读完本文你将收获:
一个mp4文件通常由音频和视频两部分组成(当然有些还包含字幕和一些自定义的信息),音频或视频数据:一段在时间上相关联的sample序列(sample:对于视频而言是一帧压缩后的图像数据(如264/h265数据包),对于音频而言是:一小段语音信号采样编码后的数据(aac编码数据包)),我们将这种sample序列定义为一个track,于是就有了video track和audio track的说法。
一段数据协议通常由两部分组成:HEADER + DATA,其中Header一般具有一种固定的格式,它的作用是描述其后的Data部分。例如我们熟知的TCP/IP协议,MP4协议也不外如是。mp4协议定义了一种称之为Box的数据结构,一个mp4文件就是一个个Box拼接而成,如下图所示。解析MP4文件其实就是对Box的读取和解析。

Box结构其本质上也是HEADER+DATA的模式 ,如下图所示:

其中前4个字节用来表示Box的大小(size)(包括了header和data),紧接着4个字节用来表示Box类型(type),由于size字段4个字节的限制,当其后的data内容很大时,可能会超出size字段所能表示的范围,此时size字段将会被设置为1,如果一个Box的size == 1,则会在type字段后补充8个字节的空间用于表示该Box的大小;size字段还有可能是0,它表示该Box的内容一直到文件结束。对于有些box,可能还会有一些扩展数据存放入header中,一般用16个字节来存放,header数据后跟着的就是Box的data部分,其大小是header中size字段或者largesize字段所表示的大小减去其header自身所占用的大小。
下面是标准协议文档对Box的语法定义
aligned(8) class Box (unsigned int(32) boxtype, optional unsigned int(8)[16] extended_type) {
unsigned int(32) size;
unsigned int(32) type = boxtype;
if (size==1) {
unsigned int(64) largesize;
} else if (size==0) {
// box extends to end of file
}
if (boxtype==‘uuid’) {
unsigned int(8)[16] usertype = extended_type;
}
}
MP4协议文档中定义了很多种类型的Box,从上面的语法中可看出,除去一些超大的Box和一些用户扩展的Box除外,很多Box基本结构其实如下图所示。

基于上面的Box结构,标准协议在其Header基础上扩充了两个字段:1个字节的version字段和3个字节的flags字段;我们将扩充后的Box称之为Full Box,而将没有扩充这两个字段的Box称之为Basic Box, 下面是标准协议对Full box的定义:
aligned(8) class FullBox(unsigned int(32) boxtype, unsigned int(8) v, bit(24) f)
extends Box(boxtype) {
unsigned int(8) version = v;
bit(24) flags = f;
}

注:这里提到的Basic Box和Full Box指的是从数据结构上的一种分类,而下文中提到的不同类型的Box是根据Box中的boxtype字段的不同做的区分,这些不同种类的Box在结构上属于Basic Box或Full Box的一种,这里不要混淆这两个概念。
虽然mp4协议文档中定义了很多种类型的Box,但对于一个mp4文件而言,只需要用到其中的必需的几种box即可,其他的box是为了满足某些特定需求的场景,用户可以根据需求选择性插入。让我们通过工具来概览一下一个mp4文件都需要用到哪些必须的Box吧。

图上展示了多个不同类型的Box,对于一个mp4而言只需要fytyp,moov,mdat这三个Box即可,其中uuid box属于用户自定义box,并不是必须的box。上图中我们还看到moovbox和其他的box似乎稍有不同,它可以展开,是的,对于某些box,其data部分可能是由一个或者多个其他种类的box组成,我们也将这种box称之为Container Box(容器Box),而将组成其Data的Box称为其子Box。
下面让我们来对一个mp4文件中的必需box做一个简要分析吧,看看这些Box到底具备什么功能,又是怎样定义的。
ftypaligned(8) class FileTypeBox extends Box(‘ftyp’) {
unsigned int(32) major_brand;
unsigned int(32) minor_version;
unsigned int(32) compatible_brands[];
}
isom 这个万金油即可。如果是需要特定的格式,可以自行定义。
ftyp box通常位于mp4文件的起始位置,上图是某一个mp4文件的二进制数据,由上图可知该box的大小占用24个字节,type是ftyp, 根据协议定义,ftyp是一个Basic Box,因此除去头部的8个字节剩余16个字节的内容为其data部分:解释如下69 73 6F 6D (ASCII码)==> major_brand :isom
00 00 00 01 ==> minor_version :1
compatible_brands数组(4字节为一个Item),因此有两个
69 73 6F 6D ==> isom
61 76 63 31 ==> avc1
moovaligned(8) class MovieBox extends Box(‘moov’){
}
moov box是一个非常重要的box:主要用来存放描述mp4文件媒体数据的metadata信息,包括视频的宽,高,总时长,音频的采样率,通道数,总时长等,以及如何查找真正的媒体数据信息。moov box是一个容器box,其内容分布到各个子box中。如下图所示:

moov中的子box有很多种,具体可以在文章末尾的表格中查看,下面只针对必需的mvhd,trak这两种box做分析,其他的box如:udta box一般是用户有自己的用途在封装时添加,有兴趣可以自己了解。
mvhdmoovaligned(8) class MovieHeaderBox extends FullBox(‘mvhd’, version, 0) {
if (version==1) {
unsigned int(64) creation_time;
unsigned int(64) modification_time;
unsigned int(32) timescale;
unsigned int(64) duration;
} else { // version==0
unsigned int(32) creation_time;
unsigned int(32) modification_time;
unsigned int(32) timescale;
unsigned int(32) duration;
}
template int(32) rate = 0x00010000; // typically 1.0
template int(16) volume = 0x0100; // typically, full volume
const bit(16) reserved = 0;
const unsigned int(32)[2] reserved = 0;
template int(32)[9] matrix =
{ 0x00010000,0,0,0,0x00010000,0,0,0,0x40000000 };
// Unity matrix
bit(32)[6] pre_defined = 0;
unsigned int(32) next_track_ID;
}
根据标准定义,moov box属于Full Box,其Header部分除了size(4字节),type(4字节)外,还额外包含了version(1字节), flags(3字节)。
| 字段 | 字节数 | 描述 |
|---|---|---|
| version | 1 | 版本,0或者1, version=1时,有些字段采用更大的字节空间定义 |
| flags | 3 | 0 |
| creation_time | 4/8 | 整数,表示文件创建的时间戳,是指从1904-01-01到创建点所经过的秒数 |
| modification_time | 4/8 | 整数,表示文件修改时间戳,解释同上 |
| timescale | 4 | 整数,表示时间粒度,如果是1000,表示1秒被分成1000个粒度,用于下面的duration计算 |
| duration | 4/8 | 整数,媒体文件的总时长,该值需要除以timescale,转换成真正的秒数。例如:timescale = 1000, duration = 5000 ,则媒体文件的总时长为5秒。 |
| rate | 4 | [16,16]格式,前16位表示整数部分,后16位表示小数部分:例如rate =0001 0000,表示rate=1.0,正常速率播放 |
| volume | 2 | [8,8]格式,前8位表示整数,后8位表示浮点数,0x0100 = 1.0,最大音量播放 |
| reserved | 2*4 | 保留字段 |
| matrix | 4*9 | 视频变换矩阵 |
| next_track_ID | 4 | 下一个trackId,当在mp4中需要新插入一个track时,这个track的id。 |
mvhd box从整体上对该mp4文件做了一个信息概述,从这个box我们可以获取到该mp4文件的播放总时长。
下图是从二进制数据手动分析mvhdbox和工具解析对比图:


trakmoovaligned(8) class TrackBox extends Box(‘trak’) {
}

一个mp4媒体是由一个或者多个track组成,如音频track,视频track,每一个track都携带有自己的时间和空间信息,每个track都相互独立于其他track。video track:包含了视频Sample,audio Track包含了audio sample,hint track稍有不同,它描述了一个流媒体服务器如何把文件中的媒体数据组成符合流媒体协议的数据包,如果文件只是本地播放,可以忽略hint track,他们只与流媒体有关。
track有两种用途:a. 包含媒体数据(media tracks)。b.用来存放分包信息,用于流传输协议。(hint track).
在一个标准的mp4文件中,至少应该有一个media track,同时所有有助于hint track的 media track都应该保留在文件中,即使这些media track没有被hint track引用。本文不对hint track进行讨论。
如上图所示:trak box是一个Container box,其内容有由其子box承载,同样我们只分析必要的box:tkhd,mdia,至于其他例如:edts有兴趣的同学可以自行了解。
类型 :tkhd
父容器:trak
是否必须有:必须
数量:必须有一个
aligned(8) class TrackHeaderBox extends FullBox(‘tkhd’, version, flags){
if (version==1) {
unsigned int(64) creation_time;
unsigned int(64) modification_time;
unsigned int(32) track_ID;
const unsigned int(32) reserved = 0;
unsigned int(64) duration;
} else { // version==0
unsigned int(32) creation_time;
unsigned int(32) modification_time;
unsigned int(32) track_ID;
const unsigned int(32) reserved = 0;
unsigned int(32) duration;
}
const unsigned int(32)[2] reserved = 0;
template int(16) layer = 0;
template int(16) alternate_group = 0;
template int(16) volume = {if track_is_audio 0x0100 else 0};
const unsigned int(16) reserved = 0;
template int(32)[9] matrix= { 0x00010000,0,0,0,0x00010000,0,0,0,0x40000000 };
// unity matrix
unsigned int(32) width;
unsigned int(32) height;
}
根据标准定义可知,tkhd box属于Full Box,因此其头部除了size(4B),type(4B)外,还额外包含了version(1B), flag(3B)。
| 字段 | 字节数 | 含义 |
|---|---|---|
| size | 4 | Box大小 |
| type | 4 | Box类型:tkhd |
| version | 1 | box版本:0或1,区别是部分字段的存储空间差异,一下以version=0进行分析 |
| flags | 3 | 按位或操作结果值, 预定义如下:0x000001:Track_enabled,表明该track是可以被播放的,如果最低bit为0,则不能被播放;0x000002:Track_in_movie,表明该track在播放中被引用;0x000004:Track_in_preview表明该track在预览时被引用;一般这个值为7,如果一个媒体的所有track都没有设置Track_in_movie和Track_in_preview,将被理解为所有track均设置了这两项;对于hinttrack,该值为0 |
| creation_time | 4 | track的创建时间 |
| modification_time | 4 | track的修改时间 |
| track_id | 4 | 不能重复,而且不能为0 |
| reserved | 4 | 保留位 |
| duration | 4 | track的时间长度,单位采用的是mvhd box下的timescale |
| reserved | 2*4 | 保留位 |
| layer | 2 | 视频层,默认为0,值小的在上面 |
| alternate_group | 2 | track分组信息,默认为0表示该track不与其他任何track相关, |
| volume | 2 | [8.8]格式,音频track使用,1.0[0100]:表示最大音量,视频track为0[0000] |
| reserved | 2 | 保留位 |
| matrix | 36 | 视频变换矩阵 |
| width | 4 | 视频的宽;音频track为0 |
| height | 4 | 视频的高【16.16】的格式存储;音频track为0 |
从这个box中我们可以获取到MP4的如下信息:
mdiatrakaligned(8) class MediaBox extends Box(‘mdia’) {
}
mdia box是trak下一个非常重要的子box,它也是一个Container box,其内容由其子box承载,mdia box下必须的子box有:mdhd,hdlr,minf如下图所示
类型 :mdhd
父容器:mdia
是否必须有:必须
数量:必须有一个
aligned(8) class MediaHeaderBox extends FullBox(‘mdhd’, version, 0) {
if (version==1) {
unsigned int(64) creation_time;
unsigned int(64) modification_time;
unsigned int(32) timescale;
unsigned int(64) duration;
} else { // version==0
unsigned int(32) creation_time;
unsigned int(32) modification_time;
unsigned int(32) timescale;
unsigned int(32) duration;
}
bit(1) pad = 0;
unsigned int(5)[3] language; // ISO-639-2/T language code
unsigned int(16) pre_defined = 0;
}
这个box能获取的主要信息是:单独的视频或音频的总时长 = duration / timescale。
到目前为止,我们已经能够获取到媒体的总时长,视频的宽高获取,以及音频或者视频的单独时长,那么我们该如何区分当前track是视频track还是音频track呢?这个任务交给了hdlr box。
类型 :hdlr
父容器:mdia
是否必须有:必须
数量:有且只有一个
aligned(8) class HandlerBox extends FullBox(‘hdlr’, version = 0, 0) {
unsigned int(32) pre_defined = 0;
unsigned int(32) handler_type;
const unsigned int(32)[3] reserved = 0;
string name;
}
handler_type: “vide”:表示当前track是video track,“soun”:表示当前track是audio track,“hint”:表示是hint track。
区分出track后,剩下需要针对不同的媒体类型数据,查找到对应的编解码信息,以及如何查找到媒体数据,以及数据包和其关联的时间戳等信息。这些信息都包含在Media Information Box minf 里。
类型 :minf
父容器:mdia
是否必须有:必须
数量:有且只有一个
aligned(8) class MediaInformationBox extends Box(‘minf’) {
}
minf box 顾名思义,是专门用来描述当前track下媒体数据的box,它是一个container box,其内容由其子box来表达,需要注意的是video track和audio track下的一些子box有些不同,看下图对比

