hadoop是本文章主要介绍hadoop完全分布式搭建过程。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,是完全开源的,是由java语言编写的。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了分布式存储,而MapReduce则为海量的数据提供了分布式计算
特别注意:hadoop是三台虚拟机之间实现资源调度,非常容易出错,初学者可以反复练习搭建(不成功不要气馁),搭建过程中一定要仔细,哪怕一个字符敲错就可能使得集群不能成功运行。
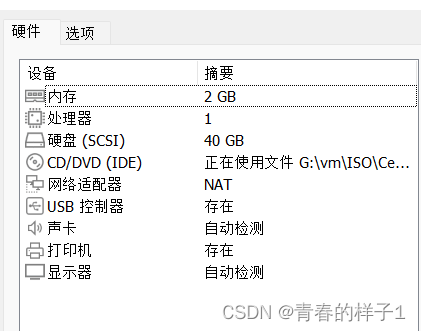
宿主机内存最好16G及以上(可满足同时运行三台虚拟机)
centos7虚拟机3台,使用单核单cpu,2G内存,最小安装方式。(尽可能节省资源)

可以选用vmware提供的虚拟机克隆功能,就可以创建一台虚拟机,克隆两台虚拟机。
利用vmware搭建虚拟机请查看以下连接,有详细的虚拟机创建过程。
以下为虚拟机名称以及IP地址规划
| master | 192.168.6.10 |
| slave1 | 192.168.6.11 |
| slave2 | 192.168.6.12 |
hostnamectl set-hostname master #更改主机名vi /etc/sysconfig/network-scripts/ifcfg-ens33
####配置静态IP地址(你的网卡名可能不为ens33)
BOOTPROTO="static" #更改内容
IPADDR=192.168.6.10 #此行以下为添加内容 设置的为master节点
NETMASK=255.255.255.0
GATEWAY=192.168.6.2 #配置网关,根据自己环境的网关
DNS1=114.114.114.114
NM_CONTROLLER=no #表示该接口将通过该配置文件进行设置,而不是通过网络管理器进行管理。systemctl restart network
vim /etc/hosts
#在文件末尾添加如下内容
192.168.6.10 master
192.168.6.11 slave1
192.168.6.12 slave2验证连通性(三个节点分别验证)

