
🌇个人主页:_麦麦_
📚今日名言:“你若爱,生活哪里都可爱。你若恨,生活哪里都可恨。你若感恩,处处可感恩。你若成长,事事可成长。不是世界选择了你,是你选择了这个世界。既然无处可躲,不如傻乐。既然无处可逃,不如喜悦。既然没有净土,不如静心。既然没有如愿,不如释然。”
——丰子恺《豁然开朗》

目录
小伙伴们好呀,今天为大家带来的是动态内存的相关知识,主要围绕动态内存管理相关函数和常见错误并伴有一定的题目练习,希望能够为读者们带来一定的收获。
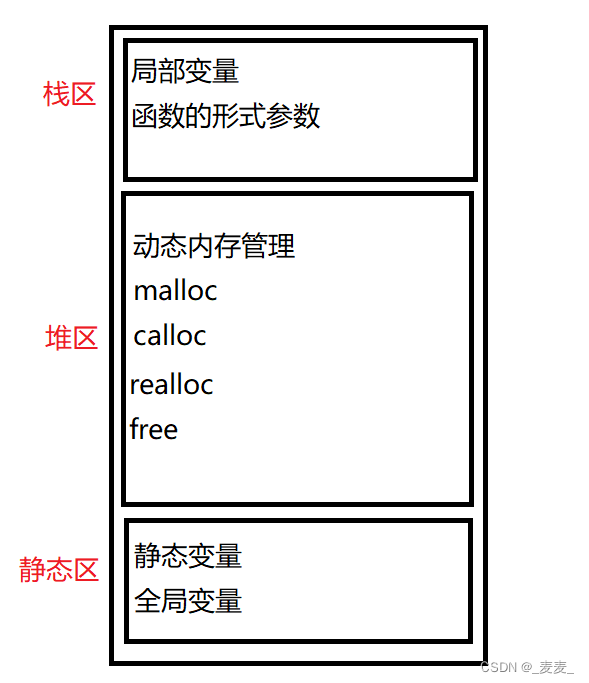
在具体讲解动态内存管理之前,需要先给小伙伴们铺垫一下内存空间的分布(简略版)。在之前的学习中,我们认识了局部变量,全局变量等,那它们在内存中处于何种位置呢?
在内存中可以粗略地分为三大块:栈区、堆区和静态区。栈区中存放的大多是一些局部变量,函数的形式参数;而我们下面所要学习的与动态内存管理相关的函数则存在与堆区;最后的静态区则存放静态变量与全局变量。
在了解完大致的内存分布后,接下来就是动态内存管理了。我们都知道无论是创建一个整形变量亦或是一个指定大小的数组,都是需要向内存申请相应大小的空间,也就是在内存里开辟空间。而目前我们已经掌握的内存开辟方式有:
int val = 20; //在栈空间上开辟四个字节
char arr[20] = { 0 }; //在栈空间上开辟10个字节的连续空间我们会上述的开辟空间的方式有两个特点:
1.空间开辟大小是固定的
2.数组在申明的时候,必须指定数组的长度,它所需要的内存在编译的时候进行分配
但是对于空间的需求,不仅仅是上述的情况,有时候我们所需要的空间大小在程序运行的时候才能知道,那么采用数组的编译时就开辟空间的这种方式就不能满足这种需求。这个时候,就只能试试动态内存开辟了。
而C语言正好提供了与动态内存开辟相关的函数,下面就即将展开相关函数的学习。
void* malloc(size_t size);这个函数是向内存申请一块连续可用的空间,并返回指向这块空间的指针
●引用的头文件:<stdlib.h>
●如果开辟成功,则返回一个指向开辟好空间的指针
●如果开辟失败,则返回一个指向NULL指针,因此malloc的返回值一定要做检查
●返回的类型是void*,所以malloc函数并不只知道开辟空间的类型,具体在使用的时候由使用者自己来决定
●如果参数size为0,malloc的行为是标准未定义的,取决于编译器
下面演示一下malloc函数的简单使用:
//malloc函数使用示例
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main()
{
//申请40个字节,用来存放10个整型
int* p = (int*)malloc(40);
if (p == NULL)
{
printf("%s\n", strerror(errno));
return 1;
}
//存放1-10
int i = 0;
for (i = 0; i < 10; i++)
{
*(p + i) = i + 1;
}
//打印
for(i = 0; i < 10;i++)
{
printf("%d ", *(p + i));
}
return 0;
}
注:当申请完空间后要再主动地返回空间,虽然程序结束操作系统会自动回收,但是如果程序一直不结束,那么这部分空间就会一直被闲置,那么如何回收呢?
