前面我们介绍了白盒测试方法,后面我们来介绍一下Junit 4,使用的是eclipse(用IDEA的小伙伴可以撤了)
我们需要三个jar包:
org.junit_4.13.2.v20211018-1956.jar和org.hamcrest.core_1.3.0.v20180420-1519.jar这两个jar包是eclipse自带的
然后我们需要下一个org.hamcrest-library-1.3.jar
点击 new >> New >> Project
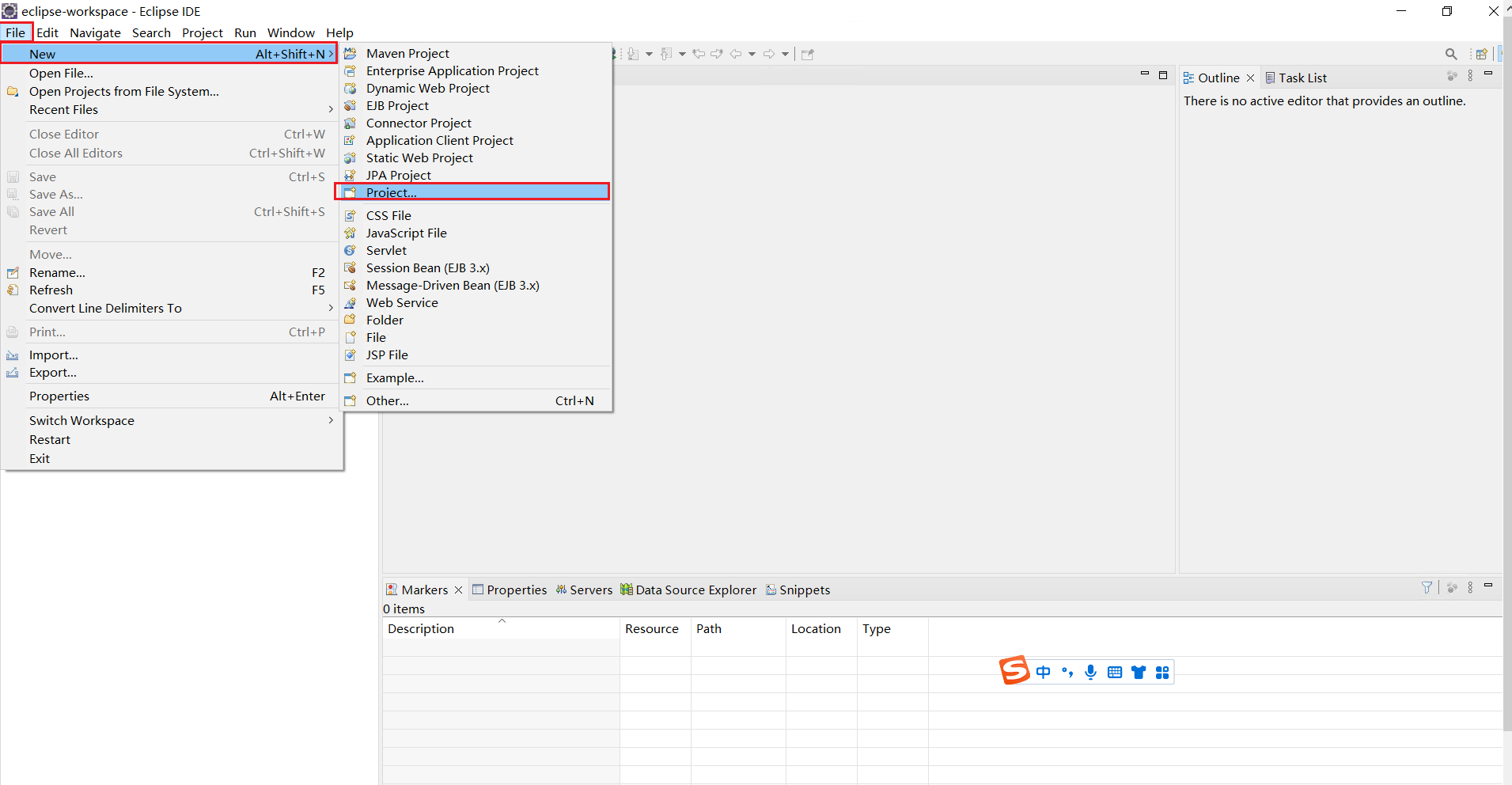
选择Java Project 点击next
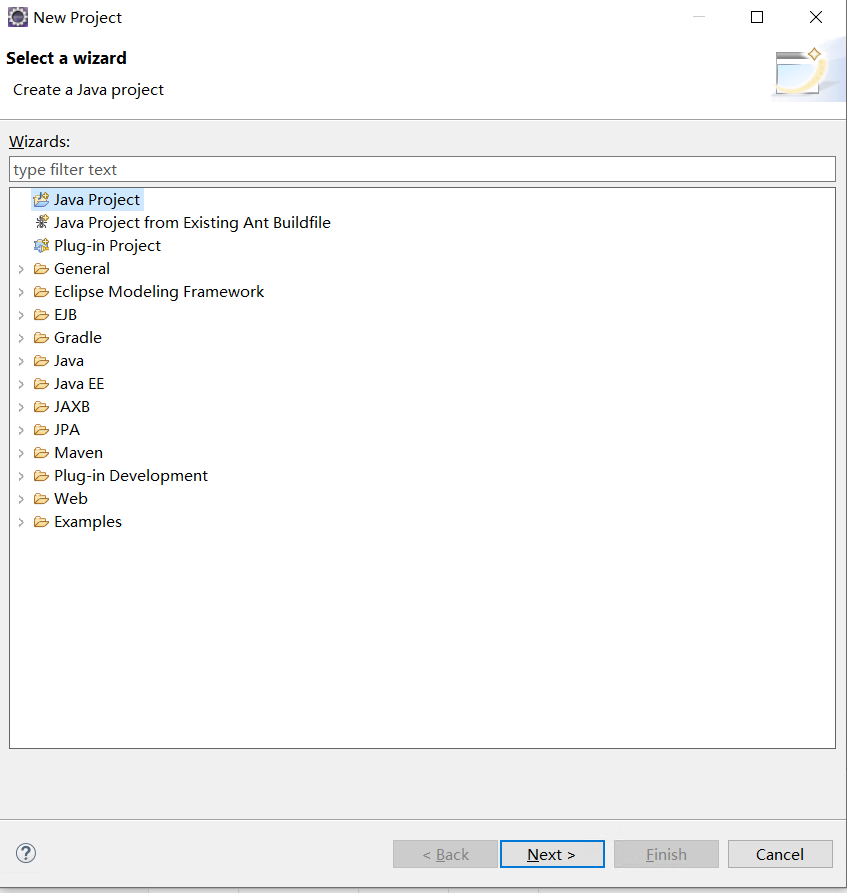
输入项目名,选择jre,点击next
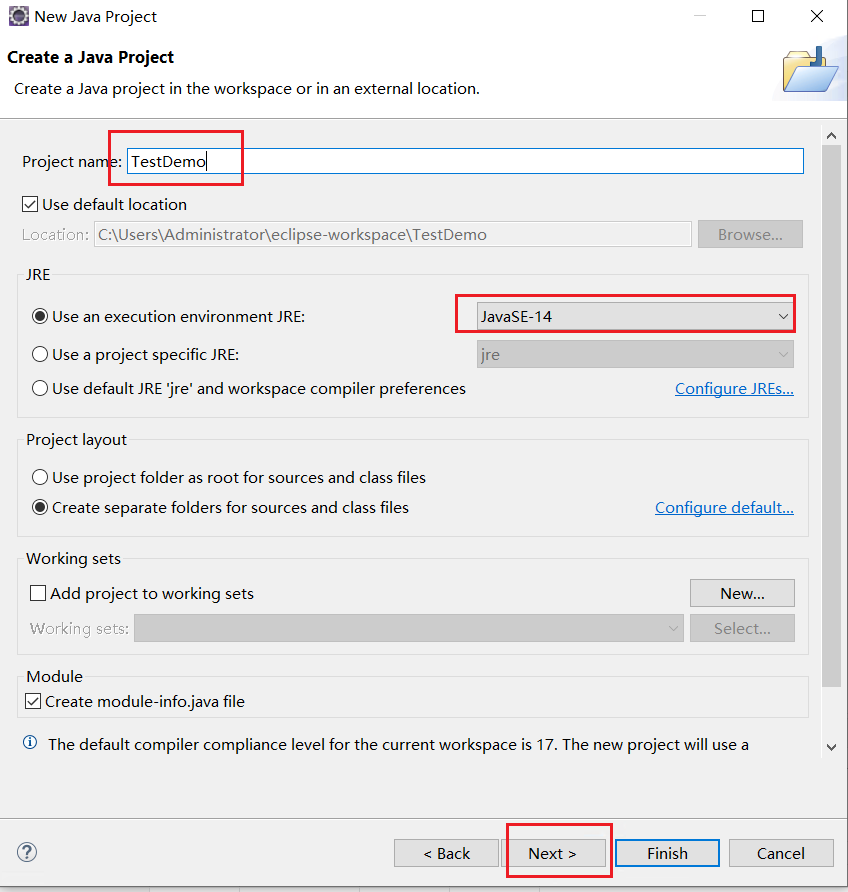
选择 Libraries >> Classpath >> Add Extemal JARs
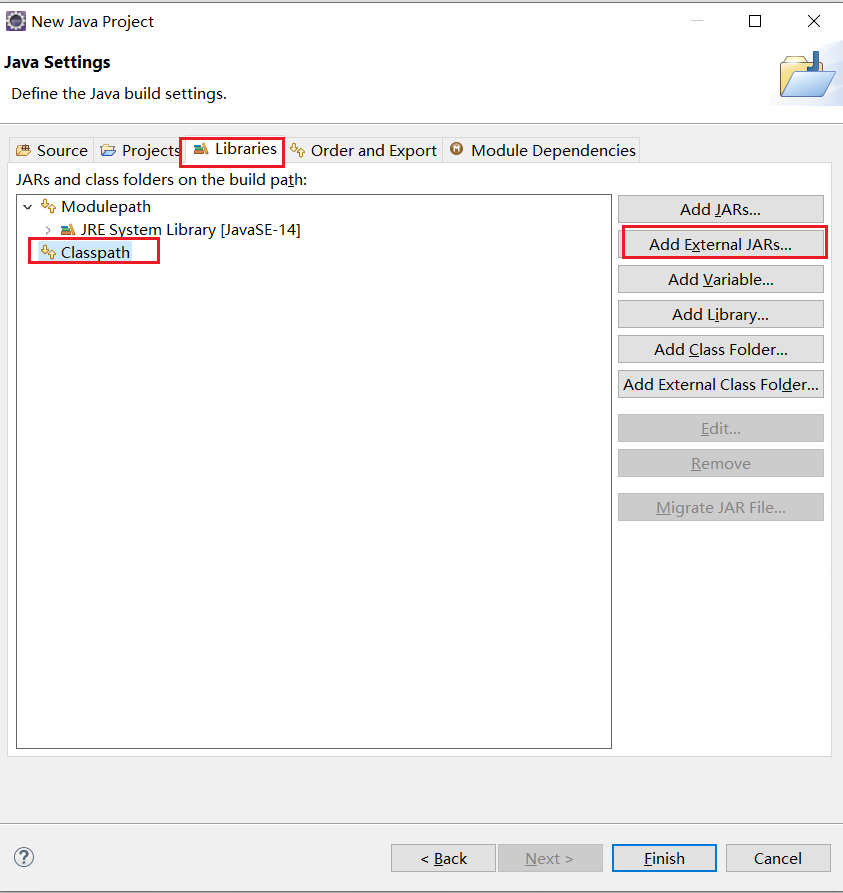
选择之前我们的三个jar包,一般放在eclipsed的plugins目录,org.hamcrest-library-1.3.jar则在自己下载的目录(可以把下载下来的jar包也丢这里),点击Finish
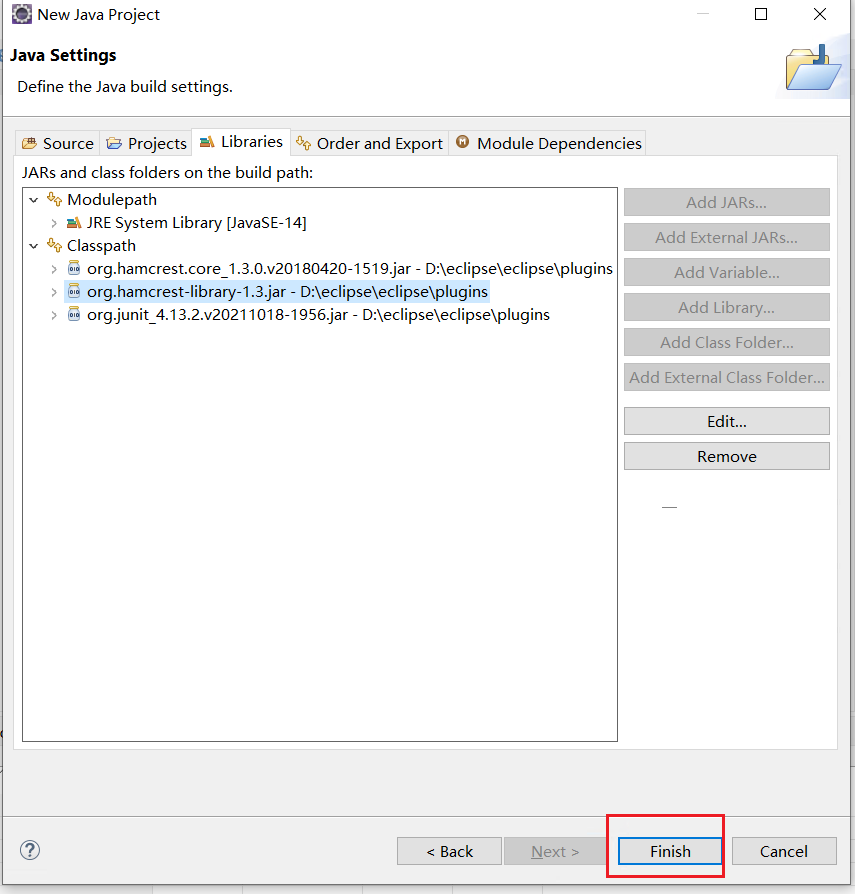
我们新建一个文件夹存放junit代码
