目录
很早之前,在我刷leetcode的时候遇见使用哈希表的题目,我怀着好奇心去搜索,发现C语言可以用数组简单模拟(但是key值超过数组最大范围那就不行了),但是写了一篇关于简单哈希表运用的文章
数组模拟哈希表的简单运用![]() https://blog.csdn.net/Dusong_/article/details/127257647?spm=1001.2014.3001.5502
https://blog.csdn.net/Dusong_/article/details/127257647?spm=1001.2014.3001.5502
但是用数组仅限于key为整型(int),但是如果key是一个自定义类型,就不能用数组模拟了
头文件:
#include "uthash.h"uthash是一个C语言的hash表实现。它以宏定义的方式实现hash表,不仅加快了运行的速度,而且与key类型无关的优点
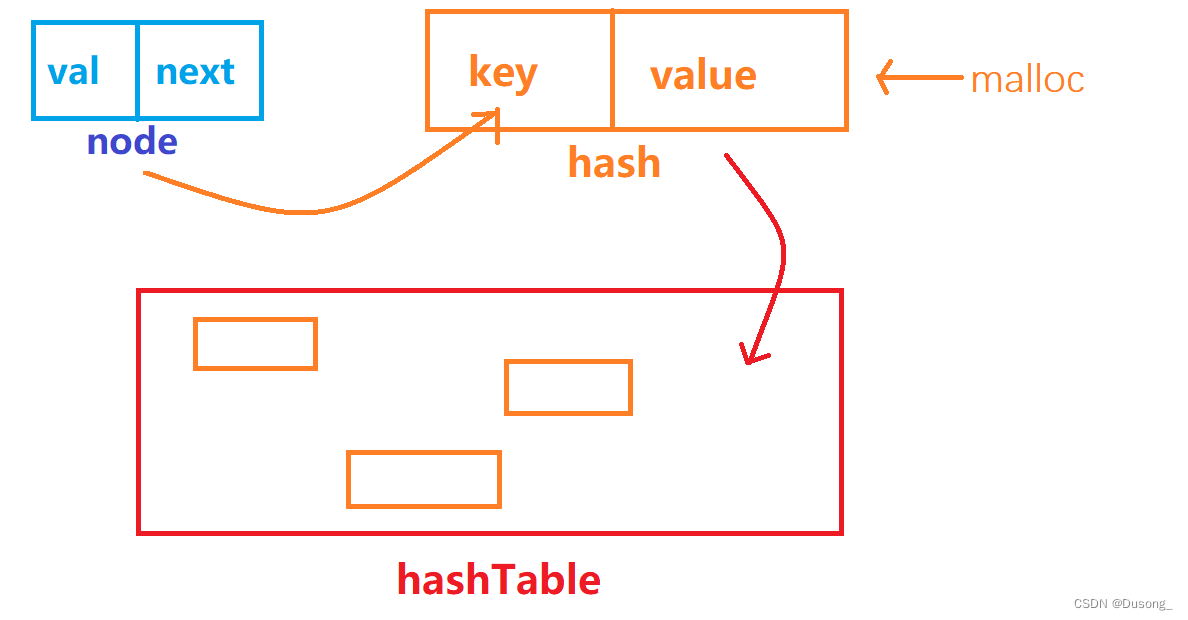
在使用之前需要定义这样一个结构体:
struct HashTable {
struct ListNode *key; /*以链表一节点为例*/
int value;
UT_hash_handle hh;
};• hh是内部使用的hash处理句柄,在使用过程中,只需要在结构体中定义一个UT_hash_handle类型的变量即可,不需要为该句柄变量赋值,但必须在该结构体中定义该变量。
• Uthash所实现的hash表中,可以通过结构体成员hh的hh.prev和hh.next获取当前节点的上一个节点和下一个节点
struct HashTable* hash;
hash = NULL;struct ListNode *node= head;
hash = (struct HashTable*)malloc(sizeof(struct HashTable));
hash->key = node;
HASH_ADD(hh, hashTable, key, sizeof(struct HashTable *), hash);
hh: 可以将其理解为固定参数
hashTable: 最开始初始化的哈希表指针
key: 自定义的结构体中的key
sizeof(struct HashTable *) : 计算哈希结构体大小即一个键值对的大小
hash: 新创建的键值对,将其加入hashTable中
struct ListNode *node= head; /*在哈希表中查找node节点*/
struct HashTable *ret = NULL; /*用于接收函数返回的指针*/
HASH_FIND(hh, hashTable, &node, sizeof(struct HashTable *), ret);
if (ret != NULL) {
/*已找到*/
}&node: 该参数及作为key,在hashTable中查找这个节点,需要查找key的地址,所以需要用&。
ret: 如果查找到,则将指向这个键值对的指针返回到ret中,如果没有查找到则返回NULL;
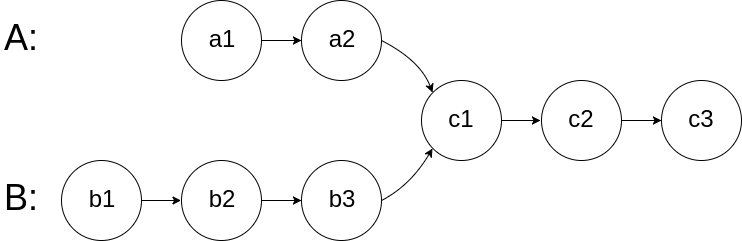
输入两个链表,找出它们的第一个公共节点。
如下面的两个链表:
在节点 c1 开始相交。
特别注意:这道题中所说的相交并不能仅用两链表节点的值相等来判断,这样是错的,相交是指节点的地址相同。
直接将链表A中的所有结点存入哈希表中,在从头到尾遍历链表B,查找哈希表中对应的结点即可
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct HashTable {
struct ListNode* key;
UT_hash_handle hh;
};
struct ListNode* getIntersectionNode(struct ListNode* headA, struct ListNode* headB) {
struct HashTable* hashTable = NULL;
struct ListNode* tmp = headA;
//将链表A的结点加入哈希表
while (tmp) {
struct HashTable* k_v = (struct HashTable*)malloc(sizeof(struct HashTable));
k_v->key = tmp;
HASH_ADD(hh, hashTable, key, sizeof(struct HashTable*), k_v);
tmp = tmp->next;
}
//在哈希表中查找结点
tmp = headB;
while (tmp) {
struct HashTable* ret = NULL;
HASH_FIND(hh, hashTable, &tmp, sizeof(struct HashTable*), ret);
if (ret) {
return tmp;
}
tmp = tmp->next;
}
return NULL;
}给定一个整数数组
nums和一个整数目标值target,请你在该数组中找出 和为目标值target的那 两个 整数,并返回它们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9 输出:[0,1] 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
思路:
本题需要返回两个能凑成target的数的下标,用双指针是很容易想到的但是时间复杂度为O(n^2),
跟着代码注释走,你会发现用哈希表非常巧妙,时间复杂度为O(n);
struct HashTable {
int key; /*数值作为key*/
int value; /*数的下标作为value*/
UT_hash_handle hh;
};
int* twoSum(int* nums, int numsSize, int target, int* returnSize) {
struct HashTable* hash = NULL; /*创建哈希表指针*/
int* res = (int*)malloc(sizeof(int) * 2);
*returnSize = 2;
for (int i = 0; i < numsSize; i++) { /*遍历整个数组*/
struct HashTable* ret = NULL; /*接收查找后的返回值*/
int key = target - nums[i];
HASH_FIND_INT(hash, &key, ret); /*在哈希表中查找target - nums[i]*/
//如果没有查找到,则将nums[i]作为key加入哈希表中
if (ret == NULL) {
struct HashTable* num = (struct HashTable*)malloc(sizeof(struct HashTable));
num->key = nums[i];
num->value = i;
HASH_ADD_INT(hash, key, num);
//如果找到,则找到这两个数
} else {
res[0] = ret->value;
res[1] = i;
}
}
return res;
}总结下来就是,在哈希表中查找target - nums[i] 的数是否存在
该题查找的是指针形式的字符串,需要用HASH_FIND_KEYPTR,形如
struct HashTable {
char* key;
int val;
UT_hash_handle hh;
};若key是字符数组,查找则用HASH_FIND_STR
struct HashTable {
char key[20];
int val;
UT_hash_handle hh;
};给定一个单词列表
words和一个整数k,返回前k个出现次数最多的单词。返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
示例 1:
输入: words = ["i", "love", "leetcode", "i", "love", "coding"], k = 2 输出: ["i", "love"] 解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。 注意,按字母顺序 "i" 在 "love" 之前。
struct HashTable {
char* key;
int val;
UT_hash_handle hh;
};
struct HashTable* hash;
int FindVal (struct HashTable* hash, char* s) { //排序时,找到字符串在哈希表中对应的val
struct HashTable* tmp = NULL;
HASH_FIND_STR(hash, s, tmp);
return tmp == NULL ? 0 : tmp->val;
}
int cmp(char** s1, char** s2) {
int val1 = FindVal(hash, *s1);
int val2 = FindVal(hash, *s2);
if (val1 == val2) {
return strcmp(*s1,*s2); //出现次数相等时,按字典序排
} else {
return val2 -val1; //排倒序
}
}
char ** topKFrequent(char ** words, int wordsSize, int k, int* returnSize){
hash = NULL;
for (int i = 0; i < wordsSize; i++) { //遍历words
struct HashTable* tmp = NULL;
HASH_FIND_STR(hash, words[i], tmp); //查找字符串key
if (tmp) {
tmp-> val++;
} else {
struct HashTable* word = (struct HashTable*)malloc(sizeof(struct HashTable));
word->key = words[i];
word->val = 1;
/*当结构体中的键值为字符串数组时,使用HASH_ADD_STR。键值为字符串指针时使用HASH_ADD_KEYPTR*/
HASH_ADD_KEYPTR(hh, hash, word->key, strlen(word->key), word); //添加键值对
}
}
char** ret = (char**)malloc(sizeof(char*)*HASH_COUNT(hash)); //HASH_COUNT计算键值对的个数
*returnSize = 0;
struct HashTable* tmp = NULL;
for (tmp = hash; tmp != NULL; tmp = tmp->hh.next) { //遍历哈希表
ret[(*returnSize)++] = tmp->key;
}/*
struct HashTable *iter, *tmp;
HASH_ITER(hh, cnt, iter, tmp) {
ret[(*returnSize)++] = iter->key;
}*/
qsort(ret, *returnSize, sizeof(char*), cmp); //将整个数组排倒序,结果返回前k个
*returnSize = k;
return ret;
}
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用
假设我有一个在Ruby中看起来像这样的哈希:{:ie0=>"Hi",:ex0=>"Hey",:eg0=>"Howdy",:ie1=>"Hello",:ex1=>"Greetings",:eg1=>"Goodday"}有什么好的方法可以将它变成如下内容:{"0"=>{"ie"=>"Hi","ex"=>"Hey","eg"=>"Howdy"},"1"=>{"ie"=>"Hello","ex"=>"Greetings","eg"=>"Goodday"}} 最佳答案 您要求一个好的方法来做到这一点,所以答案是:一种您或同事可以在六个月后理解