void free (void * ptr);C语言中提供了另外一个函数free,专门是用来做动态内存的释放和回收的。free函数用来释放动态内存开辟的内存。
●如果参数ptr指向的空间不是动态开辟的,那free函数的行为是未定义
●如果参数ptr是NULL指针,则函数什么事都不做
#include <string.h>
int main()
{
//申请40个字节,用来存放10个整型
int* p = (int*)malloc(40);
if (p == NULL)
{
printf("%s\n", strerror(errno));
return 1;
}
//存放1-10
int i = 0;
for (i = 0; i < 10; i++)
{
*(p + i) = i + 1;
}
//打印
for(i = 0; i < 10;i++)
{
printf("%d ", *(p + i));
}
//free是释放申请的内存
free(p);
return 0;
}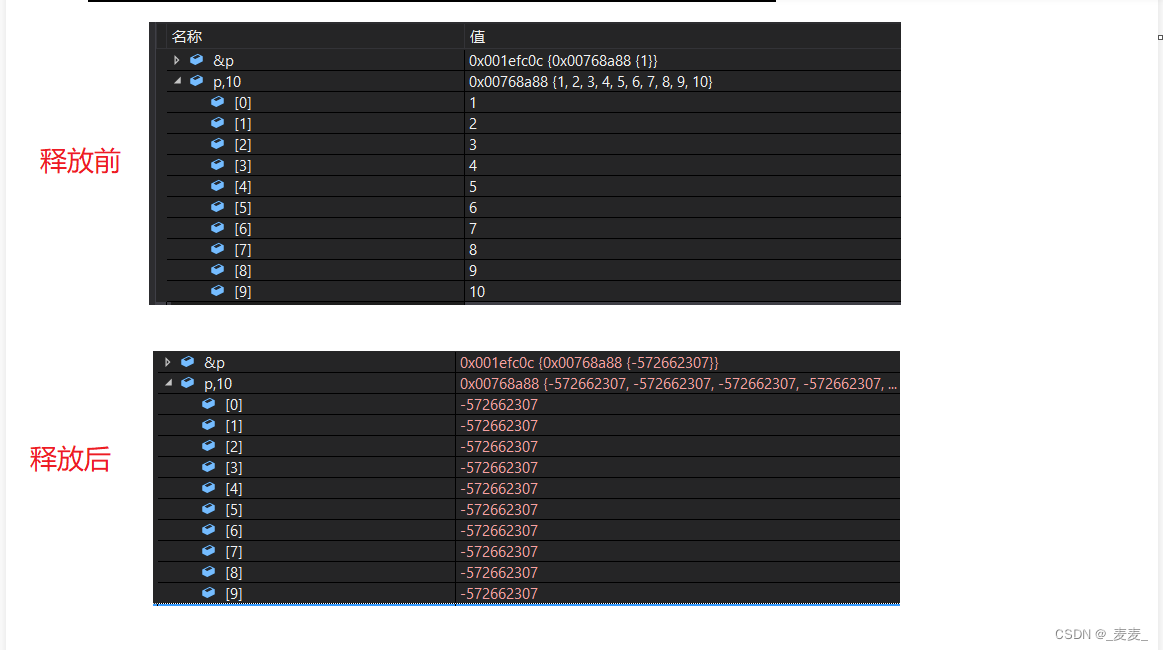
但是我们发现虽然我们已经用free释放了申请的空间,但是p仍存储着指向我们所申请的空间的地址,也就是存在非法访问的的风险,所以一般情况下,当我们使用free释放动态内存之后,还要将指向那块空间的指针置空。
//malloc函数使用示例
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main()
{
//申请40个字节,用来存放10个整型
int* p = (int*)malloc(40);
if (p == NULL)
{
printf("%s\n", strerror(errno));
return 1;
}
//存放1-10
int i = 0;
for (i = 0; i < 10; i++)
{
*(p + i) = i + 1;
}
//打印
for(i = 0; i < 10;i++)
{
printf("%d ", *(p + i));
}
//free是释放申请的内存
free(p);
p = NULL;
return 0;
}void * calloc(size_t num,size_t size);除了malloc之外,C语言还提供了一个函数叫calloc,calloc函数也用来动态内存分配
●calloc的功能是为num个大小为size的元素开辟空间,并且把空间的每个字节初始化为0
●calloc与malloc的区别只在于在calloc会在返回地址之前把申请的空间的每个字节初始化全0
#include <stdlib.h>
int main()
{
int* p = calloc(10, sizeof(int));
if (NULL!=p)
{
//使用空间
}
free(p);
p = NULL;
}
那么在开辟动态内存空间的时候在mallo和calloc两个函数中该如何选择呢?主要是根据自己的需求来考虑。
●malloc无需初始化直接返回地址——效率比较高
●calloc会自动初始化为0
void * realloc(void * ptr, size_t size);●realloc函数的出现让动态内存管理更加灵活
●有时我们会发现过去申请的空间太小了,有时候我们又会觉得申请的空间过大了,那为了合理的使用内存,我们一定会对内存的大小做灵活的调整,那relloc函数就可以做到对动态开辟内存大小的调整
下面具体来认识下realloc函数
●ptr是要调整的内存地址
●size为调整之后新的大小
●返回值为调整之后的内存其实位置
●这个函数在调整原内存大小的基础上,还会将原来内存中数据移动到新的空间
●ralloc在调整内存空间的时候存在两种情况:
(1)原有空间之后有足够大的空间
(2)原有空间之后没有足够大的空间
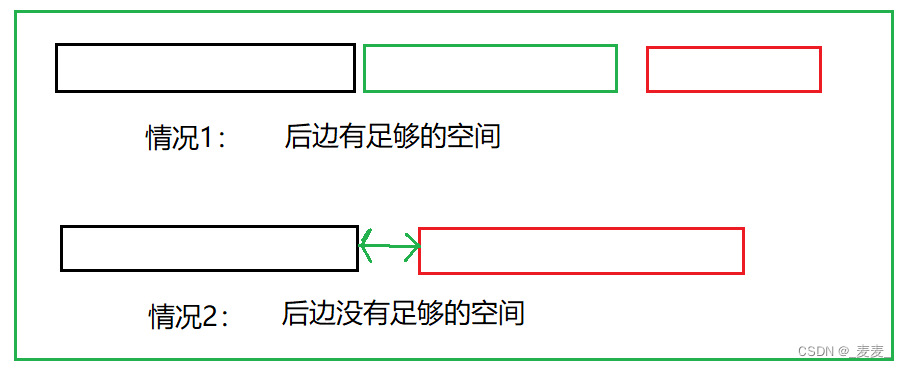
那么realloc会如何处理这两种情况呢?