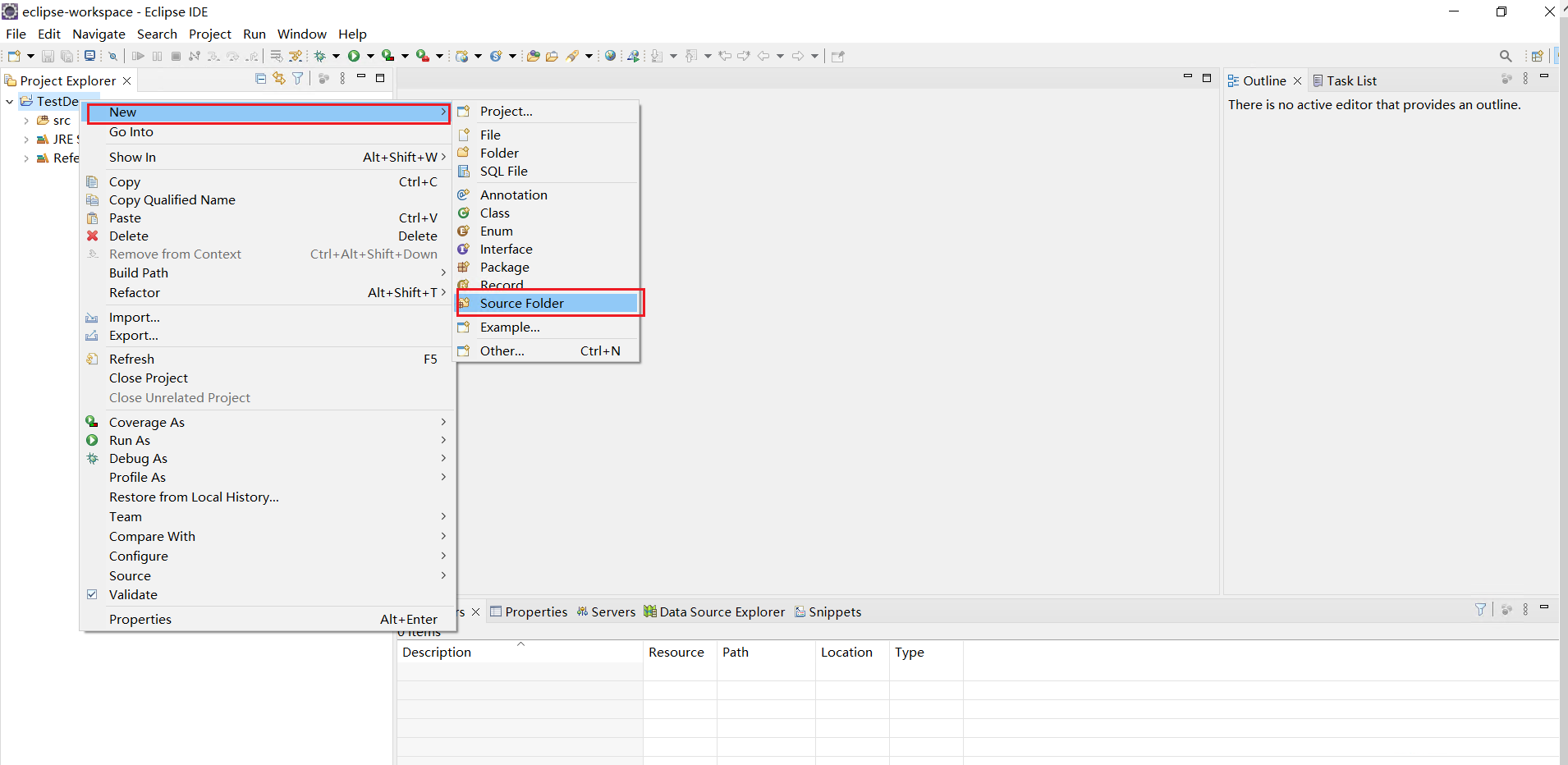
新建一个项目
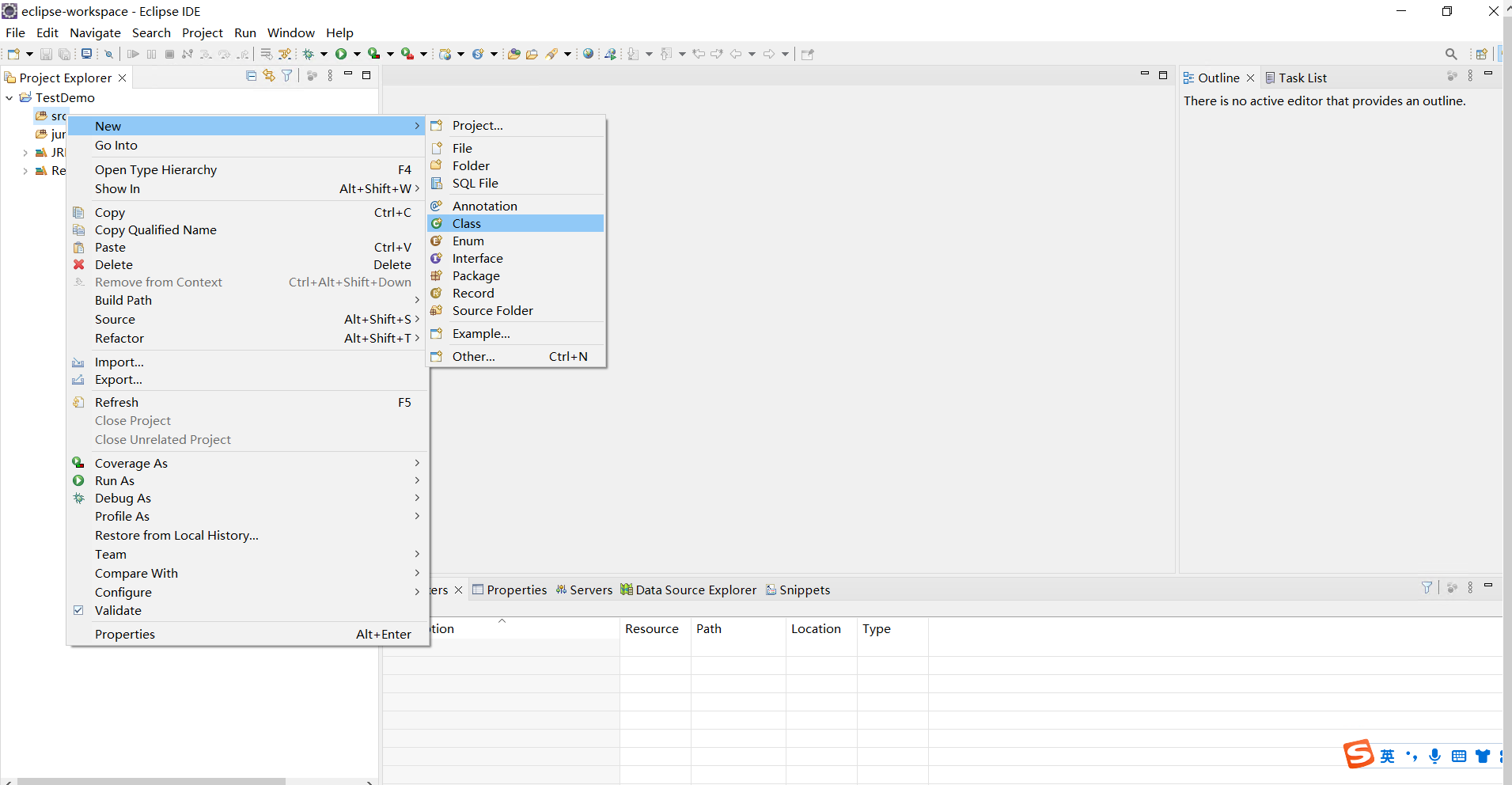
编写Demo.java代码:
public class Demo {
public int add (int a, int b) {
return a + b;
}
public int div (int a, int b) {
return a / b;
}
}
右键项目,new一个,这里没有junit,我们去其他里面找
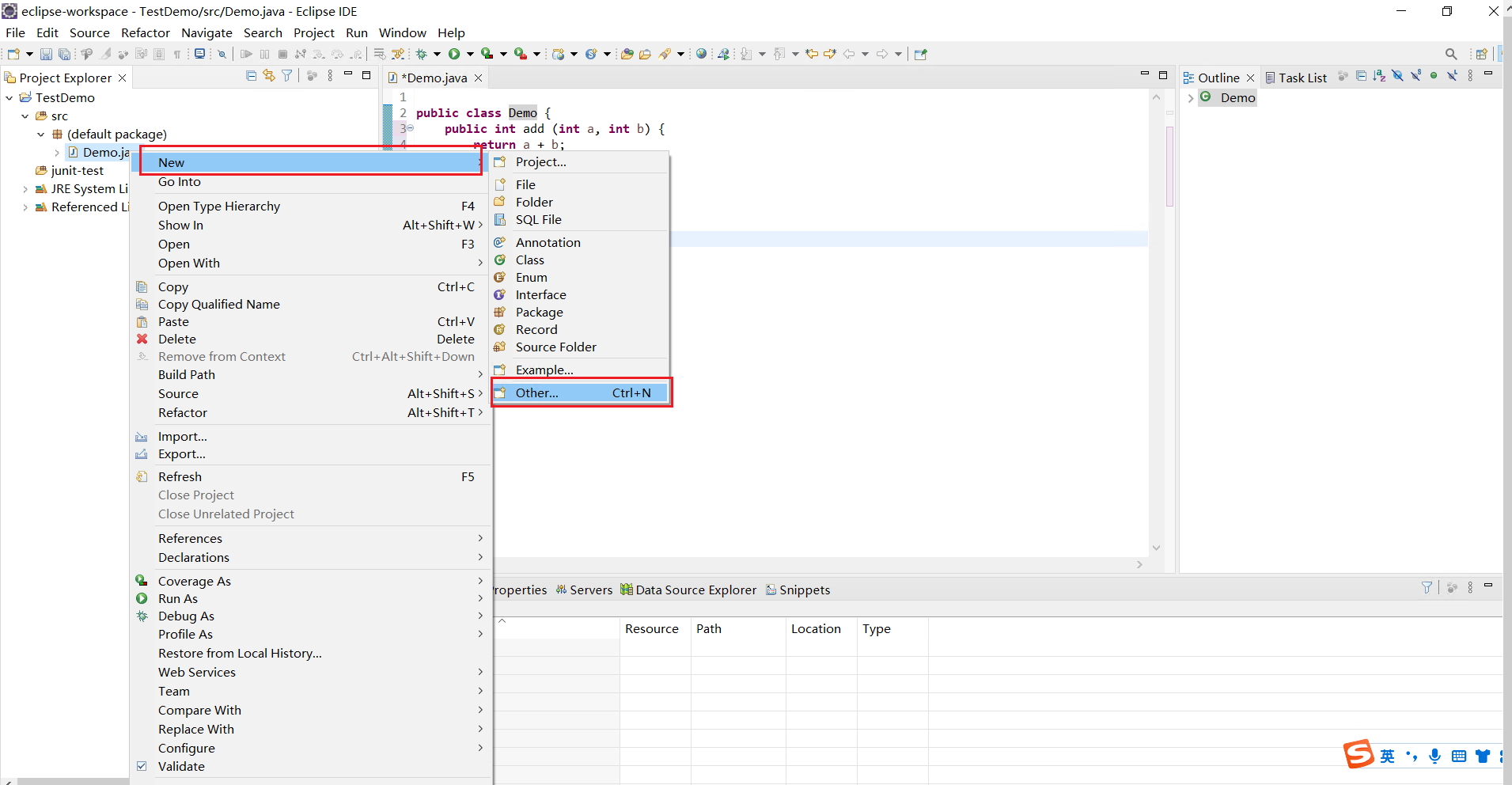
在java下的junit,选择Test Case,点击next
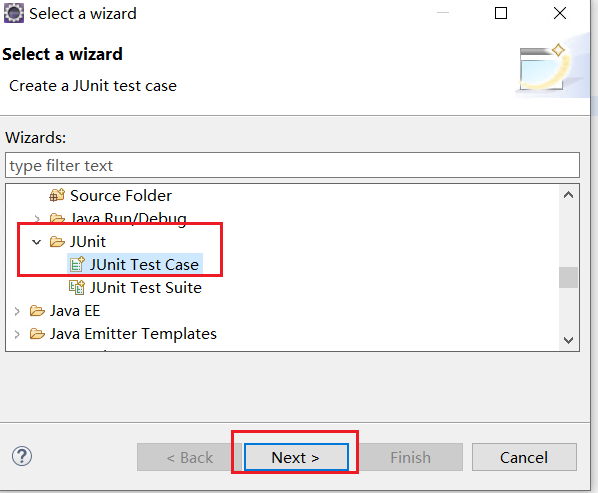
选择junit4,选择目录到我们刚刚建的junit文件夹,选择Finish
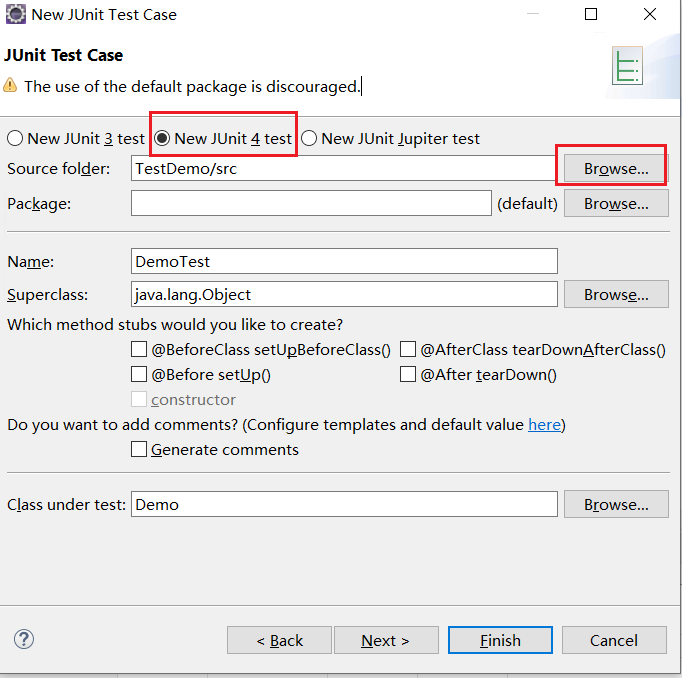
在DemoTest.java中输入代码:
import static org.junit.Assert.*;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class DemoTest {
Demo demo;
@Before
public void setUp() throws Exception {
demo = new Demo();
}
