目录
mdk531安装
链接:https://pan.baidu.com/s/1ttrDhv6kXgAvPiYINf9iGw
提取码:1234
注册器
链接:https://pan.baidu.com/s/1T11pBKpD6xc-cNmXBskcaw
提取码:1234
支持包
链接:https://pan.baidu.com/s/1a7UDSVeLC4ktHNN9lV9oIA
提取码:1234
通过以上链接下载mdk和注册器,点击安装mdk,根据提示自行更改软件路径和支持包路径,填写完注册信息后NEXT,等待安装。安装完成,点击Finish。
1.点击运行注册器程序。
2.在桌面找到keil软件图标,点击右键,以管理员身份运行。
3.点击File–>Lincense Management–>Single-User Lincense,找到CID,复制CID中的内容填写到注册器的CID空白处,将注册器中Target选择为ARM,点击Generate,得到注册码。
4.将生成的注册码复制粘贴到Keil的New Lincense ID Code空白处,点击Add LIC,点击Close。
点击运行下载的支持包,NEXT开始安装,安装完成,点击Finish。
点击【project】,选择【new uvision project】创建新项目。


选择芯片,这里选择的是STM32F103VE,然后点击OK。
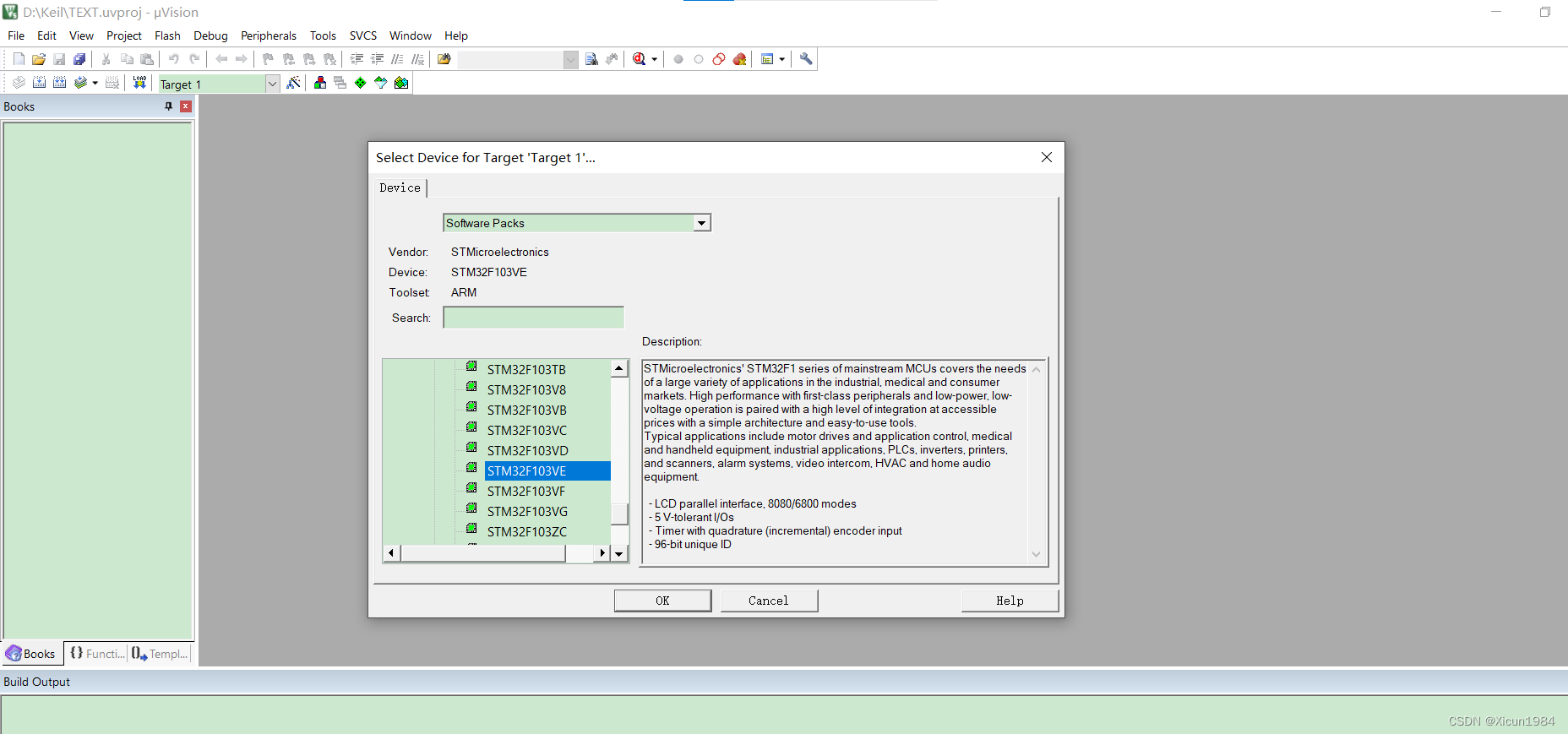
CMSIS下选择CORE,Device下选择Startup,选择完后点击OK。

右击 Source Group 1 ,点击 Add New Item to Group ‘Source Group 1’…

选择文件类型,这里我们点击 Asm Files (.s) 添加汇编文件,然后输入文件名text,并点击 Add。
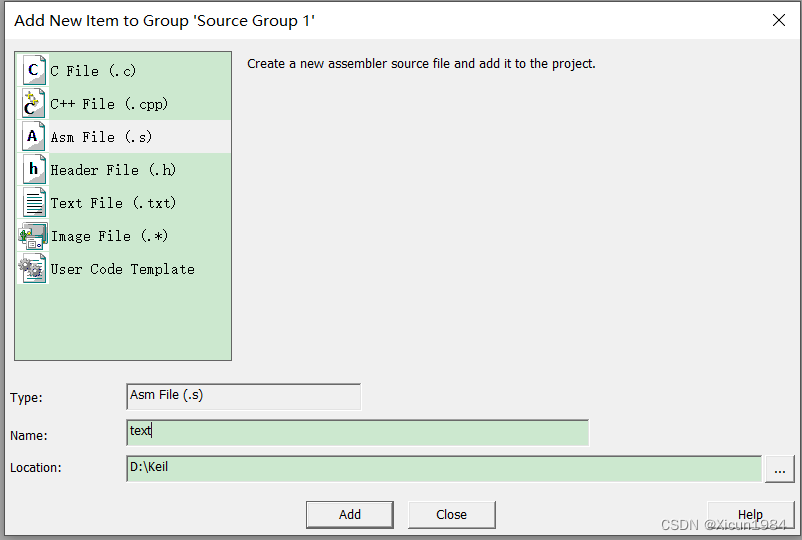
在test.s里面添加以下代码:
AREA MYDATA, DATA
AREA MYCODE, CODE
ENTRY
EXPORT __main
__main
MOV R0, #10
MOV R1, #11
MOV R2, #12
MOV R3, #13
;LDR R0, =func01
BL func01
;LDR R1, =func02
BL func02
BL func03
LDR LR, =func01
LDR PC, =func03
B .
func01
MOV R5, #05
BX LR
func02
MOV R6, #06
BX LR
func03
MOV R7, #07
MOV R8, #08
BX LR先进行一些初始设置,点击 Options for Target…, 在Output界面下,勾选 Create HEX File,才能生成 hex 文件;在 Debug界面下,勾选 Use Simulator,因为在后面我们要进行虚拟调试,后OK 保存设置。

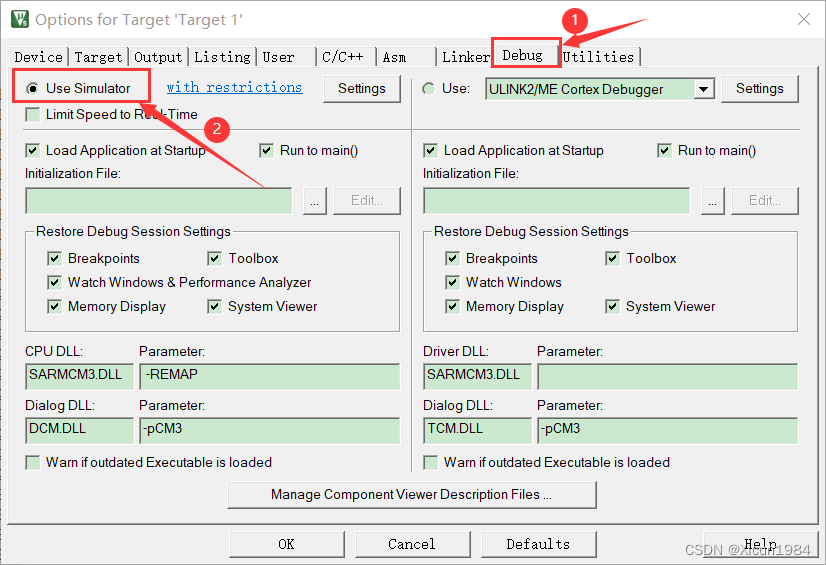
设置Debug选项下面的“Dialog DLL"和"TARMSTM.DLL";parameter项改为“-pSTM32F103C8",用于设置支持STM32F103C8的软硬件仿真,点击ok

点击Rebuild进行编译
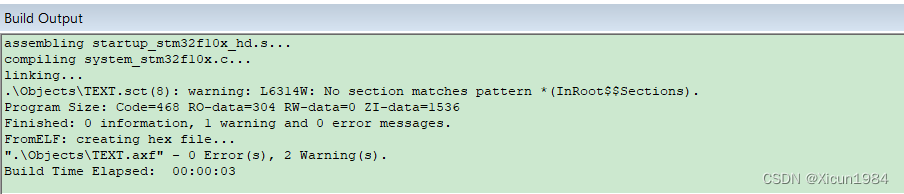
编译成功,没有错误。
点击字母d图标进入调试界面

进入调试状态后,界面与编辑状态相比有明显的变化,Debug菜单项中原来不能用的命令现在已经可以用了,工具栏会多出一个用于运行和调试的工具条,从左到右依次是复位、运行、暂停、单步、过程单步、执行完当前子程序、运行到当前行、下一状态。

按照要求进行单步运行,发现寄存器 R5,R6,R7,R8 的值和程序设置一致:

用记事本打开生成的hex文件,是一串十六进制字符。

扩展线性地址记录(hex 文件的第一排十六进制)也叫作 32 位地址记录或 HEX386 记录,
这些记录包含数据地址的高 16 位。
扩展线性地址记录总是有两个数据字节,外观如下(这里我通过标记方便对应原始数据):
:020000040800F2
| 内容 | 描述 |
| 02 | 这个记录当中数据字节的数量 |
| 0000 | 地址域,对于扩展线性地址记录,这个域总是 0000 |
| 04 | 记录类型 04 (扩展线性地址记录) |
| 0800 | 是地址的高 16 位 |
| F2 | 是这个记录的校验和,计算方法:01h + NOT(02h + 00h + 00h + 04h + 08h + 00h) |
当一个扩展线性地址记录被读取,存储于数据域的扩展线性地址被保存,它被应用于从 Intel HEX 文件读取来的随后的记录。
线性地址保持有效,直到它被另外一个扩展地址记录所改变。
通过把记录当中的地址域与被移位的来自扩展线性地址记录的地址数据相加获得数据记录的绝对存储器地址。
Intel HEX 由任意数量的十六进制记录组成。每个记录包含 5 个域,它们按一定格式排列::llaaaatt[dd…]cc
每一组字母对应一个不同的域,每一个字母对应一个十六进制编码的数字
每一个域由至少两个十六进制编码数字组成,它们构成一个字节,就像以下描述的那样:
| 内容 | 描述 |
| : | 每个Intel HEX记录都由冒号开头 |
| ll | 数据长度域,它代表记录当中数据字节(dd)的数量 |
| aaaa | 地址域,它代表记录当中数据的起始地址 |
| tt | 代表HEX记录类型的域,它可能是以下数据当中的一个:00(数据记录)、01(文件结束记录)、02(扩展段地址记录)、04(扩展线性地址记录) |
| dd | 数据域,它代表一个字节的数据。一个记录可以有许多数据字节.记录当中数据字节的数量必须和数据长度域(ll)中指定的数字相符 |
| cc | 校验和域,它表示这个记录的校验和(校验和的计算是通过将记录当中所有十六进制编码数字对的值相加,以256为模进行以下补足) |
在文件的最后一排,是一个文件的结束标志::00000001FF
| 内容 | 描述 |
| 00 | 记录的长度为 0 |
| 0000 | LOAD OFFSET为0000 |
| 01 | TYPE = 01 |
| FF | 校验和为FF |
这个是一个 END OF FILE RECORD,标识文件的结尾。
通过本次搭建虚拟仿真让我更加了解到Keil的大致功能,此次实验仿真过程中遇到了很多问题,但是通过参考其他大佬的博客以及百度帖子还是基本完成了实验要求,达到了本次实验的目的。希望在以后能更加深入学习Keil相关知识。
搭建并配置Keil嵌入式开发环境,完成一个基于STM32汇编程序的编写_镜仔吃柠檬的博客-CSDN博客
https://blog.csdn.net/ssj925319/article/details/111868500
https://blog.csdn.net/u010632165/article/details/106481146
https://blog.csdn.net/beready/article/details/24668529
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',