情况1:当是情况1的时候,要扩展内存就直接原有内存之后直接追加空间,原来空间的数据不发生变化,返回的是原有的起始地址
情况2:当是情况2的时候,原有空间之后没有足够多的空间时,拓展的方法是:在对科技上另找一个合适大小的连续空间来使用,这样的话函数返回的是一个新的内存地址
由于上述的两种情况,当我们使用realloc函数就和之前有一些区别。那么具体该如何使用,具体代码如下:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
//realloc的使用方式1
int main()
{
int* p = (int*)malloc(5 * sizeof(int));
if (NULL == p)
{
perorr("malloc");
return 1;
}
//使用
int i = 0;
for (i = 0; i < 5; i++)
{
*(p + i) = 1;
}
//不够了,增加5个整型的空间
p=realloc(p, 10 * sizeof(int));
//继续使用空间
for (i = 0; i < 10; i++)
{
printf("%d ", *(p + i));
}
//释放空间
free(p);
p = NULL;
return 0;
}
//realloc的使用方式2
int main()
{
int* p = (int*)malloc(5 * sizeof(int));
if (NULL == p)
{
perorr("malloc");
return 1;
}
//使用
int i = 0;
for (i = 0; i < 5; i++)
{
*(p + i) = 1;
}
//不够了,增加5个整型的空间
int* ptr = realloc(p, 10 * sizeof(int));
if (ptr != NULL)
{
p = ptr;
}
//继续使用空间
for (i = 0; i < 10; i++)
{
printf("%d ", *(p + i));
}
//释放空间
free(p);
p = NULL;
ptr = NULL;
return 0;
}第一次使用的小伙伴在使用realloc函数的时候很有可能就是按照第一种方式来写的,而第一种方式和第二种方式的区别在于对realloc函数返回的指针的接受方法不同。前者是直接用第一次开辟的空间的指针来接受,而后者则是使用了一个新指针来接受返回的指针。
那么到底哪种方式更好呢,在认识到realloc函数返回的不同情况下,方式2是一种更好的情况。若是采取方式1,一旦realloc函数扩容失败,就会返回一个空指针,而且会把原来的指针置空,相当于把原来的数据丢失了,可以说是很危险的一种情况,而方式2恰恰避免了这种情况。
在掌握了动态内存函数的使用方法之后,可能有的小伙伴在后续的书写中还会遇到代码错误的问题,以下列举了在使用动态内存函数会出现的常见错误,来帮助大家更好的规避错误,写出优秀的代码。
//对NULL指针的解引用操作
void text1()
{
int* p = (int*)malloc(INT_MAX / 4);
*p = 20;//如果p的值是NULL,就会有问题
free(p);
}//对动态开辟空间的越界访问
void text2()
{
int i = 0;
int* p = (int*)malloc(10 * sizeof(int));
if (NULL == p)
{
exit(EXIT_FAILURE);
}
for (i = 0; i <= 10; i++)
{
*(p + i) = i; //当i是10的时候越界访问
}
free(p);
p = NULL;
}//对非动态开辟内存使用free释放
void text3()
{
int a = 0;
int* p = &a;
free(p); //释放错误
}//使用free释放一块动态开辟内存的一部分
void text4()
{
int* p = (int*)malloc(100);
p++;
free(p); //p不在指向动态内存的起始位置
p = NULL;
}//对同一块动态内存多次释放
int main()
{
int* p = (int*)malloc(100);
if (NULL == p)
{
return 1;
}
//使用
//释放
free(p);
//..
free(p);
return 0;
}//动态开辟内存忘记释放(内存泄漏)
void text()
{
int* p = (int*)malloc(100);
//使用
//......
}
int main()
{
text();
//..
return 0;
}在这种情况下,一旦第一次忘记释放,第二想再释放都释放不了,除非程序结束自动释放。那么有什么好的方法来避免上述情况吗?
//第一层保障:malloc和free成对使用
void text()
{
int* p = (int*)malloc(100);
if (NULL == p)
{
return 1;
}
//使用
free(p);
p = NULL;
}
int main()
{
text();
//....
return 0;
}
//第二层:将指向动态开辟内存的指针返回去,谁接受谁后面去释放,所以这种函数一定要写注释
int* text()
{
int* p = (int*)malloc(100);
if (NULL == p)
{
return 1;
}
//使用
return p;
}到此为止,关于动态内存管理的讲解就已完成一部分了。
关注我 _麦麦_分享更多干货:_麦麦_的博客_CSDN博客-领域博主
大家的「关注❤️ + 点赞👍 + 收藏⭐」就是我创作的最大动力!谢谢大家的支持,我们下期见!
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
我想用这两种语言中的任何一种(最好是ruby)制作一个窗口管理器。老实说,除了我需要加载某种X模块外,我不知道从哪里开始。因此,如果有人有线索,如果您能指出正确的方向,那就太好了。谢谢 最佳答案 XCB,X的下一代API使用XML格式定义X协议(protocol),并使用脚本生成特定语言绑定(bind)。它在概念上与SWIG类似,只是它描述的不是CAPI,而是X协议(protocol)。目前,C和Python存在绑定(bind)。理论上,Ruby端口只是编写一个从XML协议(protocol)定义语言到Ruby的翻译器的问题。生