@After
public void tearDown() throws Exception {
demo = null;
}
@Test
public void testAdd() {
// 实例化一个类
Demo demo = new Demo();
// 期望值
int expetected = 2;
// 真实值
int trueValue = demo.add(1, 1);
// 断言方法
assertEquals(expetected, trueValue);
}
@Test
public void testDiv() {
// 实例化一个类
Demo demo = new Demo();
// 期望值
int expetected = 2;
// 真实值
int trueValue = demo.div(2, 1);
// 断言方法
assertEquals(expetected, trueValue);
}
}
运行
public void setUp() throws Exception {
// 初始化所需的资源
}
在每个测试方法之前执行,用以初始化需要初始化的资源
@After
public void tearDown() throws Exception {
// 关闭资源
}
在每个测试方法之后执行,用以关闭需要初始化的资源
@BeforeClass
public static void setup() throws Exception {
// 初始化资源
}
在所有方法执行之前执行,一般被用作执行计算代价很大的任务,如打开数据库连接。被@BeforeClass 注解的方法应该是静态的(即 static类型的)。
@AfterClass
public static void tearDown() throws Exception {
// 关闭资源
}
在所有方法执行之后执行,一般被用作执行类似关闭数据库连接的任务。被@AfterClass 注解的方法应该是静态的(即 static类型的)。
@Test
public void test01() {
// 测试,断言等
}
包含了真正的测试代码,并且会被Junit应用为要测试的方法。
@Test注解有两个可选的参数:
注释掉一个测试方法或者一个类,被注释的方法或类,不会被执行。
注意:JUnite4的执行顺序:@BeforeClass > @Before > @Test1 > @After > @Before > @Test2 > @After ...... > @AfterClass
import static org.junit.Assert.*;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class DemoTest {
@BeforeClass
public static void setup() throws Exception {
// 这里初始化资源(如连接数据库)
}
@AfterClass
