目录
在C51中对变量进行定义的格式如下:
【存储种类】数据类型 【存储器类型】 变量名列表;
其中存储种类和存储器类型是可选项,当变量名列表中的变量不止一个时,用逗号隔开。
存储种类:4种
自动(auto),外部(extern),静态(static)和寄存器(register)
存储器类型:6种
DATA区、BDATA区、IDATA区、PDATA区、XDATA区、CODE区 指明该变量所处的内存空间
存储模式: 3种
SMALL、COMPACT和LARGE 指明了变量在没有指明存储器类型时默认的存储区域
当变量的生命周期结束时,它所占的内存单元也就被释放。定义变量时省略存储种类,则该变量默认为自动变量。
例: add()
{int i=10;
……
}
main()
{……
add();在调用add()子函数时为i分配内存单元,调用结束后变量i所占用的内存被释放。
……
}假设一个变量在函数体外或别的程序中已被定义过,并且在本函数体内要使用该变量,则该变量要在本函数体内用extern 说明。用extern定义的变量称为外部变量。外部变量被定义后,在程序的执行过程中都是有效的。
用static定义的变量称为静态变量。静态变量在程序调用结束后其占用的内存单元并不被释放(其值保持不变)。
用register声明的变量称为寄存器变量。该类变量速度最快,应该存放使用频率最高的变量。通常C51编译器会自动识别程序中使用频率最高的变量,并自动将其作为寄存器变量,程序员无需专门声明。
变量的存储种类和存储器类型是不一样的。存储器类型指明该变量所处的内存空间。单片机内部有程序存储器和数据存储器。数据存储器又分为片内存储器和片外存储器。而片内存储器又分为低128字节和SFR特殊功能寄存器。
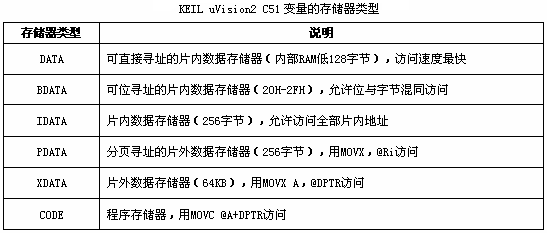
使用不同的存储器类型,程序会有不同的执行效率,在编写C51程序时,推荐指定变量的存储器类型,这样有利于提高程序的执行效率。
若省略存储器类型,编译器将根据使用的存储器模式(SMALL,COMPACT,LARGE)来规定默认的存储器类型。
该区速度最快,所以应该存放使用频率最高的变量。但是该区资源有限,除了存放变量外,还包含堆栈和寄存器组。一旦该区资源不够,会使程序发生莫名其妙的错误。
变量定义举例: char data i[10];
在该区定义的变量,可以进行位寻址,并且可以声明位变量。它可以单独使用变量的某一位,而不一定要用位变量名引用位变量。
例如:
unsigned char bdata status;
if(status^5)
{
…………
}注意该区不允许定义float类型的变量。
该区使用寄存器间接寻址,可以存放使用比较频繁的变量。变量定义举例: float idata var;
该区只有一页即256字节,具体哪一页有P2口指定。使用MOVX指令进行数据传送。
变量定义举例: long PDATA var
该区和PDATA区类似,只是空间增大了——64KB。对XDATA的寻址比对PDATA的寻址要慢(前者需要装入16位地址,而后者只需要装载8位地址)。进行数据传送时同样需要使用MOVX指令。
变量定义举例:unsigned char XDATA i;
该区为程序存储器,代码区中的数据一旦写入不可擦除不可重写。在该区中一般存放数据表,跳转向量和状态表等。变量定义举例:
变量定义举例:unsigned char CODE da[3]={0x04,0x58,0x56};
对于片外扩展I/O口,则要根据其硬件译码地址,将其视为片外数据存储器的一个单元,在程序的开始位置使用#define 定义:
例:
#define <absacc.h>
#define PORTA XBYTE[0x8003]
/*将PORTA定义为外部I/O口,其地址为0x8003*/,长度为一个字节。
存储模式指明了变量在没有指明存储器类型时默认的存储区域,共有:SMALL、COMPACT和LARGE三种。
所有的缺省变量,参数都存储在内部RAM中,优点:存储速度快,执行效率高。缺点:内部RAM有限,只适合小程序。
所有缺省变量都存储在外部RAM的一页(256字节)中。具体哪一页可有P2口指定,该模式空间较SMALL模式充裕,速度较SMALL模式慢,较LARGE模式快,是一种中间模式。
所有参数变量都放在片外数据存储器中,容量大,但速度慢。
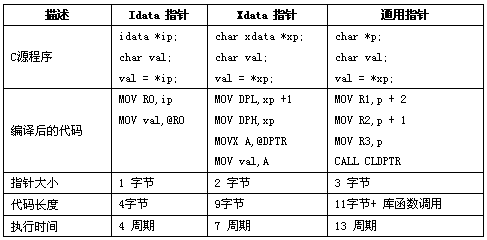
C51编译器支持两种不同类型的指针:存储器指针和通用指针
通用或未定型的指针的声明和标准C语言中一样。
如 : char *s; /* string ptr */
int *numptr; /* int ptr */
long *state; /* long ptr */
通用指针总是需要三个字节来存储,第一个字节是用来表示存储
器类型,第二个字节是指针的高字节,第三字节是指针的低字节

存储类型部分代表了该指针所指向的变量的存储器类型,存储类型的代码如下表所示:

通用指针可以用来访问所有类型的变量,而不管变量存储在哪个存储空间中,因而许多库函数都使用通用指针。通用指针很方便,但是也很慢,在所指向目标的存储空间不明确的情况下它们用的最多。
存储器指针或类型确定的指针,在定义时包括一个存储器类型说明,并且总是指向此说明的特定存储器空间,例如:
char data *str; /* ptr to string in data */
int xdata *numtab; /* ptr to int(s) in xdata */
long code *powtab; /* ptr to long(s) in code */
正是由于存储器类型在编译时已经确定,通用指针中用来表示存储器类型的字节就不再需要了。指向idata、data、bdata和pdata的存储器指针用一个字节保存,指向code和xdata的存储器指针用两个字节保存,使用存储器指针比通用指针效率要高,速度要快。
存储器指针与通用指针实例比较
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我正在编写一个简单的静态Rack应用程序。查看下面的config.ru代码:useRack::Static,:urls=>["/elements","/img","/pages","/users","/css","/js"],:root=>"archive"map'/'dorunProc.new{|env|[200,{'Content-Type'=>'text/html','Cache-Control'=>'public,max-age=6400'},File.open('archive/splash.html',File::RDONLY)]}endmap'/pages/search.