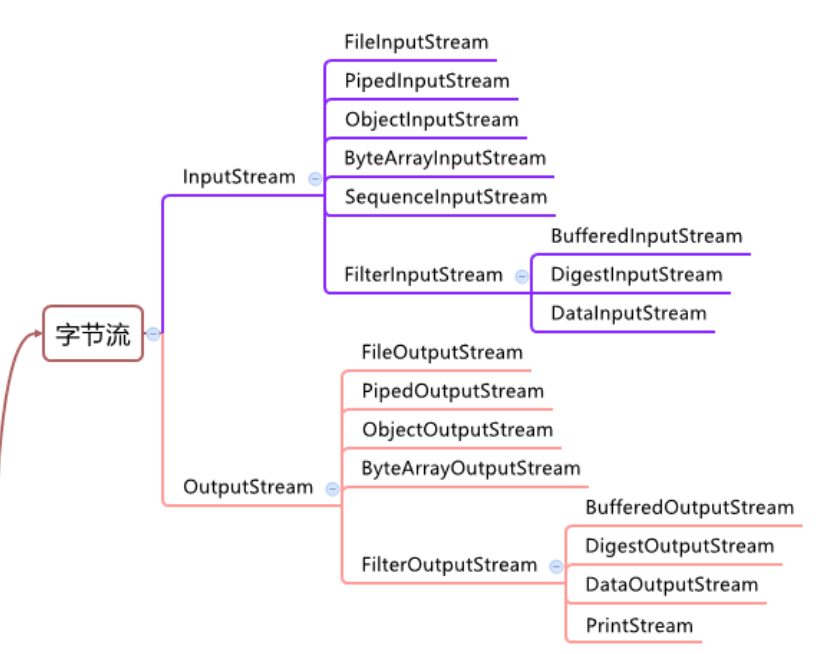
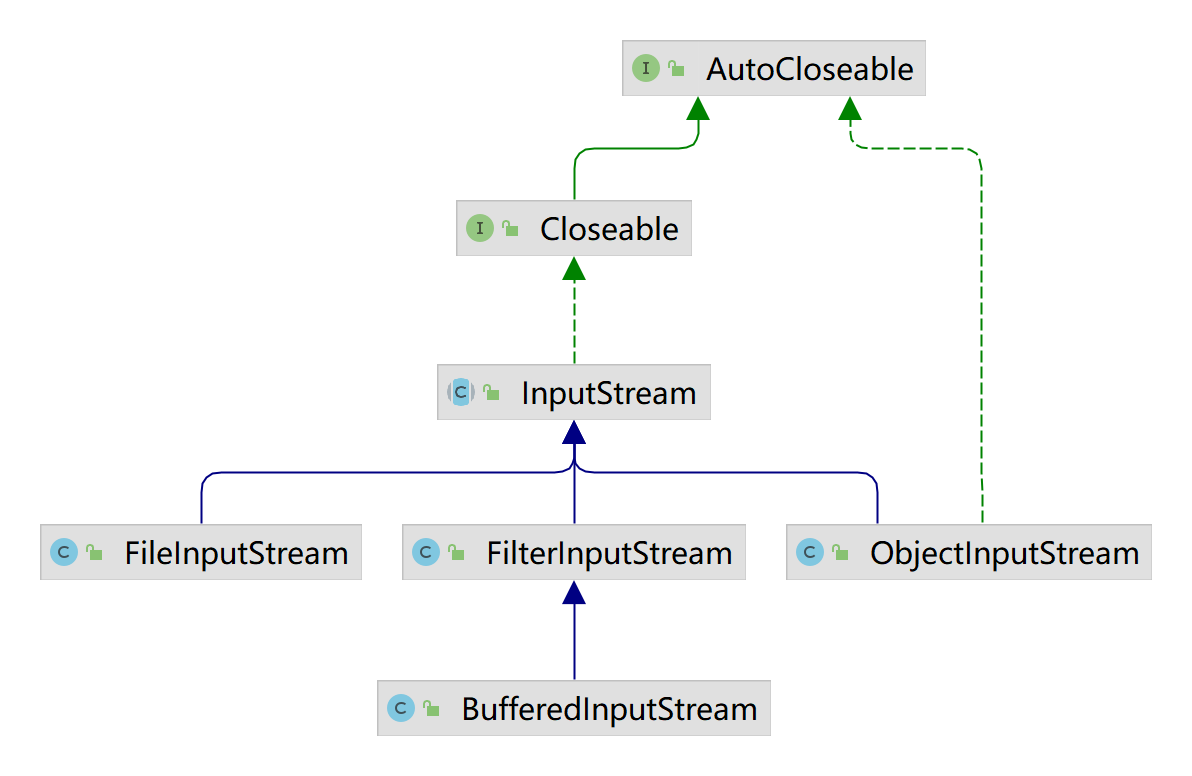
InputStream抽象类是所有类字节输入流的超类
InputStream常用的子类:
常用方法:
输入流的唯一目的是提供通往数据的通道,程序可以通过这个通道读取文件中的数据。
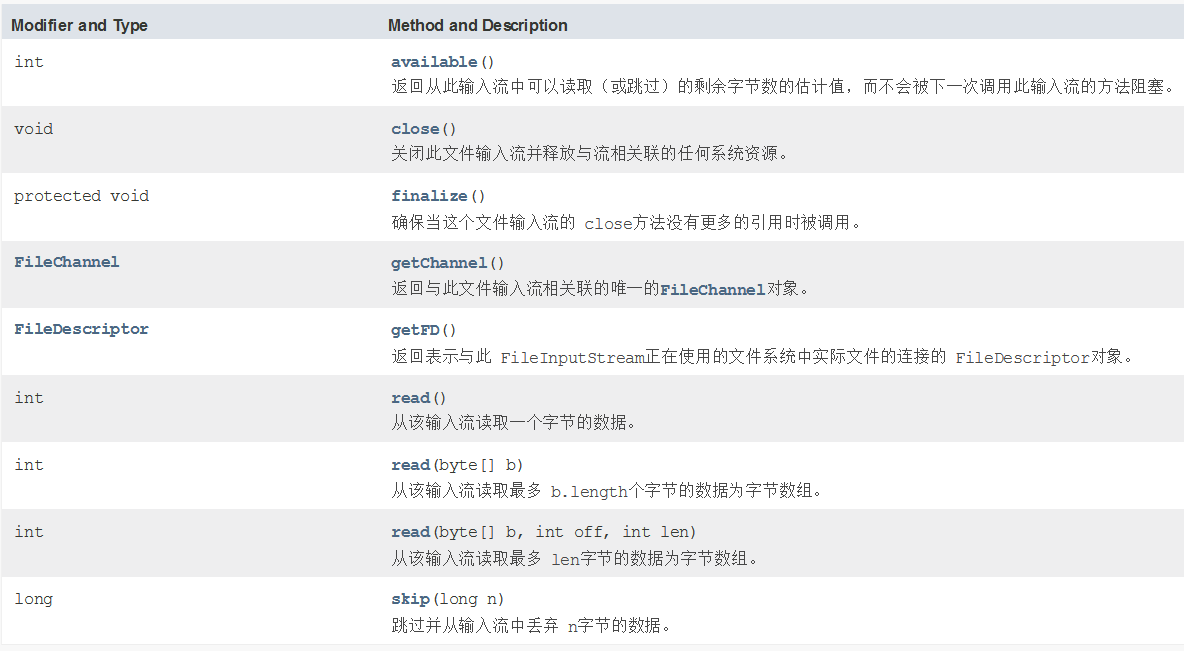
read方法提供了一个从输入流读取数据的基本方法,read方法的格式如下:
| 返回值 | 方法 | 说明 |
|---|---|---|
| int | read( ) | 从输入流中读取数据的下一个字节 |
| int | read(byte[ ] b) | 从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。以整数形式返回读取的字节数。 |
| int | read(byte[ ] b, int off, int len) | 将输入流中最多 len 个数据字节读入 byte 数组。尝试读取 len 个字节,但读取的字节也可能小于该值。以整数形式返回实际读取的字节数。 |
| void | close( ) | 关闭流 |
注:read方法在从输入流中读取源中的数据时,如果到达源的末尾,便会返回-1。
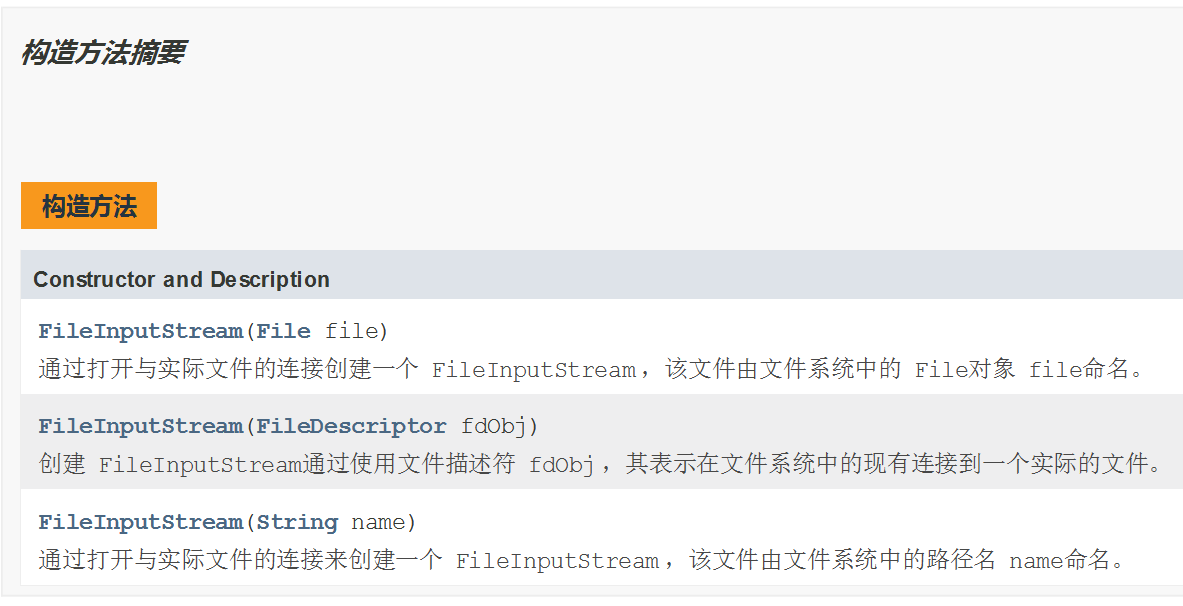
FileInputStream流顺序地读取文件,只要不关闭流,每次调用read方法就顺序的读取源中其余的内容,直至源的末尾或流被关闭。
例子:
package li.io.inputstream_;
import org.junit.jupiter.api.Test;
import java.io.FileInputStream;
import java.io.IOException;
//演示FileInputStream的使用(字节输入流 文件-->程序)
public class FileInputStream_ {
public static void main(String[] args) {
}
/**
* 演示读取文件
* read():单个字节的读取,效率较低
*/
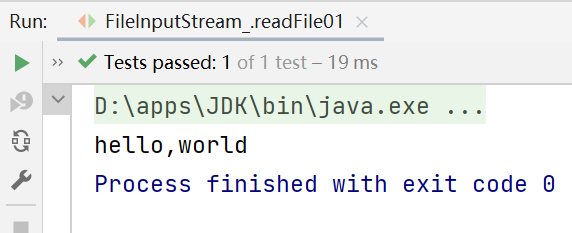
@Test
public void readFile01() {
String filePath = "d:\\hello.txt";
int readData = 0;
FileInputStream fileInputStream = null;
try {
//创建了FileInputStream对象,用于读取文件
fileInputStream = new FileInputStream(filePath);