public static void tearDown() throws Exception {
// 关闭资源()
}
@Before
public void setUp() throws Exception {
System.out.println("SetUp.....");
// 这里初始化我们所需要的资源
}
@After
public void tearDown() throws Exception {
System.out.println("Gone.....");
// 这里关闭我们的资源
}
@Test
public void test01() {
// 测试1
}
@Ignore
@Test
public void test02() {
// 测试2
}
}
需要一个特殊的Runner, 因此需要向@RunWith注解传递一个参数Suite.calss。
用来表明这个类是一个打包测试类,把需要打包的类作为参数传递给该注解即可。
有了这两个注解之后,就已经完整的表达了所有的含义,因此下面的类无关紧要,随便起个类名,内容为空
import org.junit.runner.RunWith;
import org.junit.runners.Suite;
import org.junit.runners.Suite.SuiteClasses;
public class DemoTest {
@RunWith(Suite.class)
@SuiteClasses({Demo01.class, Demo02.class, Demo03.class})
public class AllTests {
}
}
首先要为这种测试专门生成一个新的类,而不能与其他测试共用同一个类。
这里不使用默认的Runner了,使用带有参数化功能的Runner。
@RunWith(Parameterized.class)这条语句就是为这个类指定了ParameterizedRunner。
这个需要和我们后面的@Parameters组合使用
放在方法上。
定义一个待测试的类,并且定义两个变量,一个用于存放参数,一个用于存放期待的结果。
定义测试数据的结合,就是下方的prepareData()方法,该方法可以任意命名,但是必须使用@Parameters标注进行修饰。
这里需要注意:其中的数据是一个二维数组,数据两两一组,每组中的这两个数据,一个是参数,一个是预期的结果。比如第一组{2,4}中:2是参数,4是预期结果。这两数据顺序无所谓。
然后,是构造函数,其功能就是对先前定义的两个参数进行初始化。这里要注意参数的顺序,要和上面的数据集合的顺序保持一致。(比如都是先参数后结果)
那么这里我们还是看下面的例子吧
import static org.junit.Assert.assertEquals;
import java.util.Arrays;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.junit.runners.Parameterized;
import org.junit.runners.Parameterized.Parameters;
@RunWith(Parameterized.class)
public class FibonacciTest {
@Parameters(name = "{index}: fib({0})={1}")
public static Iterable<Object[]> data() {
return Arrays.asList(new Object[][] {
{ 0, 0 }, { 1, 1 }, { 2, 1 }, { 3, 2 }, { 4, 3 }, { 5, 5 }, { 6, 8 }
});
}
private int input;
private int expected;
public FibonacciTest(int input, int expected) {
this.input = input;
this.expected = expected;
}
@Test
public void test() {
assertEquals(expected, Fibonacci.compute(input));
}
}
控制测试方法的执行顺序的。
该注解的参数是org.junit.runners.MethodSorters对象。
枚举类org.junit.runners.MethodSorters中定义三种顺序类型:
MethodSorters.JVM:按照JVM得到的方法顺序,即代码中定义的方法顺序。
MethodSorters.DEFAULT:默认的顺序,以确定但不可预期的顺序执行。
MethodSorters.NAME_ASCENDING:按方法名字母顺序执行。
什么是Rule实现
Rule是一组实现了TestRule接口的共享类,提供了验证,监视TestCase和外部资源管理等能力。
即,提供了测试用例执行过程中一些通用功能的共享能力,使不必重复编写一些功能类似的代码。
JUnit4中包含两个注解:@Rule和@ClassRule
用于修饰Field或返回Rule的Method。
两者作用域不同:
Verifier:验证测试执行结果的正确性。
ErrorCollector:收集测试方法中出现的错误信息,测试不会中断,如果有错误发生,测试结束后会标记失败。
ExpectedException:提供灵活的异常验证功能。
Timeout:用于测试超时的Rule。
ExternalResource:外部资源管理。
TemporaryFolder:在JUnit的测试执行前后,创建和删除新的临时目录。
TestWatcher:监视测试方法生命周期的各个阶段。
TestName:在测试方法执行过程中提供获取测试名字的能力。
以上就是这节的全部内容,如有错误,还请各位指正!
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel