假设有6个类别,L为10个真实标签的取值,P为对应的预测的标签值,先计算对应的n(类别数,这里假设为6)xL+P:

bin的值一定是分类数的平方。混淆矩阵先将真实标签和预测标签抻成一维向量,做一个对应关系(nxL+P),再将这个对应的一维向量抻成二维矩阵,如下图,很奇妙地将真实值与预测值之间的像素点对应起来了。

如上图示例,混淆矩阵要表达的含义:
若类别数n为2,则混淆矩阵可表示为下面的形式:

True Positive(TP):真正类。样本的真实类别是正类,并且模型识别的结果也是正类。
False Negative(FN):假负类。样本的真实类别是正类,但是模型将其识别为负类。
False Positive(FP):假正类。样本的真实类别是负类,但是模型将其识别为正类。
True Negative(TN):真负类。样本的真实类别是负类,并且模型将其识别为负类。
从混淆矩阵当中,可以得到更高级的分类指标:Accuracy(精确率),Precision(正确率或者准确率),Recall(召回率),Specificity(特异性),Sensitivity(灵敏度)。
我们假设总共有k+1个类(从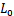 到
到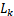 ,包括一个void class 或 background),
,包括一个void class 或 background),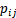 表示的类别i被推断为类别j的像素量。
表示的类别i被推断为类别j的像素量。
2.1 准确率(Accuracy):精确率是最常用的分类性能指标。可以用来表示模型的精度,即模型识别正确的个数/样本的总个数。一般情况下,模型的精度越高,说明模型的效果越好。是针对原来的所有样本而言的。
Accuracy=(TP+TN)/(TP+FN+FP+TN)
2.2 精确率(Precision):又称为查准率,表示在模型识别为正类的样本中,真正为正类的样本所占的比例。一般情况下,查准率越高,说明模型的效果越好。大白话为“你预测为正例的里面有多少是对的”,是针对预测结果而言的。
precision = TP/(TP+FP)
2.3 召回率(Recall):又称为查全率,召回率表现出在实际正样本中,分类器能预测出多少。表示的是,模型正确识别出为正类的样本的数量占总的正类样本数量的比值。一般情况下,Recall越高,说明有更多的正类样本被模型预测正确,模型的效果越好。是针对原来的正样本而言的。
Recall(召回率) = Sensitivity(敏感指标,True Positive Rate,TPR)= 查全率
Recall = TP/(TP+FN)
查准率和查全率是一对矛盾的指标。一般来说,查准率高时,查全率旺旺偏低;二查全率高时,查准率往往偏低。
2.4 特异度(Specificity):特异性指标,表示的是模型识别为负类的样本的数量,占总的负类样本数量的比值。
Specificity = TN/(TN +FP)
负正类率(False Positive Rate, FPR),计算公式为:FPR=FP/(TN+FP),计算的是模型错识别为正类的负类样本占所有负类样本的比例,一般越低越好。
Specificity = 1 - FPR
2.5 Fβ_Score:Fβ的物理意义就是将正确率和召回率的一种加权平均,在合并的过程中,召回率的权重是正确率的β倍。
F1分数认为召回率和正确率同等重要,F2分数认为召回率的重要程度是正确率的2倍,而F0.5分数认为召回率的重要程度是正确率的一半。比较常用的是F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。
F1_Score:数学定义为 F1分数(F1-Score),又称为平衡 F分数(Balanced Score),它被定义为正确率和召回率的调和平均数。在 β=1 的情况,F1-Score的值是从0到1的,1是最好,0是最差。
2.6 ROC曲线&AUC
ROC曲线作用:评价一个值分类器的优劣,在敏感度和特异度之间找一个平衡
ROC曲线特点:正负样本分布发生变化或阈值选取发生变化时, ROC曲线不会随之发生变化
横轴表示1 - 特异度,记为x(t);纵轴表示敏感度,记为y(t)。 t为阈值,对应图中的V,即图中表示当t=0.49时的ROC曲线
真正率(TPR) = 灵敏度 = TP/(TP+FN)
假正率(FPR) = 1- 特异度 = FP/(FP+TN)
注意:我们发现TPR和FPR分别是基于实际表现1和0出发的,也就是说它们分别在实际的正样本和负样本中来观察相关概率问题。正因为如此,所以无论样本是否平衡,都不会被影响。举个例子,总样本中,90%是正样本,10%是负样本。我们知道用准确率是有水分的,但是用TPR和FPR不一样。TPR只关注90%正样本中有多少是被真正覆盖的,而与那10%毫无关系,同理,FPR只关注10%负样本中有多少是被错误覆盖的,也与那90%毫无关系,所以可以得出:如果我们从实际表现的各个结果角度出发,就可以避免样本不平衡的问题了,这也是为什么选用TPR和FPR作为ROC/AUC的指标的原因。

1 - 特异度 = FP/(TN+FP) :健康人中有多少被预测为有 病,越低越好
敏感度 = TP / (TP + FN):有病的样本中有多少被预测为有病,越高越好
两者相互抑制,敏感度越大越好,1-特异度越小越好
ROC曲线中的四个点:
(0,0)表示都无病
(1,0)结果最差,即有病的样本全部预测为无病,无病的样 本全部预测为有病
(0,1)结果最好,即有病的样本全部预测为有病,无病的样 本全部预测为无病
(1,1)表示都有病
ROC曲线越靠近(0,1)点越好,越偏离中心斜45度线越
AUC是ROC曲线下面积大小,取值范围[0,1],越大越好
AUC含义:随机选取一对正负样本,正样本得分 > 负样本得分的概率
AUC特点:不随正负样本分布的改变而改变,不随阈值的改变而改变。分类器需要给定阈值,如阈值为0.5时,表示分类结果>0.5的样本为正样本,<0.5的样本为负样本。阈值的选取会影响基础指标,如Acc等是可以通过改变阈值(超参)找到最优解的。
2.7 Pixel Accuracy(PA):即像素精度。标记正确的像素占总像素数的比例。
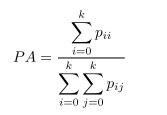
2.8 Mean Pixel Accuracy(MPA):即均类像素精度。每个类被正确标记的像素个数的比例,再求所有类的平均。

2.9 Intersection over Union(IoU):即交并比。真实和预测的交集/真实和预测的并集,图像分割面向的是真实掩码和预测掩码的交集和并集。求出来不是一个数,而是类别数目个数,每个类别算出来一个数。也称为Jaccard相似系数(Jaccard similarity coefficient)。而Jaccard distance的值则等于(1-Jaccard系数)。
2.10 Mean Intersection over Union(MIoU):即平均交并比。该指标是各种基准数据集最常用的标准之一,绝大多数的图像语义分割论文中的模型评估比较都以此作为主要评估指标。IoU是计算每个类别的,这里求其平均。

2.11 Frequency Weighted Intersection over Union(FWIoU):即频率权重交并比。是对原始 MIoU 的改进,它会根据每个分类出现的频率,对每个类给予不同权重。

2.12 dice similarity coefficient (dice)系数:传统的分割任务中,IOU是一个很重要的评价指标,而在三维医学图像分割领域,大部分的paper和项目采用dice系数来评价模型性能。

从混淆矩阵中,可以衍生出各种评价的指标。如下是截取的wiki上的一个截图

参考:
[机器学习笔记] 混淆矩阵(Confusion Matrix)
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
电脑上可以截取图片吗?如果可以,该如何操作呢?相信很多小伙伴都只知道一两种截图的方式,知道的并不全面。其实,电脑上有多种方式截图的,而且非常方便。电脑怎么截图?今天我们就来教大家如何使用电脑截取图片的8种常用方式!操作环境:演示机型:Delloptiplex7050系统版本:Windows10方法一:系统自带截图具体操作:同时按下电脑的自带截图键【Windows+shift+S】,可以选择其中一种方式来截取图片:截屏有矩形截屏、任意形状截屏、窗口截屏和全屏截图。 方法二:QQ截图具体操作:在电脑登录QQ,然后同时按下【Ctrl+Alt+A】,可以任意截图你需要的界面,可以把截图的页面直接下载,
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
我刚刚开始按照包括AlexOtt在内的各种指南设置cedet。这是我的init文件中目前的内容。(require'cedet)(semantic-load-enable-code-helpers);;imenubreaksifIdon'tenablethis(global-semantic-highlight-func-mode1)(global-semantic-tag-folding-mode)我非常喜欢代码折叠,因为语义比hideshow等包更了解代码我想对ruby进行相同的折叠。我知道cedet还可以做其他事情,但我现在只是试一试。所以我在contrib/文件夹中看到了wi
gemspec语义版本控制运算符~>(又名twiddle-wakka,又名pessimistic运算符)允许限制gem版本但允许进行一些升级。我经常看到它可以读作:"~>3.1"=>"Anyversion3.x,butatleast3.1""~>3.1.1"=>"Anyversion3.1.x,butatleast3.1.1"但是有了一个数字,这条规则就失效了:"~>3"=>"Anyversionx,butatleast3"*NOTTRUE!*"~>3"=>"Anyversion3.x"*True.Butwhy?*如果我想要“任何版本3.x”,我可以只使用“~>3.0”,这是一致的。就
1.Scenes游戏场景文件夹用于放置unity的场景文件 2.Plugins插件文件夹用于放置unity的依赖文件,例如dll 3.Scripts脚本文件夹用于放置unity的c#脚本文件 4.Resources游戏资源文件夹用于放置unity的各种游戏资源,比如images,prefabs,同时只有放到Resources文件夹的游戏资源才能使用Resource.load(资源路径不加后缀)加载到游戏内存中进行使用 5.EditorUnity编辑器扩展脚本文件夹usingUnityEditor;这个名称空间就是Unity编辑器的名称空间这个名称空间提供了扩展Unity编辑器的各种类 【你所有
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
HTTP缓存是指浏览器或者代理服务器将已经请求过的资源保存到本地,以便下次请求时能够直接从缓存中获取资源,从而减少网络请求次数,提高网页的加载速度和用户体验。缓存分为强缓存和协商缓存两种模式。一.强缓存强缓存是指浏览器直接从本地缓存中获取资源,而不需要向web服务器发出网络请求。这是因为浏览器在第一次请求资源时,服务器会在响应头中添加相关缓存的响应头,以表明该资源的缓存策略。常见的强缓存响应头如下所述:Cache-ControlCache-Control响应头是用于控制强制缓存和协商缓存的缓存策略。该响应头中的指令如下:max-age:指定该资源在本地缓存的最长有效时间,以秒为单位。例如:Ca