//read()方法:从该输入流读取一个字节的数据。 如果没有输入可用,此方法将阻止。
//如果返回-1,则表示达到文件的末尾,表示读取完毕
while ((readData = fileInputStream.read()) != -1) {
System.out.print((char) readData);//转成char显示,因此如果文件里面有中文字符(每个中文字符占三个字节),显示的时候就会出现乱码
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//关闭文件流,释放资源
try {
fileInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 使用read(byte[] b)读取文件,提高效率
*/
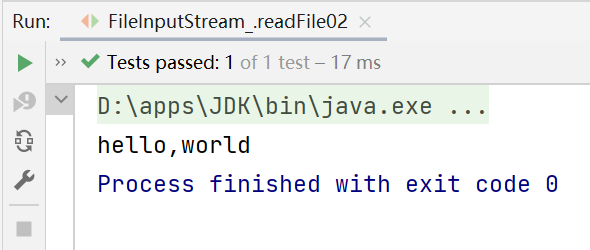
@Test
public void readFile02() {
String filePath = "d:\\hello.txt";
//字节数组
byte[] buf = new byte[8];//一次读取8个字节
int readLen = 0;
FileInputStream fileInputStream = null;
try {
//创建了FileInputStream对象,用于读取文件
fileInputStream = new FileInputStream(filePath);
//read(byte[] b)方法:从该输入流读取最多b.length字节的数据到字节数组。
//如果返回-1,则表示达到文件的末尾,表示读取完毕
//如果读取正常,返回实际读取的字节数
while ((readLen = fileInputStream.read(buf)) != -1) {
System.out.print(new String(buf, 0, readLen));//显示
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//关闭文件流,释放资源
try {
fileInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}


常用方法:

例子:FileOutputStream应用实例1
要求:请使用FileOutputStream在a.txt文件中写入“hello,world”。如果文件不存在,就先创建文件。
(注意:前提是目录已经存在)
package li.io.outputstream_;
import org.junit.jupiter.api.Test;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileOutputStream_ {
public static void main(String[] args) {
}
/**
* 演示使用FileOutputStream将数据写到文件中,如果该文件不存在,则先创建文件
*/
@Test
public void writeFile() {
String filePath = "d:\\a.txt";
//创建FileOutputStream对象
FileOutputStream fileOutputStream = null;
try {
//得到一个FileOutputStream对象
/*
如果是以new FileOutputStream(filePath)的方式创建对象,
则当写入内容时,会覆盖原来的内容
如果是以new FileOutputStream(filePath,true)的方式创建对象,
则当写入内容时,是在旧内容的末尾追加新内容
*/
fileOutputStream = new FileOutputStream(filePath,true);//以追加的形式去添加新内容
//写入一个字节
//fileOutputStream.write('H');
//写入字符串
String str = "Hello,Jack!";
//String的getBytes方法可以将字符串转为字符数组
// fileOutputStream.write(str.getBytes());
/*
write(byte[] b,int off,int len)
将len长度的字节从位于偏移量off的指定字节输入写入此文件输出流
*/
fileOutputStream.write(str.getBytes(), 0, 4);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
追加前: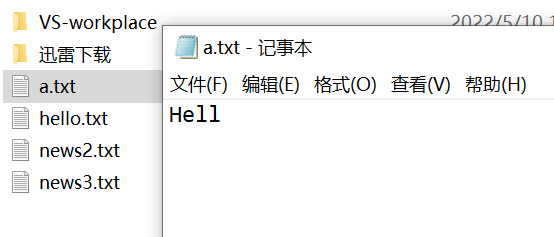
追加后: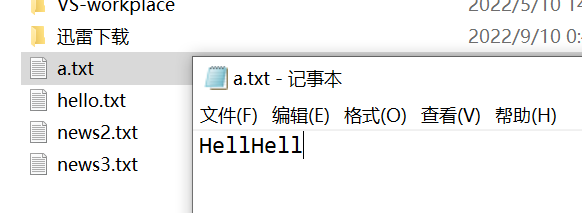
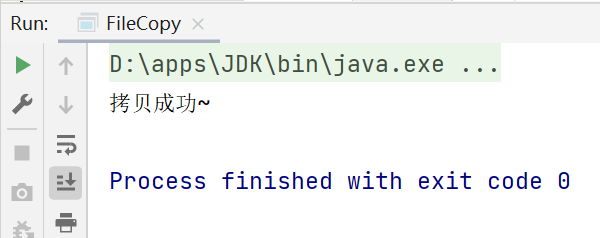
应用实例2:文件拷贝
要求:完成文件拷贝,将d:\Koala.png拷贝到d:\Koala222.png
在完成程序时,为防止读取的文件过大,应该是每读取部分数据,就写入到指定文件,这里使用循环。
package li.io.outputstream_;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileCopy {
public static void main(String[] args) {
//完成文件拷贝,将c:\\Koala.png拷贝到d:\\
/*
思路分析:
1.创建文件的输入流,将文件读入到程序
2.创建文件的输出流,将读取到的文件数据写入指定的文件
*/
String srcFilePath = "d:\\Koala.png";
String destFilePath = "d:\\Koala222.png";
FileInputStream fileInputStream = null;
FileOutputStream fileOutputStream = null;
try {
fileInputStream = new FileInputStream(srcFilePath);
fileOutputStream = new FileOutputStream(destFilePath, true);
//定义一个字节数组,提高效率
byte[] buf = new byte[1024];//1K
int readLen = 0;
while ((readLen = fileInputStream.read(buf)) != -1) {
//读取到后,就通过 fileOutputStream写入到文件
//即,是一边读一边写)
fileOutputStream.write(buf, 0, readLen);//一定要使用这个方法
}
System.out.println("拷贝成功~");
} catch (IOException e) {
e.printStackTrace();
} finally {
//关闭输入流和输出流,释放资源
try {
if (fileInputStream != null) {
fileInputStream.close();
}
if (fileOutputStream != null) {
fileOutputStream.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
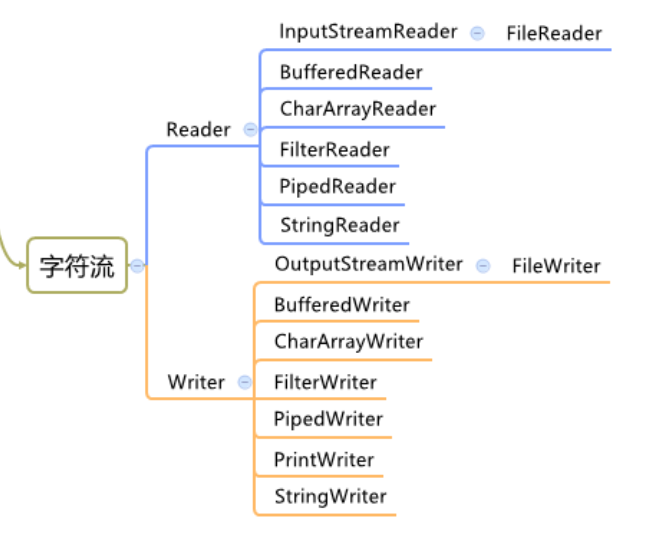
FileReader和FileWriter是字符流,即按照字符来操作IO
FileReader相关方法:
构造方法:
public FileReader(String fileName) throws FileNotFoundException
//在给定从中读取数据的文件名的情况下创建一个新 FileReader。
//fileName - 要从中读取数据的文件的名称
public FileReader(File file) throws FileNotFoundException
//在给定从中读取数据的 File 的情况下创建一个新 FileReader。
//file - 要从中读取数据的 File
常用方法:
public int read() throws IOException
//每次读取单个字符,返回该字符,如果到文件末尾返回-1
public int read(char[] ) throws IOException
//批量读取多个字符到数组,返回读取到的字符数,如果到文件末尾就返回-1
public void close() throws IOException
//关闭该流并释放与之关联的所有资源。
相关API:
new String(char[]):将char[]转换成String
new String(char[],off,len):将char[]的指定部分转换成String
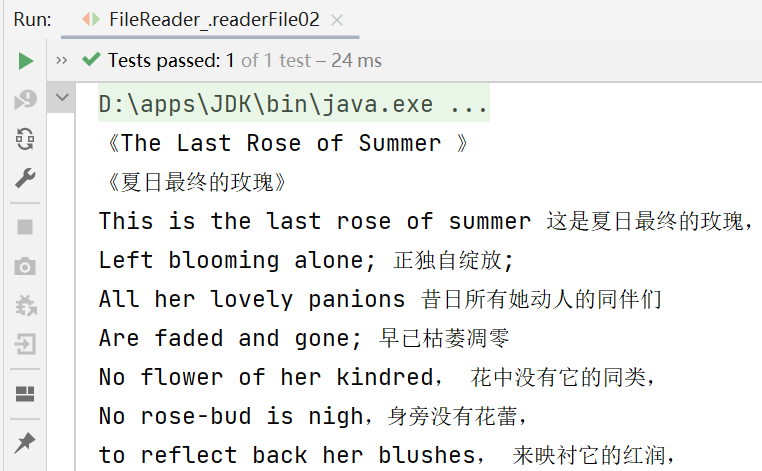
例子:使用FileReader从story.txt读取内容,并显示
先在d盘根目录下下新建一个story.txt文件,放入内容
package li.io.reader_;
import org.junit.jupiter.api.Test;
import java.io.FileReader;
import java.io.IOException;
public class FileReader_ {
public static void main(String[] args) {
}
/**
* 1.使用public int read() throws IOException
* 每次读取单个字符,返回该字符,如果到文件末尾返回-1
*/
@Test
public void readerFile01() {
String filePath = "d:\\story.txt";
FileReader fileReader = null;
int data = 0;
//1.创建一个FileReader对象
try {
fileReader = new FileReader(filePath);
//循环读取 使用reader():每次读取单个字符,返回该字符,如果到文件末尾返回-1
while ((data = fileReader.read()) != -1) {
System.out.print((char) data);//将int类型强转为char类型
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fileReader != null) {
fileReader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 2.public int read(char[] ) throws IOException
* 批量读取多个字符到数组,返回读取到的字符数,如果到文件末尾就返回-1
*/
@Test
public void readerFile02() {
String filePath = "d:\\story.txt";
FileReader fileReader = null;
int readLen = 0;
char[] buf = new char[8];//每读取8个字符输出一次
//1.创建一个FileReader对象
try {
fileReader = new FileReader(filePath);
//循环读取 使用reader(char[]):批量读取多个字符到数组,返回读取到的字符数,
// 如果到文件末尾就返回-1
while ((readLen = fileReader.read(buf)) != -1) {
System.out.print(new String(buf, 0, readLen));//将char[]的指定部分转换成String
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fileReader != null) {
fileReader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}

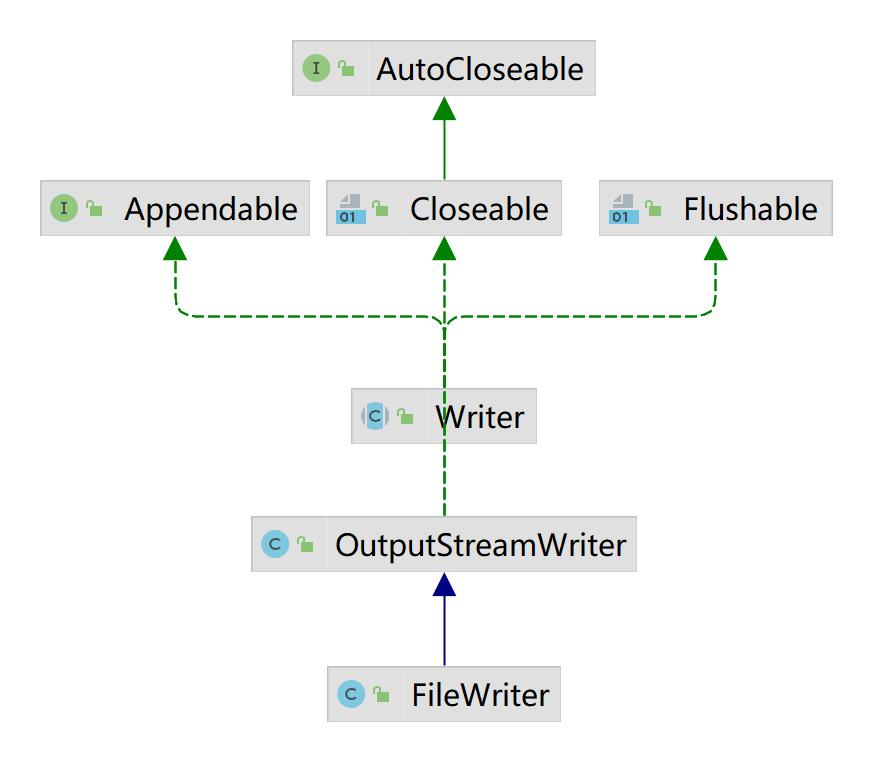
FileWriter常用方法:
构造方法:
public FileWriter(String fileName) throws IOException
//根据给定的文件名构造一个 FileWriter 对象。
//fileName - 一个字符串,表示与系统有关的文件名。
public FileWriter(String fileName,boolean append) throws IOException
//根据给定的文件名以及指示是否附加写入数据的 boolean 值来构造 FileWriter 对象。
//fileName - 一个字符串,表示与系统有关的文件名。
//append - 一个 boolean 值,如果为 true,则将数据写入文件末尾处,而不是写入文件开始处。
//(即覆盖和追加)
public FileWriter(File file) throws IOException
//根据给定的 File 对象构造一个 FileWriter 对象。
//file - 要写入数据的 File 对象。
常用方法:
public void write(int c):
//写入单个字符
public void write(char[] cbuf):
//写入字符数组
public abstract void write(char[] cbuf, int off, int len):
//写入字符数组的指定部分
public void write(String str):
//写入字符串
public void write(String str,int off, int len):
//写入字符串的指定部分
public void flush() throws IOException
//刷新该流的缓冲。
public void close() throws IOException
//关闭此流,但要先刷新它
相关API:String类:toCharArray:将String转换成char[]
注意:FileWriter使用后,必须要关闭(close)或刷新(flush),否则写入不到指定的文件!
例子:
package li.io.writer_;
import java.io.FileWriter;
import java.io.IOException;
public class FileWriter_ {
public static void main(String[] args) {
String filePath = "d:\\note.txt";
FileWriter fileWriter = null ;
char[] chars = {'a','b','c'};
//创建FileWriter对象
try {
//覆盖模式写入,覆盖是建立在执行close()之后
fileWriter = new FileWriter(filePath);
//public void write(int c):写入单个字符
fileWriter.write('H');
//public void write(char[] cbuf):写入字符数组
fileWriter.write(chars);
//public abstract void write(char[] cbuf, int off, int len):写入字符数组的指定部分
fileWriter.write("小猫想睡觉".toCharArray(),0,2);
//public void write(String str):写入字符串
fileWriter.write("你好北京~");
//public void write(String str,int off, int len):写入字符串的指定部分
fileWriter.write("上海天津",0,2);
} catch (IOException e) {
e.printStackTrace();
}finally {
//对应FileWriter,一定要关闭流,或者flush才能真正地白数据写入到文件中
try {
fileWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}

在数据量大的情况下,可以使用循环操作
思考:为什么关闭流(close)或者flush才能真正地把数据写入文件中?
