GTID的主从复制,主库(9900)——》备库(9909),存在测试库表:
9900_db1库:t1、t2、t3、t4、t5表
9900_db2库:t6、t7、t8、t9、t10表
--replicate-do-db=name,只同步指定的数据库,可以使用CHANGE REPLICATION FILTER REPLICATE_DO_DB来创建,比如现在只同步9900_db1库,需要在从库执行:
mysql> stop slave sql_thread;
Query OK, 0 rows affected (0.01 sec)
mysql> change replication filter replicate_do_db=(9900_db1); //(9900_db1,...)可指定多个
Query OK, 0 rows affected (0.01 sec)
mysql> start slave sql_thread;
Query OK, 0 rows affected (0.04 sec)
也可以写入到参数文件永久生效(若要指定多个,需要多次指定该参数)。
此时在主库9900_db2库中的表插入数据的话,将不会同步到备库,在9900_db1库中的表插入数据的话,是可以同步到备库的。
但是需要注意的如下:
①该参数不能再group replication架构中使用,因为可能会使组无法达到一致的状态。
②在binlog为statement格式下(row不会有下面问题):
sql线程会将replicate-do-db限制的数据库为use使用的数据库。
如果在主库执行如下操作,备库将不会复制(不单单是insert,这里只是用insert举例,只要涉及到复制库和未复制库的跨库操作就不会复制):
mysql> use 9900_db2;
Database changed
mysql> insert into 9900_db1.t1(name) values('gg');
Query OK, 1 row affected (0.63 sec)
产生这种行为的原因是:仅通过语句很难判断是否该复制(比如跨库update和delete多个表),如果没有必要,只检查默认库比检查所有库要快。
③在binlog为row格式下,以下操作不会同步到备库:
mysql> use 9900_db1;
Database changed
mysql> insert into 9900_db2.t6(name) values('gg');
Query OK, 1 row affected (0.50 sec)
这个也很好理解,因为没有同步9900_db2即便跨同步的库也没用。
总之,在statement格式下的binlog,只要涉及到同步库和未同步库的跨库操作就不会同步;在row格式下的binlog只要涉及到未同步库的操作,都不会同步。
④以下操作在statement格式下和row格式下有区别:
mysql> use 9900_db1;
Database changed
mysql> update 9900_db1.t1,9900_db2.t6 set 9900_db1.t1.name='aaa',9900_db2.t6.name='bbb' where 9900_db1.t1.name='aa' and 9900_db2.t6.name='bb';
Query OK, 2 rows affected (3.23 sec)
Rows matched: 2 Changed: 2 Warnings: 0
使用的是replicate-do-db指定的库,在binlog为statement格式下会同步到备库,如果不是使用的replicate-do-db库的话将不会同步。
使用的是replicate-do-db指定的库,在binlog为row格式下不论是不是使用的replicate-do-db库,都会只同步9900_db1的操作。
总之,修改操作涉及到同步的库和未同步的库的时候,在binlog为statement格式下如果使用的是(这里使用指的是use dbname)同步的库操作都会同步到备库,如果使用未同步的库的话操作不会同步;在row格式的binlog下无论使用的哪个库都只会同步,replicate-do-db指定的库的操作。
2、replicate-ignore-db参数:
--replicate-ignore-db=name,不同步指定的数据库,可以使用CHANGE REPLICATION FILTER REPLICATE_DO_DB来创建,和replicate-do-db一样,不过多解释了。
这里CHANGE REPLICATION FILTER REPLICATE_IGNORE_DB=(9900_db1);
需要注意的如下:
①该参数不能再group replication架构中使用,因为可能会使组无法达到一致的状态。同replicate-do-db。
②在binlog为statement格式下,只要use的是replicate-ignore-db的数据库那么将不会复制到备库,use的其他数据库是可以复制到备库的,比如如下操作是可以被复制的,因为use的不是replicate-ignore-db库:
mysql> use 9900_db2;
Database changed
mysql> update 9900_db1.t1 set name='a' where name='aa'; //因为这里是显示指定的9900_db1库基于statement格式下不会进行过滤。
Query OK, 1 row affected (1.03 sec)
Rows matched: 1 Changed: 1 Warnings: 0
在binlog为row格式下,无论use的是不是ignore的数据库,都不会更新ignore库中的表。
其实和replicate-do-db大同小异只不过这里是不同步的库。
对于上面的④步中的:
如果为statement格式的话,use的是ignore库,那么不会同步ignore库中的表,其他的表可以同步;如果use的不是ignore库,那么都会同步。
如果为row格式的话,无论use的是不是ignore的库,都不会同步ignore库中的表的操作。
3、replicate-do-table参数:
--replicate-do-table=db_name.tbl_name,只同步指定的表,可以使用CHANGE REPLICATION FILTER REPLICATE_DO_TABLE=(9900_db1.t1,9900_db2.t6);进行过滤,也可写入到参数文件,如果要过滤多个表的话,需要指定多次该参数。
测试指定的是只同步9900_db1.t1,9900_db2.t6这两个表,replicate-do-table指定该参数后不管use的是哪个数据库都会进行同步(和binlog格式无关),测试如下:
mysql> use 9900_db1;
Database changed
mysql> update 9900_db1.t1 set name='a' where name='aa';
Query OK, 1 row affected (1.02 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> use 9900_db2; //使用其他数据库也是如此
Database changed
mysql> update 9900_db1.t1 set name='aa' where name='a';
Query OK, 1 row affected (1.10 sec)
Rows matched: 1 Changed: 1 Warnings: 0
如果像1中的④进行多个更新,也是无论use哪个数据库都会进行更新(不分binlog格式)。当更新操作中既包含db table表又包含不能同步的表时,statement格式时都会同步到备库,但是如果备库不存在其他表的话主从将会报错(与use数据库无关);row格式的时候备库只同步db table的表(与use数据库无关)。
4、replicate-ignore-table参数:
--replicate-ignore-table=db_name.tbl_name,不同步指定的表,可以使用CHANGE REPLICATION FILTER REPLICATE_IGNORE_TABLE=(9900_db1.t1,9900_db2.t6);进行过滤,也可写入到参数文件,如果要过滤多个表的话,需要指定多次该参数。
测试指定的是不同步9900_db1.t1,9900_db2.t6这两个表,replicate-ignore-table指定该参数后不管use的是哪个数据库都不会进行同步,测试如下:
mysql> use 9900_db1;
Database changed
mysql> update 9900_db1.t1 set name='a' where name='aa';
Query OK, 1 row affected (1.17 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> use 9900_db2;
Database changed
mysql> update 9900_db1.t1 set name='a' where name='aa';
Query OK, 1 row affected (1.09 sec)
Rows matched: 1 Changed: 1 Warnings: 0
如果像1中的④进行多个更新,也是无论use哪个数据库备库都不会进行更新(不分binlog格式)。对于操作中包含既然包含ignore table表又包含可以同步的表的时候,那么在statement格式下replicate-ignore-table指定的表和可以同步的表都不会同步(与use数据库无关);在row格式下replicate-ignore-table指定的表不同步外其他的表示可以同步的(与use数据库无关)。
5、replicate-wild-do-table参数:
--replicate-wild-do-table=db_name.tbl_name,只同步指定的表,可以包含%和_通配符,它们与LIKE模式匹配操作符的含义相同。可以使用CHANGE REPLICATION FILTER REPLICATE_WILD_DO_TABLE=('9900_db1.t1','9900_db2.t6')进行过滤(注意库名表名的引号),也可以写入参数文件如果不使用通配符等的话,想要同步多个表,需要在参数文件写多次。
测试指定的是只同步9900_db1.t1,9900_db2.t6这两个表,replicate-wild-do-table指定该参数后不管use的是哪个数据库都会进行同步(和binlog格式无关),测试如下:
mysql> use 9900_db1;
Database changed
mysql> update 9900_db1.t1 set name='a' where name='aa';
Query OK, 1 row affected (1.02 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> use 9900_db2; //使用其他数据库也是如此
Database changed
mysql> update 9900_db1.t1 set name='aa' where name='a';
Query OK, 1 row affected (1.10 sec)
Rows matched: 1 Changed: 1 Warnings: 0
如果像1中的④进行多个更新,也是无论use哪个数据库都会进行更新(不分binlog格式)。当更新操作中既包含db table表又包含不能同步的表时,statement格式时都会同步到备库,但是如果备库不存在其他表的话主从将会报错(与use数据库无关);row格式的时候备库只同步db table的表(与use数据库无关)。
replicate-wild-do-table和replicate-do-table效果是一样的,不同的是replicate-wild-do-table可以使用通配符等。
该选项适用于表、视图和触发器,不适用于存储过程和函数等事件。
例如:replication -wild-do-table=foo%.Bar%.只复制使用数据库名称以foo开头、表名称以Bar开头的表的更新。如果表名模式是%,那么它将匹配任何表名。
该选项不适用隐式更新表,比如授权语句grant会隐式更新mysql.user表,备库不受该参数限制。
6、replicate-wild-ignore-table参数:
--replicate-wild-ignore-table=db_name.tbl_name,不同步指定的表,可以使用CHANGE REPLICATION FILTER REPLICATE_WILD_IGNORE_TABLE=('9900_db1.t1','9900_db2.t6');进行过滤,也可写入到参数文件,如果要过滤多个表的话,需要指定多次该参数。
测试指定的是不同步9900_db1.t1,9900_db2.t6这两个表,replicate-wild-ignore-table指定该参数后不管use的是哪个数据库都不会进行同步( 和binlog格式无关),测试如下:
mysql> use 9900_db1;
Database changed
mysql> update 9900_db1.t1 set name='a' where name='aa';
Query OK, 1 row affected (1.17 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> use 9900_db2;
Database changed
mysql> update 9900_db1.t1 set name='a' where name='aa';
Query OK, 1 row affected (1.09 sec)
Rows matched: 1 Changed: 1 Warnings: 0
如果像1中的④进行多个更新,也是无论use哪个数据库备库都不会进行更新(和binlog格式无关)。对于操作中包含既然包含ignore table表又包含可以同步的表的时候,那么在statement格式下replicate-wild-ignore-table指定的表和可以同步的表都不会同步(与use数据库无关);在row格式下replicate-ignore-table指定的表不同步外其他的表示可以同步的(与use数据库无关)。
因为row格式的binlog中将语句拆分了两个:
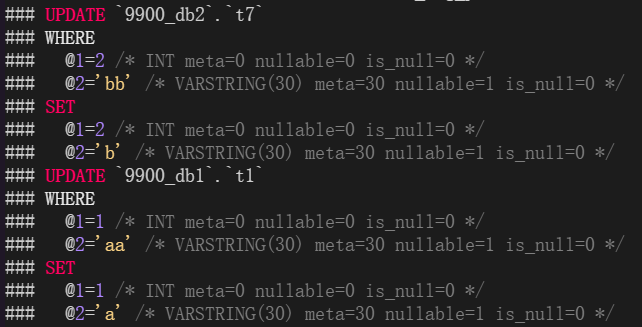
replicate-wild-ignore-table和replicate-ignore-table效果是一样的,不同的是replicate-wild-ignore-table可以使用通配符等。
例如:replication-wild-ignore-table=foo%.Bar%.不会复制使用数据库名称以foo开头、表名称以Bar开头的表的更新。如果表名模式是%,那么它将匹配任何表名。
该选项不适用隐式更新表,比如授权语句grant会隐式更新mysql.user表,备库不受该参数限制。如果需要过滤掉GRANT语句或其他管理语句,可能的解决方法是使用--replication-ignore-db参数。
例如:
USE nonreplicated;
GRANT SELECT, INSERT ON replicated.t1 TO 'someuser'@'somehost';
上面的语句序列会导致GRANT语句被忽略。
7、replicate-rewrite-db:
--replicate-rewrite-db=from_name->to_name将主库的数据库名from_name转换为从库的to_name,要指定多个需要多次使用该参数,或者写入参数文件,例如:
mysqld --replicate-rewrite-db="olddb->newdb"
也可以通过CHANGE REPLICATION FILTER REPLICATE_REWRITE_DB来创建。
这里使用主库的9900_db1和从库的test:CHANGE REPLICATION FILTER REPLICATE_REWRITE_DB=((9900_db1,test));
对于binlog为statement和row格式该参数的效果是不同的:
①statement格式下,需改语句中指定库名(比如update dbname.tblname)这样的话无论use的哪个库都不会同步到test库(如果备库也有和主库同名的库9900_db1,那么会同步到该库),如果语句中不指定库名,use 参数指定的主库的库名(也就是9900_db1)的话直接写表名更新是可以同步到备库test库的。
②row格式下,无论use的是哪个库,也无论更新的时候有没有指定库名,都会同步到备库的test库,而如果备库中9900_db1库也不会同步。
DDL的话不论binlog格式如何,都是根据use的库来进行的,也就是说,指定库名(比如update dbname.tblname)这样的话无论use的哪个库都DDL不会同步到test库(如果备库也有和主库同名的库9900_db1,那么会同步到该库),有可能sql thread会报错;如果语句中不指定库名,use 参数指定的主库的库名(也就是9900_db1)的话直接写表名更新是可以同步到备库test库的。
为确保重写产生预期的结果,尤其是与其他复制筛选选项结合使用时,请在使用选项--replicate-rewrite-db时遵循以下建议:
①在源和具有不同名称的副本上手动创建from_name 和 to_name 数据库。
②如果您使用基于语句的或混合的二进制日志记录格式,请不要使用跨数据库查询,也不要在查询中指定数据库名称。对于 DDL 和 DML语句,都依赖use语句指定的当前数据库,并且在查询中仅使用table名
③如果仅对 DDL 语句使用基于row格式的binlog,依靠use语句指定当前数据库,并且在查询中使用table名,对于DML语句,可以根据需要使用完全限定的table名(db.table)。
如果遵循这些 建议,则可以安全的将--replicate-rewrite-db选项与table级复制过滤选项(例如--replicate-do-table)结合使用。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test