类型 :vmhd
父容器:minf
是否必须有:必须
数量:有且只有一个
aligned(8) class VideoMediaHeaderBox
extends FullBox(‘vmhd’, version = 0, 1) {
template unsigned int(16) graphicsmode = 0; // copy, see below
template unsigned int(16)[3] opcolor = {0, 0, 0};
}
类型 :smhd
父容器:minf
是否必须有:必须
数量:有且只有一个
aligned(8) class SoundMediaHeaderBox
extends FullBox(‘smhd’, version = 0, 0) {
template int(16) balance = 0;
const unsigned int(16) reserved = 0;
}
drefminf or metaminf是必须有,对于meta可以没有aligned(8) class DataInformationBox extends Box(‘dref’) {
}
dref box是一个container box,其内容由其子box:‘url或urn box承载。
类型 :url / urn
父容器:dref
是否必须有:必须
数量:有且只有一个
aligned(8) class DataEntryUrlBox (bit(24) flags) extends FullBox(‘url ’, version = 0, flags) {
string location;
}
aligned(8) class DataEntryUrnBox (bit(24) flags) extends FullBox(‘urn ’, version = 0, flags) {
string name;
string location;
}
aligned(8) class DataReferenceBox extends FullBox(‘dref’, version = 0, 0) {
unsigned int(32) entry_count;
for (i=1; i <= entry_count; i++) {
DataEntryBox(entry_version, entry_flags) data_entry;
}
}
MP4媒体数据的物理存放位置不受媒体数据的时间顺序限制,因为读取真实的媒体数据是通过moov中的媒体描述信息来确定的。媒体数据可以包含在同一个或者多个box中,甚至可以在其他文件中,描述信息可以通过url来引用这些文件。但这些媒体数据的排列关系,必须全部包含在 一个主文件的metadata描述里,其他文件不一定是MP4格式,甚至可能就没有Box。
一个track的媒体数据可以被分为若干段,每一段可以根据url或者urn指向地址来获取数据,sample描述中会用这些片段的序号将将这些片段组成一个完整的track,一般情况下,当数据被完全包含在文件中时,url或urn中的定位字符串是空的。
aligned(8) class ChunkOffsetBox extends FullBox(‘stco’, version = 0, 0) {
unsigned int(32) entry_count;
for (i=1; i <= entry_count; i++) {
unsigned int(32) chunk_offset;
}
}
aligned(8) class ChunkLargeOffsetBox extends FullBox(‘co64’, version = 0, 0) {
unsigned int(32) entry_count;
for (i=1; i <= entry_count; i++) {
unsigned int(64) chunk_offset;
}
}
一个mp4文件媒体数据是由一个或多个track组成,而一个track是由一个或多个chunk组成,一个chunk是由一个或多个sample组成。
要读取mp4媒体的sample数据,就需要找到对应的sample在文件中的存储偏移位置。要找到对应的sample在文件中的存储偏移位置,首先要找到其所在chunk在文件中的偏移位置。stco box 给出了每个chunk在mp4文件中的偏移(offset),即每个chunk在文件中的位置。将记录结果存放到chunk_offset表中,如下图:

通过上图,我们可以遍历上面的chunk_offset表找到每一个chunk在文件中的偏移地址。
aligned(8) class SampleToChunkBox extends FullBox(‘stsc’, version = 0, 0) {
unsigned int(32) entry_count;
for (i=1; i <= entry_count; i++) {
unsigned int(32) first_chunk;
unsigned int(32) samples_per_chunk;
unsigned int(32) sample_description_index;
}
}
知道chunk在文件中的偏移位置后,还需要知道sample和chunk之间的关系。mp4协议将连续且具有相同sample_per_chunk和sample_description_index的字段的chunk简化成一个entry,并将这些entry放到一个表里如下图。

first_chunk是每个entry的第一个chunk index,samples_per_chunk表示每个chunk中的sample个数
结合stco box和stsc box 提供的信息,我们知道了以下信息
mp4文件中某个track里的chunk的总数chunk在文件中的偏移位置chunk有多少个sample但是想要完整的读取该track的全部媒体数据,还需要知道每个sample的大小。stsz box记录了每个sample的大小。
aligned(8) class SampleSizeBox extends FullBox(‘stsz’, version = 0, 0) {
unsigned int(32) sample_size;
unsigned int(32) sample_count;
if (sample_size==0) {
for (i=1; i <= sample_count; i++) {
unsigned int(32) entry_size;
}
}
}
如果sample_size不为0,则表示sample_count个数的sample都是sample_size的大小;如果sample_size为0,则表示每个sample具有不同的大小,这些size存储在一张表里
entry_size:对应index的sample的大小

如上图:第一个sample的size是2317,第二个sample的szie是573,sample的总数是:6551
现在我们知道了,该如何读取一个mp4文件中video track下的视频媒体数据了。
video track下的stco/co64 box中的chunk_offset表,找到每个chunk在文件中的偏移位置stsc box中对应chunk有多少个samplestsz表,查找每个sample有多大chunk里的数据,当遍历完chunk_offset表后,当前track下的所有的sample也就被读取了。我们来用video的第一个sample来验证一下,第一帧视频数据存放在第一个trunk的第一个sample中,所以很简单,video track中第一个trunk的偏移量就是第一帧视频数据的偏移量:805293,这里我们打开二进制查看工具和StreamEye进行对比验证
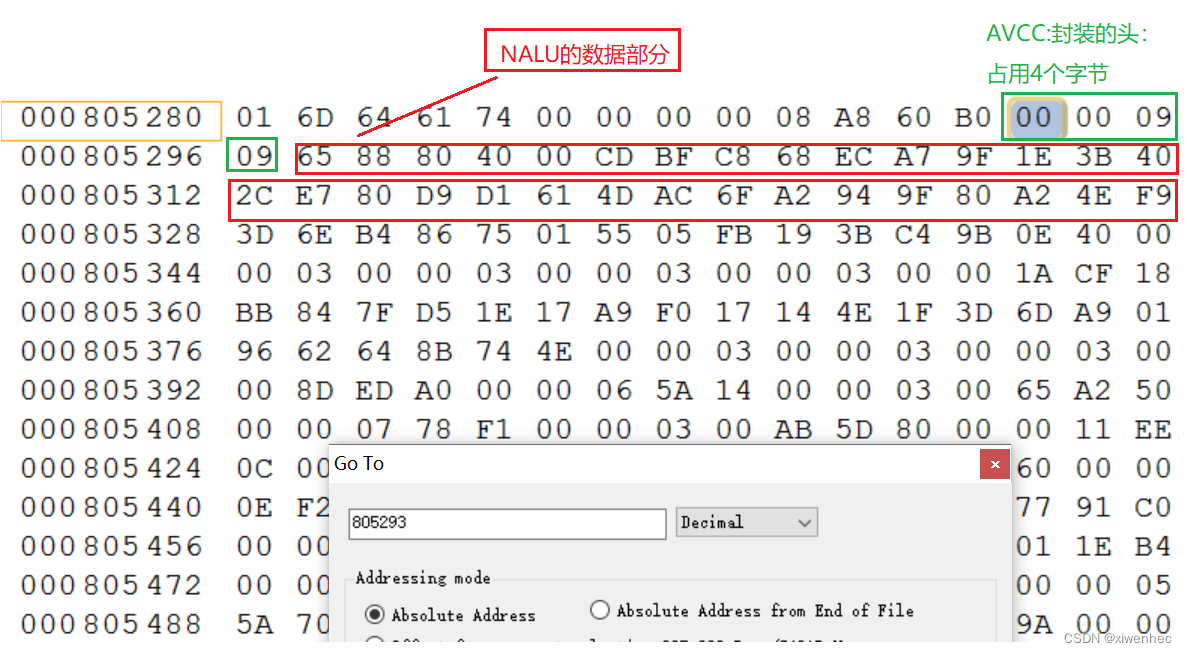
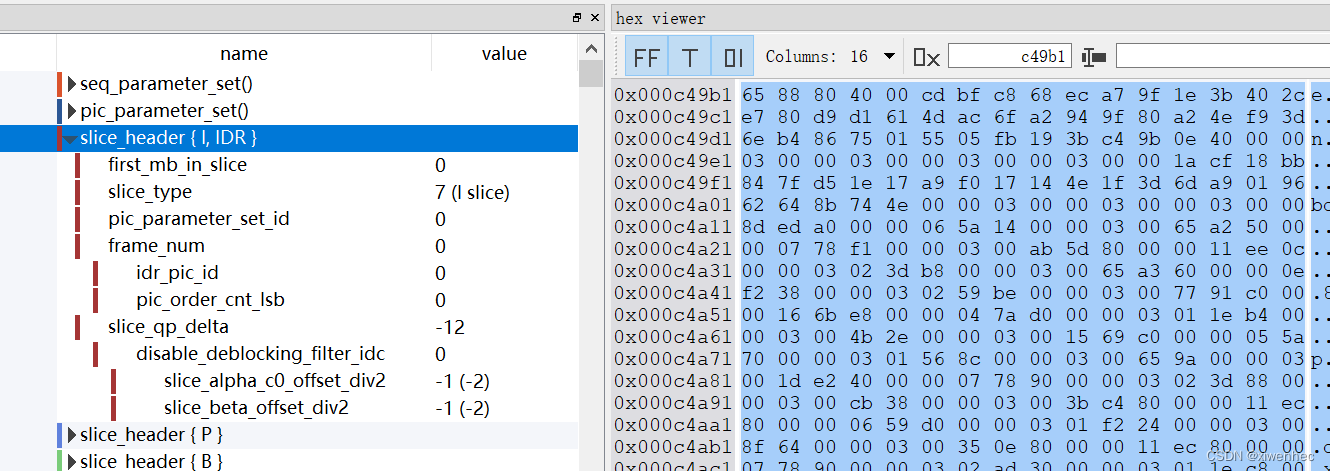
由于我使用的的mp4的视频编码h264采用的是AVCC的封装,因此每个naul前面有4个字节的header,而header后才是真正的nalu的数据,可以看到和工具解析对应的数据是一样的
能够从头按顺序的读取完成一个mp4的媒体数据的全部数据,还远远不够,我们还需要从指定的时间开始读取对应的媒体数据,那么该如何做呢?
MP4文件封装的最终目标就是为了能够再次播放,播放MP4的一个重要任务就是找到每个sample的PTS
DTS(n+1) = DTS(n)+STTS(n)
stts box记录着该sample到下一个sample的DTS间隔:duration,时间粒度是trak->mdia->mdhd->timescale。除了最后一个box外,所有的sample的duration都应该大于0的数值。这样可以保证整体的时间是单调递增的,可以认为是这个sample的持续时间。


上图分别是两个MP4文件的stts box图,对于图一,从第一个sample开始,到第6551个sample,他们的DTS间隔都是2000。
对于图二:解释如下
如果视频编码中没有B帧,则sample的编码输出顺序与图像的输入顺序是一致的,对应到解码时,解码顺序DTS和渲染顺序PTS是一致的,此时PTS等于DTS。如果存在B帧则有些不同,由于B帧会进行双向参考,因此编码器会先编码P5帧接着编码B2,B3,B4帧,这样编码输出的sample的PTS就会出现反转现象,
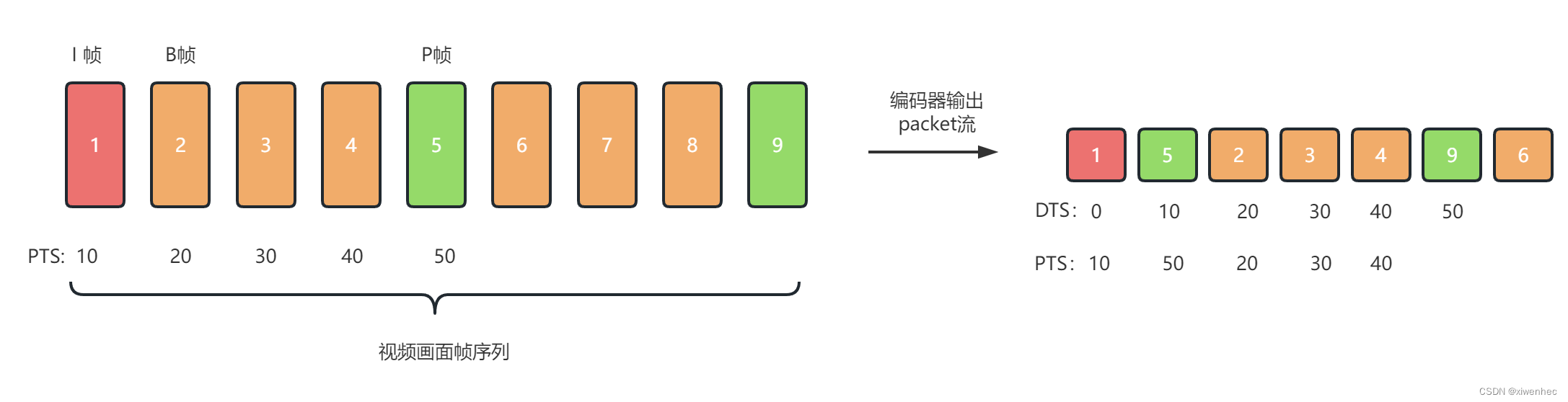
因此如果视频存在B帧,则DTS就不能代表PTS了,我们需要一种方式来计算出每个sample的正确PTS:ctts的作用就是如此,他记录这每个sample的PTS和DTS的差值。
PTS(n) = DTS(n) + CTTS(n)

对于上图的ctts,我们可以这样计算PTS和DTS,一般第一个sample的PTS我们总是习惯其等于0:PTS(1) = 0。
若:stts:都是2000,trak->mdia->mdhd->timescale = 50000
有如下计算:
PTS(1) = DTS(1) + CTTS(1)
=> DTS(1) = - CTTS(1)
=> DTS(1) = -2000;
//换算成微秒
若:trak->mdia->mdhd->timescale = 50000;
则:DTS_us(1) = -2000/50000 * 1000000(us)
=> DTS_us(1) = -40000(us)
DTS(2) = DTS(1) + STTS(1)
=> DTS(2) = -2000 + 2000 = 0;
//换算成微秒后
DTS_us(2) = 0(us)
=>PTS(2) = DTS(2) + CTTS(2)
=>PTS(2) = 0 + 8000 = 8000
//换算成微秒后
PTS_us(2) = 8000/50000 * 1000000 = 160000(us)
...
以此类推,就可以计算出所有的pts
视频track独有,记录关键帧的sample序号
aligned(8) class SyncSampleBox extends FullBox(‘stss’, version = 0, 0) {
unsigned int(32) entry_count;
int i;
for (i=0; i < entry_count; i++) {
unsigned int(32) sample_number;
}
}

entry_count:记录关键帧sample的个数,关键帧sample的序号会存放到一个表里,如上图。视频的第一个sample为关键帧序号为1.
| Box | 是否必须存在 | ||||||
|---|---|---|---|---|---|---|---|
| ftyp | √ | file type and compatibility | |||||
| pdin | progressive download information | ||||||
| moov | √ | container for all the metadata | |||||
| mvhd | √ | movie header, overall declarations | |||||
| trak | √ | container for an individual track or stream | |||||
| tkhd | √ | track header, overall information about the track | |||||
| tref | track reference container | ||||||
| edts | edit list container | ||||||
| elst | an edit list | ||||||
| mdia | √ | container for the media information in a track | |||||
| mdhd | √ | media header, overall information about the media | |||||
| hdlr | √ | handler, declares the media (handler) type | |||||
| minf | √ | media information container | |||||
| vmhd | video media header, overall information (video track only) | ||||||
| smhd | sound media header, overall information (sound track only) | ||||||
| hmhd | hint media header, overall information (hint track only) | ||||||
| nmhd | Null media header, overall information (some tracks only) | ||||||
| dinf | √ | data information box, container | |||||
| dref | √ | data reference box, declares source(s) of media data in track | |||||
| stbl | √ | sample table box, container for the time/space map | |||||
| stsd | √ | sample descriptions (codec types, initialization etc.) | |||||
| stts | √ | (decoding) time-to-sample | |||||
| ctts | (composition) time to sample | ||||||
| stsc | √ | sample-to-chunk, partial data-offsetinformation | |||||
| stsz | sample sizes (framing) | ||||||
| stz2 | compact sample sizes (framing) | ||||||
| stco | √ | chunk offset, partial data-offset information | |||||
| co64 | 64-bit chunk offset | ||||||
| stss | sync sample table (random access points) | ||||||
| stsh | shadow sync sample table | ||||||
| padb | sample padding bits | ||||||
| stdp | sample degradation priority | ||||||
| sdtp | independent and disposable samples | ||||||
| sbgp | sample-to-group | ||||||
| sgpd | sample group description | ||||||
| subs | sub-sample information | ||||||
| mvex | movie extends box | ||||||
| mehd | movie extends header box | ||||||
| trex | √ | track extends defaults | |||||
| ipmc | IPMP Control Box | ||||||
| moof | movie fragment | ||||||
| mfhd | √ | movie fragment header | |||||
| traf | track fragment | ||||||
| tfhd | √ | track fragment header | |||||
| trun | track fragment run | ||||||
| sdtp | independent and disposable samples | ||||||
| sbgp | sample-to-group | ||||||
| subs | sub-sample information | ||||||
| mfra | movie fragment random access | ||||||
| tfra | track fragment random access | ||||||
| mfro | √ | movie fragment random access offset | |||||
| mdat | media data container | ||||||
| free | free space | ||||||
| skip | free space | ||||||
| udta | user-data | ||||||
| cprt | copyright etc. | ||||||
| meta | metadata | ||||||
| hdlr | √ | handler, declares the metadata (handler) type | |||||
| dinf | data information box, container | ||||||
| dref | data reference box, declares source(s) of metadata items | ||||||
| ipmc | IPMP Control Box | ||||||
| iloc | item location | ||||||
| ipro | item protection | ||||||
| sinf | protection scheme information box | ||||||
| frma | original format box | ||||||
| imif | IPMP Information box | ||||||
| schm | scheme type box | ||||||
| schi | scheme information box | ||||||
| iinf | item information | ||||||
| xml | XML container | ||||||
| bxml | binary XML container | ||||||
| pitm | primary item reference | ||||||
| fiin | file delivery item information | ||||||
| paen | partition entry | ||||||
| fpar | file partition | ||||||
| fecr | FEC reservoir | ||||||
| segr | file delivery session group | ||||||
| gitn | group id to name | ||||||
| tsel | track selection | ||||||
| meco | additional metadata container | ||||||
| mere | metabox relation |
MP4在线分析工具:
MP4box.js:https://gpac.github.io/mp4box.js/test/filereader.html
mp4parser:https://www.onlinemp4parser.com/
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta