序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串
反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器可以把字典转成模型
反序列化时同时会完成数据校验功能
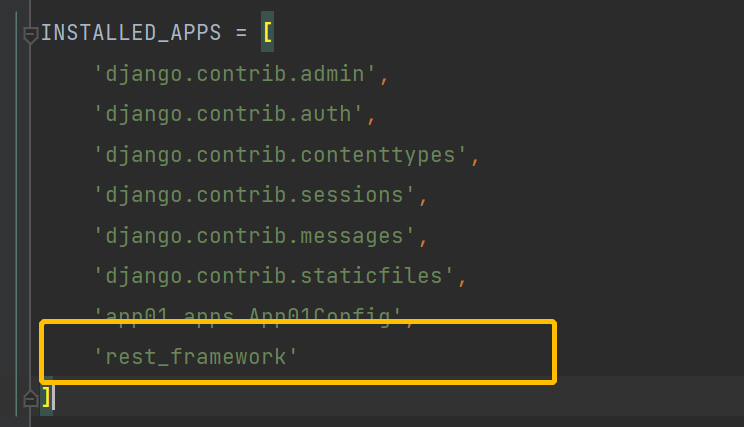
1.在setting.py中的app配置里注册一下drf
2.在django的模型层创建一个表
from django.db import models
# Create your models here.
class Book(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
author = models.CharField(max_length=32)
3.在表中添加一些数据
4.编写序列化组件(类似forms组件),可以在应用下单独创一个文件夹,里面放序列化组件.py
from rest_framework import serializers# 导入drf中的序列化类
# 创建一个类继承Serializer序列化类
class BookSerializer(serializers.Serializer):
# 定义需要序列化的字段,想要哪个字段就添加该字段,不需要就注释掉
nid = serializers.CharField()
name = serializers.CharField()
price = serializers.CharField()
5.在url.py中开设路径获取序列化之后的数据
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'^book/(?P<pk>\d+)/$',views.BooksView.as_view()) #CBV格式的url
]
6.在视图函数中序列化需要的模型对象,返回给前端页面字典格式的数据
from rest_framework.views import APIView # 导入drf模块的apiview,使得cbv格式的视图函数继承它
from app01 import models
from .ser import BookSerializer # 导入自己写好的序列化组件
from rest_framework.response import Response # 导入drf模块的响应类
class BooksView(APIView):
# get请求的视图函数
def get(self,request,pk):
# 得到需要查询的模型对象
book = models.Book.objects.filter(pk=pk).first()
# 将模型对象交给自己写好的序列化器,生成一个序列化对象
book_ser = BookSerializer(book)
# book_ser.data 序列化对象.data就是序列化后的字典
return Response(book_ser.data) # 利用drf中的Response类返回给前端,Response会帮您把这个字典序列化成json格式!
# 使用JsonResponse返回上述字典,在浏览器就没有Response漂亮的格式而已,也是返回json数据格式
return JsonResponse(book_ser.data,json_dumps_params={'ensure_ascii':False})
# views.py
class BooksView(APIView):
def get(self,request):
response_msg = {'status': 100, 'msg': '成功'}
books=Book.objects.all()
book_ser=BookSerializer(books,many=True) #序列化多条,如果序列化一条,不需要写
response_msg['data']=book_ser.data
return Response(response_msg)
#urls.py
path('books/', views.BooksView.as_view()),
1.在cbv格式的视图函数中添加put函数
def put(self,request,pk):
back_dic = {'code':1000,'msg':'成功'}
# 1.得到需要查询的模型对象
book = models.Book.objects.filter(pk=pk).first()
# 2. 将模型对象交给自己写好的序列化器,生成一个序列化对象,除了传模型对象,还需要传入用户修改的数据
book_ser = BookSerializer(instance=book,data=request.data)
# 3.进行数据校验,类似forms组件的校验
is_right = book_ser.is_valid()
if is_right:
# 4.校验通过操作序列化对象保存修改数据
book_ser.save() # 注意这里需要在序列化组件中重写update()方法,否则报错
# 5.将正确的数据在返回给前端
back_dic['data'] = book_ser.data
else:
back_dic['code'] = 1001
back_dic['msg'] = '数据格式不正确'
back_dic['data'] = book_ser.errors
return Response(back_dic)
2.在自定义的序列化组件类中添加update()方法
def update(self, instance, validated_data):
# instance参数就是book这个对象,validated_data就是用户修改提交上来的字典格式数据
# 1.修改这个对象的字段值
instance.name = validated_data.get('name')
instance.price = validated_data.get('price')
# 2.操作数据库保存修改数据
instance.save() # 相当于book.save() 是django orm提供的方法
# 最后需要把这个book对象在返回出去
return instance
# views.py
class BooksView(APIView):
# 新增
def post(self,request):
response_msg = {'status': 100, 'msg': '成功'}
#修改才有instance,新增没有instance,只有data
book_ser = BookSerializer(data=request.data)
# book_ser = BookSerializer(request.data) # 这个按位置传request.data会给instance,就报错了
# 校验字段
if book_ser.is_valid():
book_ser.save()
response_msg['data']=book_ser.data
else:
response_msg['status']=102
response_msg['msg']='数据校验失败'
response_msg['data']=book_ser.errors
return Response(response_msg)
#ser.py 序列化类重写create方法
def create(self, validated_data):
instance=Book.objects.create(**validated_data)
return instance
# urls.py
path('books/', views.BooksView.as_view()),
# views.py
class BookView(APIView):
def delete(self,request,pk):
ret=Book.objects.filter(pk=pk).delete()
return Response({'status':100,'msg':'删除成功'})
# urls.py
re_path('books/(?P<pk>\d+)', views.BookView.as_view()),
常用字段类型
# BooleanField BooleanField()
# NullBooleanField NullBooleanField()
# CharField CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True)
# EmailField EmailField(max_length=None, min_length=None, allow_blank=False)
# RegexField RegexField(regex, max_length=None, min_length=None, allow_blank=False)
# SlugField SlugField(maxlength=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9-]+
# URLField URLField(max_length=200, min_length=None, allow_blank=False)
# UUIDField UUIDField(format=’hex_verbose’) format: 1) 'hex_verbose' 如"5ce0e9a5-5ffa-654b-cee0-1238041fb31a" 2) 'hex' 如 "5ce0e9a55ffa654bcee01238041fb31a" 3)'int' - 如: "123456789012312313134124512351145145114" 4)'urn' 如: "urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a"
# IPAddressField IPAddressField(protocol=’both’, unpack_ipv4=False, **options)
# IntegerField IntegerField(max_value=None, min_value=None)
# FloatField FloatField(max_value=None, min_value=None)
# DecimalField DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置
# DateTimeField DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None)
# DateField DateField(format=api_settings.DATE_FORMAT, input_formats=None)
# TimeField TimeField(format=api_settings.TIME_FORMAT, input_formats=None)
# DurationField DurationField()
# ChoiceField ChoiceField(choices) choices与Django的用法相同
# MultipleChoiceField MultipleChoiceField(choices)
# FileField FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL)
# ImageField ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL)
需要记住的字段类型
CharField
BooleanField
IntegerField
DecimalField
ListField
DictField
常用的字段参数
1 给CharField字段类使用的参数
max_length 最长长度
min_length 最小长度
allow_blank 是否允许为空
trim_whitespace 是否截断空白字段
2 给IntegerField字段类使用的参数
max_value 最小值
min_value 最大值
3 通用参数,放在哪个字段类上都可以
required 表明该字段在反序列化时必须输入,默认True
default 反序列化时使用的默认值
allow_null 表明该字段是否允许传入None,默认False
validators 该字段使用的验证器
error_messages 包含错误编码与错误信息的字典
label 用于HTML展示API页面时,显示的字段名称
help_text 用于Html展示API页面时,显示的字段帮助提示信息
4 重点
read_only 表明该字段仅用于序列化输出,默认False,如果设置成True,postman中可以看到该字段,修改时,不需要传该字段
write_only 表明该字段仅用于反序列化输入,默认False,如果设置成True,postman中看不到该字段,修改时,该字段需要传
局部钩子:
# 序列化组件中的钩子函数
# 局部钩子函数validate_字段名的形式,需要传入一个data参数,data就是price
def validate_price(self, data):
print(type(data)) #格式为<class 'str'>
print(data) # 34.00
# 进行校验,当价格大于30报错
if float(data) < 30:
return data
else:
# 校验不通过,抛出异常 rest_framework异常在 from rest_framework.exceptions import ValidationError里
raise ValidationError('价格太高')
全局钩子:
def validate(self,validated_data): # validated_data校验之后的数据
name = validated_data.get('name')
price = validated_data.get('price')
if name == 'zhang' and price == '25':
raise ValidationError('不正确')
return validated_data
第三种validators校验:
# 定义一个函数
def check_name(data):
if data.startswith('sb'):
raise ValidationError('名字不能是sb开头')
else:
return data
# 在指定字段内添加validators
name = serializers.CharField(validators=[check_name]) #validators=[]列表中写函数的内存地址
总结:主要用局部钩子和全局钩子!!
# 模型化序列器,继承ModelSerializer,并且不需要自己书写updata和create方法了
class BookSerializer2(serializers.ModelSerializer):
# 1.定义一个Meta类
class Meta:
# 2.model后面等于需要序列化的表
model = models.Book
# 3.表示序列化该表中所有的字段
# fields = '__all__'
# 4.序列化表中的指定字段
# fields = ('name','price') # 注意fields里可以放model.py里book表对应的字段,也可以放book表类里定义的方法(详解下图)
# 5.序列化除以下字段
exclude = ('name',) # ()里是一个元组,注意需要加个逗号
# 6.read_only和write_only这些原本需要在字段括号内书写的参数都放在extra_kwargs里书写
extra_kwargs = {
'price':{'write_only':True},
}
在book表类里加的publish_name方法,fields里放该方法,会返回该方法的返回值!


视图函数部分:
class BooksView2(APIView):
def get(self,request):
books = models.Book.objects.all()
book_ser = BookSerializer2(books,many=True) # 这里改成了BookSerializer2模型化序列器
return Response(book_ser.data)
class MyResponse(): # 这里复杂一点可以继承rest_framework的Response类
def __init__(self): # 定义一个初始化方法,该方法有默认属性status和msg(任何由该类产生的对象都有这两个属性)
self.status=100
self.msg = '成功'
@property # 将这个方法伪装成属性
def get_dict(self):
return self.__dict__ # 返回一个字典
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
假设我必须(小型到中型)阵列:tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]如何确定tokens是否以相同的顺序包含template的所有条目?(请注意,在上面的示例中,应忽略第一个“ccc”,从而由于最后一个“ccc”而导致匹配。) 最佳答案 这适用于您的示例数据。tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]po
首先,我使用的是rails3.1.3和来自master的carrierwavegithub仓库的分支。我使用after_init钩子(Hook)来确定基于属性的字段页面模型实例并为这些字段定义属性访问器将值存储在序列化哈希中(希望它清楚我是什么谈论)。这是我正在做的事情的精简版:classPage省略mount_uploader命令让我可以访问我想要的属性。但是当我安装uploader时出现错误消息说“nil类的未定义新方法”我在源代码中读到有方法read_uploader和扩展模块中的write_uploader。我如何必须覆盖这些来制作mount_uploader命令使用我的“虚拟
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
我有一个存储JSON数据的列。当它处于编辑状态时,我不知道如何显示它。serialize:value,JSON=f.fields_for:valuedo|ff|.form-group=ff.label:short=ff.text_field:short,class:'form-control'.form-group=ff.label:long=ff.text_field:long,class:'form-control' 最佳答案 代替=f.fields_for:valuedo|ff|请使用以下代码:=f.fields_for:va
在RubyonRails中,如果数组为空,则具有序列化数组字段的模型将不会在.save()上更新,而它之前有数据。我正在使用:ruby2.2.1rails4.2.1sqlite31.3.10我创建了一个字段设置为文本的新模型:railsgmodel用户名:stringexample:text在我添加的User.rb文件中:serialize:example,Array我实例化了User类的一个新实例:test=User.new然后我保存用户以确保它正确保存:test.save()(0.1ms)begintransactionSQL(0.4ms)INSERTINTO"users"("cr
是否可以在使用YAML.load_file时强制Ruby调用初始化方法?我想调用该方法以便为我不序列化的实例变量提供值。我知道我可以将代码分解成一个单独的方法并在调用YAML.load_file之后调用该方法,但我想知道是否有更优雅的方法来处理这个问题。 最佳答案 我认为你做不到。由于您要添加的代码确实特定于要反序列化的类,因此您应该考虑在类中添加该功能。例如,让Foo成为您要反序列化的类,您可以添加一个类方法,例如:classFoodefself.from_yaml(yaml)foo=YAML::load(yaml)#editth
我有以下工厂:FactoryGirl.definedofactory:foodosequence(:name){|n|"Foo#{n}"}trait:ydosequence(:name){|n|"Fooy#{n}"}endendend如果我跑create:foocreate:foocreate:foo,:y我得到Foo1,Foo2,Fooy1。但我想要Foo1,Foo2,Fooy3。我怎样才能做到这一点? 最佳答案 经过smile2day'sanswer的一些提示后和thisanswer,我得出以下解决方案:FactoryGirl.
我有两个Foo对象列表。每个Foo对象都有一个时间戳,Foo.timestamp。两个列表最初都按时间戳降序排列。我想以最终列表也按时间戳降序排序的方式合并Foo对象的两个列表。实现这个并不难,但我想知道是否有任何内置的Ruby方法可以做到这一点,因为我认为内置方法会产生最佳性能。谢谢。 最佳答案 这会起作用,但不会提供很好的性能,因为它不会利用事先已经排序的列表:list=(list1+list2).sort_by(&:timestamp)我不知道有任何内置函数可以满足您的需求。 关于
除了使用\x08删除前导字符外,是否可以同时删除尾随字符?是否有一个转义序列将删除下一个字符而不是前一个字符?我看到delete显然映射到ASCII127,即Hex7F,但以下代码:puts"a\x08b\x7fcd"产生b⌂cd我预计\x7f会删除它后面的'c'字符,但它没有。 最佳答案 您实际上并没有使用\x08删除任何内容,您只是用“b”覆盖了“a”。想象一下您使用电传纸质终端的过去。您实际上会在纸上看到的是打印的“a”,电传打字机会备份一个空格,然后在其上打印“b”。所有非打印的ascii码都是为了控制电传纸终端的移动而发明