IO缓冲流的flush()和close()方法说明及写入文件
fileWriter.close 和fileWriter.flush的区别:
实际上,当我们写好new FileWriter ,进行下一步的操作,将数据写入文本的时候,这时的数据并没有写入文本,而是存在了计算机中的流中。这也是JAVA能够在Windows 系统中调用文本流的作用。而如果在这里我们使用fileWriter.flush,是可以将存储在计算机流中的数据放入fileWriter对象的,但是如果我们之后再想加入数据的时候,也就是说我们将写入数据这句话放在fileWriter.flush之后的话,之后输入的数据就不会放入到note.txt中去。
再说一说fileWriter.close, 我们可以去查询close的定义,很明确的写了 先刷新一次,然后关闭数据流。也就是说close是包含了两步,flush 和close 这两步。flush 刷新后,流可以继续使用,close刷新后,会将流关闭。
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
我正在尝试解析一个文本文件,该文件每行包含可变数量的单词和数字,如下所示:foo4.500bar3.001.33foobar如何读取由空格而不是换行符分隔的文件?有什么方法可以设置File("file.txt").foreach方法以使用空格而不是换行符作为分隔符? 最佳答案 接受的答案将slurp文件,这可能是大文本文件的问题。更好的解决方案是IO.foreach.它是惯用的,将按字符流式传输文件:File.foreach(filename,""){|string|putsstring}包含“thisisanexample”结果的
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
1.在Python3中,下列关于数学运算结果正确的是:(B)a=10b=3print(a//b)print(a%b)print(a/b)A.3,3,3.3333...B.3,1,3.3333...C.3.3333...,3.3333...,3D.3.3333...,1,3.3333...解析: 在Python中,//表示地板除(向下取整),%表示取余,/表示除(Python2向下取整返回3)2.如下程序Python2会打印多少个数:(D)k=1000whilek>1: print(k)k=k/2A.1000 B.10C.11D.9解析: 按照题意每次循环K/2,直到K值小于等
print"Enteryourpassword:"pass=STDIN.noecho(&:gets)puts"Yourpasswordis#{pass}!"输出:Enteryourpassword:input.rb:2:in`':undefinedmethod`noecho'for#>(NoMethodError) 最佳答案 一开始require'io/console'后来的Ruby1.9.3 关于ruby-为什么不能使用类IO的实例方法noecho?,我们在StackOverflow上
我有一个任务列表(名称、starts_at),我试图在每日View中显示它们(就像iCal)。deftodays_tasks(day)Task.find(:all,:conditions=>["starts_atbetween?and?",day.beginning,day.ending]end我不知道如何将Time.now(例如“2009-04-1210:00:00”)动态转换为一天的开始(和结束),以便进行比较。 最佳答案 deftodays_tasks(now=Time.now)Task.find(:all,:conditio
什么是0day漏洞?0day漏洞,是指已经被发现,但是还未被公开,同时官方还没有相关补丁的漏洞;通俗的讲,就是除了黑客,没人知道他的存在,其往往具有很大的突发性、破坏性、致命性。0day漏洞之所以称为0day,正是因为其补丁永远晚于攻击。所以攻击者利用0day漏洞攻击的成功率极高,往往可以达到目的并全身而退,而防守方却一无所知,只有在漏洞公布之后,才后知后觉,却为时已晚。“后知后觉、反应迟钝”就是当前安全防护面对0day攻击的真实写照!为了方便大家理解,中科三方为大家梳理当前安全防护模式下,一个漏洞从发现到解决的三个时间节点:T0:此时漏洞即0day漏洞,是已经被发现,还未被公开,官方还没有相
当我将IO::popen与不存在的命令一起使用时,我在屏幕上打印了一条错误消息:irb>IO.popen"fakefake"#=>#irb>(irb):1:commandnotfound:fakefake有什么方法可以捕获此错误,以便我可以在脚本中进行检查? 最佳答案 是:升级到ruby1.9。如果您在1.9中运行它,则会引发Errno::ENOENT,您将能够拯救它。(编辑)这是在1.8中的一种hackish方式:error=IO.pipe$stderr.reopenerror[1]pipe=IO.popen'qwe'#
ruby1.9.3dev(2011-09-23修订版33323)[i686-linux]轨道3.0.20最近为什么在与DateTimeonRails相关的RSpecs项目上工作我发现在给定日期以下语句发出的值date.end_of_day.to_datetime和date.to_datetime.end_of_day虽然它们表示相同的日期时间,但比较时返回false。为了确认这一点,我打开了Rails控制台并尝试了以下操作1.9.3dev:053>monday=Time.now.monday=>2013-02-2500:00:00+05301.9.3dev:054>monday.cla