的。我正在尝试将数据映射器与postgresql一起使用。我将datamapper中的调用从sqlite3更改为postgres,并且我已经安装了dm-postgres-adapter。但它仍然不起作用。我还需要做什么? 最佳答案 与SQLite不同,PostgreSQL不将数据库存储在单个文件中。在你拥有createdyourdatabase之后,尝试这样的事情:DataMapper.setup:default,{:
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我使用的是遗留数据库,所以我无法控制数据模型。他们使用了很多多态链接/连接表,就像这样createtableperson(per_ident,name,...)createtableperson_links(per_ident,obj_name,obj_r_ident)createtablereport(rep_ident,name,...)其中obj_name是表名,obj_r_ident是标识符。因此链接的报告将按如下方式插入:insertintoperson(1,...)insertintoreport(1,...)insertintoreport(2,...)insertint
我正在创建一个新的Rails3.1应用程序。我希望这个新应用程序重用现有数据库(由以前的Rails2应用程序创建)。我创建了新的应用程序定义模型,它重用了数据库中的一些现有数据。在开发和测试阶段,一切正常,因为它在干净的表数据库上运行,但是当尝试部署到生产环境时,我收到如下消息:PGError:ERROR:column"email"ofrelation"users"alreadyexists***[err::localhost]:ALTERTABLE"users"ADDCOLUMN"email"charactervarying(255)DEFAULT''NOTNULL但是我在迁移中有这
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果