ssh-keygen #按四次回车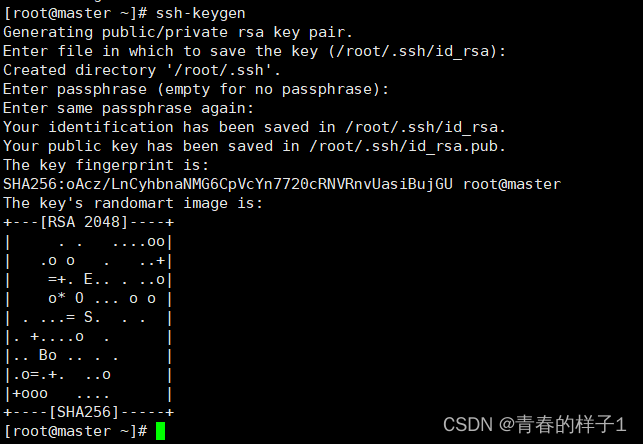
ssh-copy-id master需要输入yes及master节点root用户密码
cat ~/.ssh/authorized_keys
scp -r ~/.ssh/authorized_keys slave1:~/.ssh/
scp -r ~/.ssh/authorized_keys slave2:~/.ssh/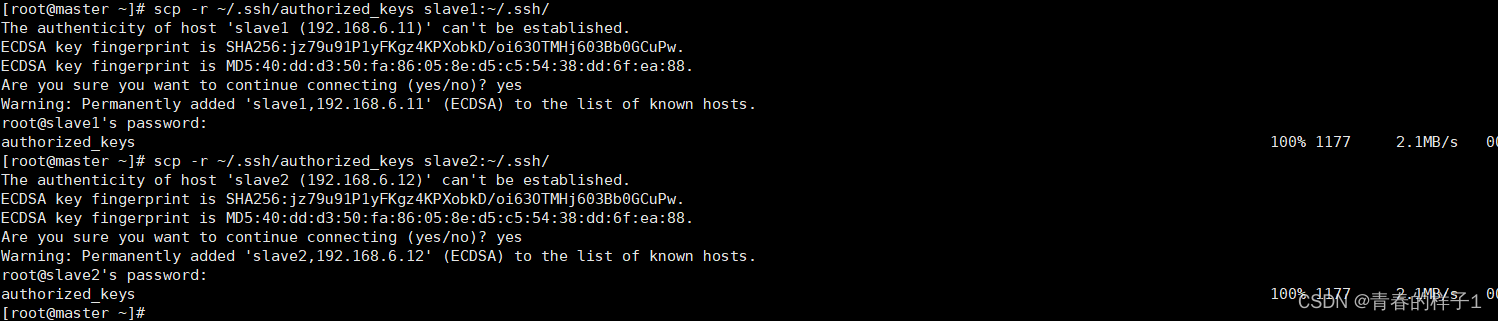
ssh master
ssh slave1
ssh slave2
rm -rf ~/.ssh
yum install ntp -y
ntpdate pool.ntp.org
date
systemctl stop firewalld #关闭防火墙
systemctl disable firewalld #关闭防火墙开机自起
阿里云盘分享
| 名称 | 路径 |
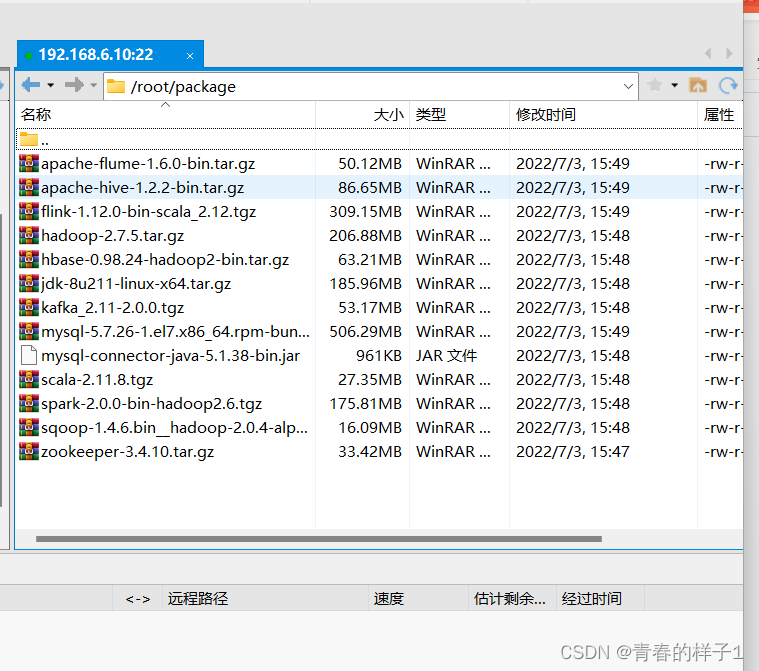
| 安装包存放目录 | /root/package/ |
| 软件安装目录 | /root/soft/ |
| 数据目录 | /root/data/ |
| 日志目录 | /root/log/ |
检查是否存在自带jdk环境
rpm -qa |grep java
如果有自带java环境需要先卸载
rpm -e --nodeps 已安装的jdkmkdir /root/package
mkdir /root/soft

 解压jdk安装包(master执行)
解压jdk安装包(master执行)tar -zxvf /root/package/jdk-8u211-linux-x64.tar.gz -C /root/soft/
mv /root/soft/jdk1.8.0_211/ /root/soft/java
vi /etc/profile 打开文件在末尾添加如下行
export JAVA_HOME=/root/soft/java
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
scp -r /root/soft/java/ slave1:/root/soft/
scp -r /root/soft/java/ slave2:/root/soft/
scp -r /etc/profile slave1:/etc/
scp -r /etc/profile slave2:/etc/

source /etc/profile

tar -zxvf /root/package/hadoop-2.7.5.tar.gz -C /root/soft/
mv /root/soft/hadoop-2.7.5/ /root/soft/hadoop
hadoop-env.sh
hadoop-env.sh文件主要配置跟Hadoop环境相关的变量。
vi /root/soft/hadoop/etc/hadoop/hadoop-env.sh
加入如下内容
export JAVA_HOME=/root/soft/java
core-site.xml
core-site.xml是Hadoop的全局配置文件,主要配置Hadoop的公有属性。
mkdir -p /root/data/hdfs/tmp 创建目录vi /root/soft/hadoop/etc/hadoop/core-site.xml
加入如下配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/data/hdfs/tmp</value>
</property>
</configuration>
hdfs-site.xml
hdfs-site.xml文件主要配置和HDFS相关的属性。
mkdir -p /root/data/hdfs/name
mkdir -p /root/data/hdfs/data
vi /root/soft/hadoop/etc/hadoop/hdfs-site.xml
添加如下配置
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/root/data/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/data/hdfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
mapred-site.xml是MapReduce的配置文件,默认情况下Hadoop中没有该文件,可通过执行cp mapred-site.xml.template mapred-site.xml复制一个,并进行编辑。为了使提交的MapReduce程序运行在分布式模式,而不是本地local模式,可以指定由Yarn作为MapReduce的程序运行框架。
cp /root/soft/hadoop/etc/hadoop/mapred-site.xml.template /root/soft/hadoop/etc/hadoop/mapred-site.xml
vi /root/soft/hadoop/etc/hadoop/mapred-site.xml
加入如下配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
yarn-site.xml文件主要配置YARN的一些信息。
vi /root/soft/hadoop/etc/hadoop/yarn-site.xml
加入如下配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
slaves
slaves文件主要根据集群规划配置DataNode节点所在的主机名,master节点通过该文件获得集群的子节点名称,然后再通过/etc/hosts文件得到各子节点对应的IP,从而与自己进行通信。
vi /root/soft/hadoop/etc/hadoop/slaves
把原有内容删除,修改为如下内容
slave1
slave2vi /etc/profile
末尾添加如下内容
export HADOOP_HOME=/root/soft/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
scp -r /root/soft/hadoop/ slave1:/root/soft/
scp -r /root/soft/hadoop/ slave2:/root/soft/
scp -r /etc/profile slave1:/etc/
scp -r /etc/profile slave2:/etc/source /etc/profile格式化namenode,只能格式化一次,不能重复格式化(master节点)
hdfs namenode -format
在master的终端执行命令start-all.sh启动hadoop集群,该命令可由start-dfs.sh和start-yarn.sh代替,用于分别启动HDFS和YARN。首次启动hadoop时,会提示输入yes/no,输入yes,第二次及以后启动不会输入任何内容。(master)
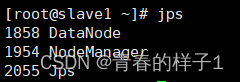
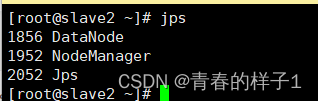
start-all.sh 检查集群启动情况,执行jps指令,若三个节点进程和如下一直,hadoop搭建成功(三个节点)
jps
Hadoop集群启动后,可以在浏览器中查看集群运行情况。
在浏览器中输入http://192.168.6.10:50070(或http://master:50070),可以查看HDFS文件系统上存储的目录和文件等信息,如图显示的是NameNode的信息。

hadoop jar /root/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar pi 1 1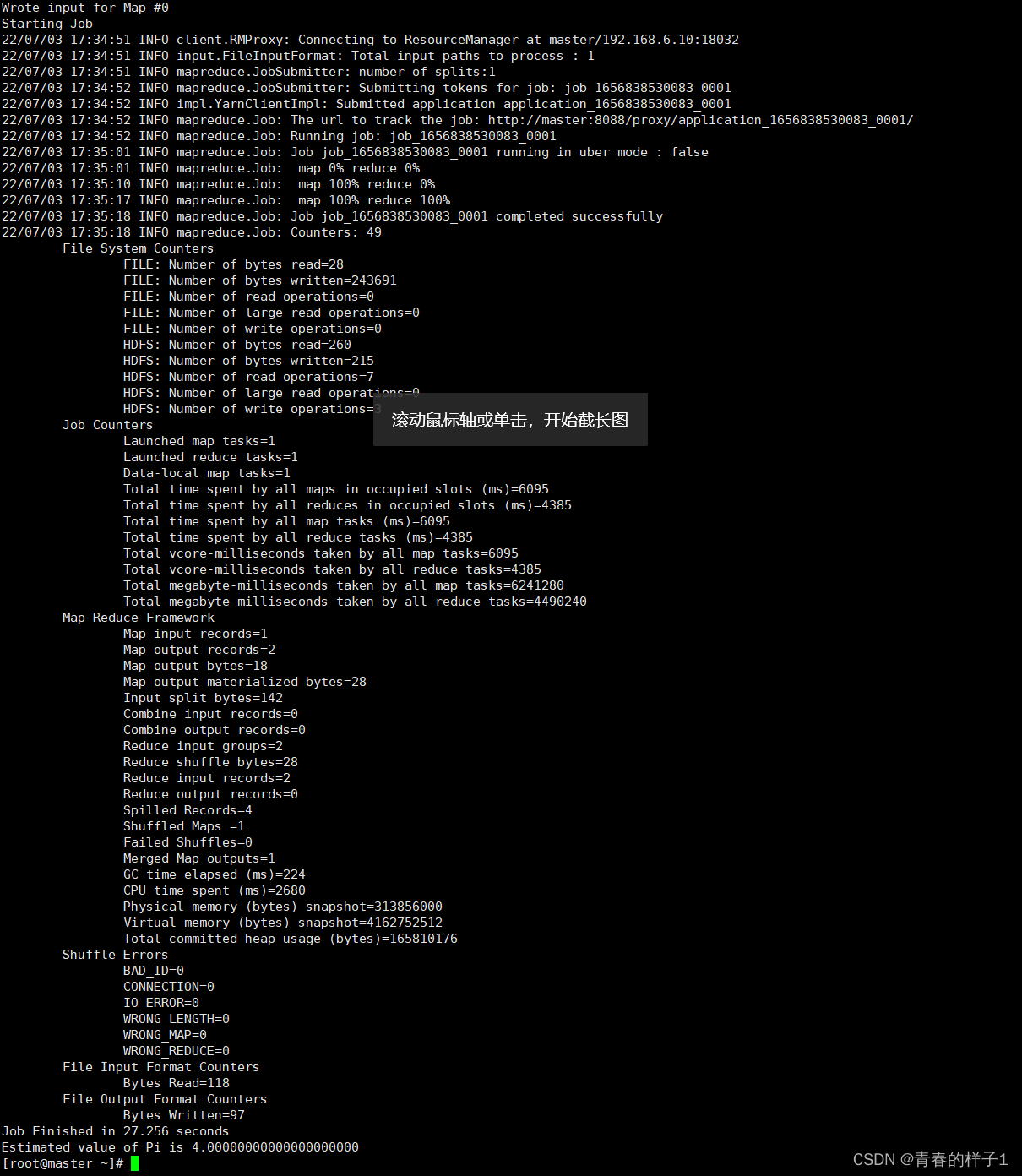
首先,创建目录:mkdir /home/apache/data/test,在这个目录下创建文件wctest.txt

在HDFS文件系统中创建一个hdfstest目录
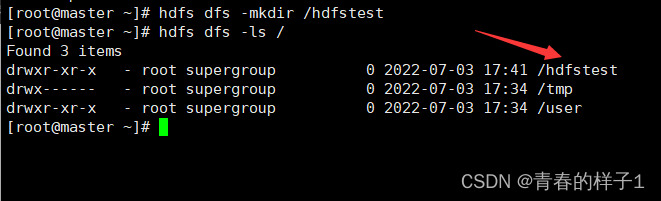

将本地的wctest.txt文件上传到hdfstest目录中
hdfs dfs -put wctest.txt /hdfstest运行Hadoop自带的WordCount程序
hadoop jar /root/soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /hdfstest/wctest.txt /hdfstest/output查看结果
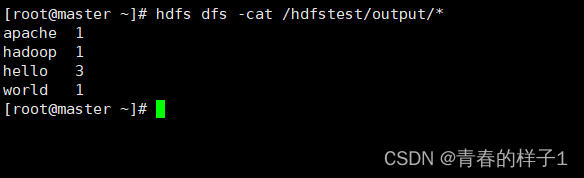
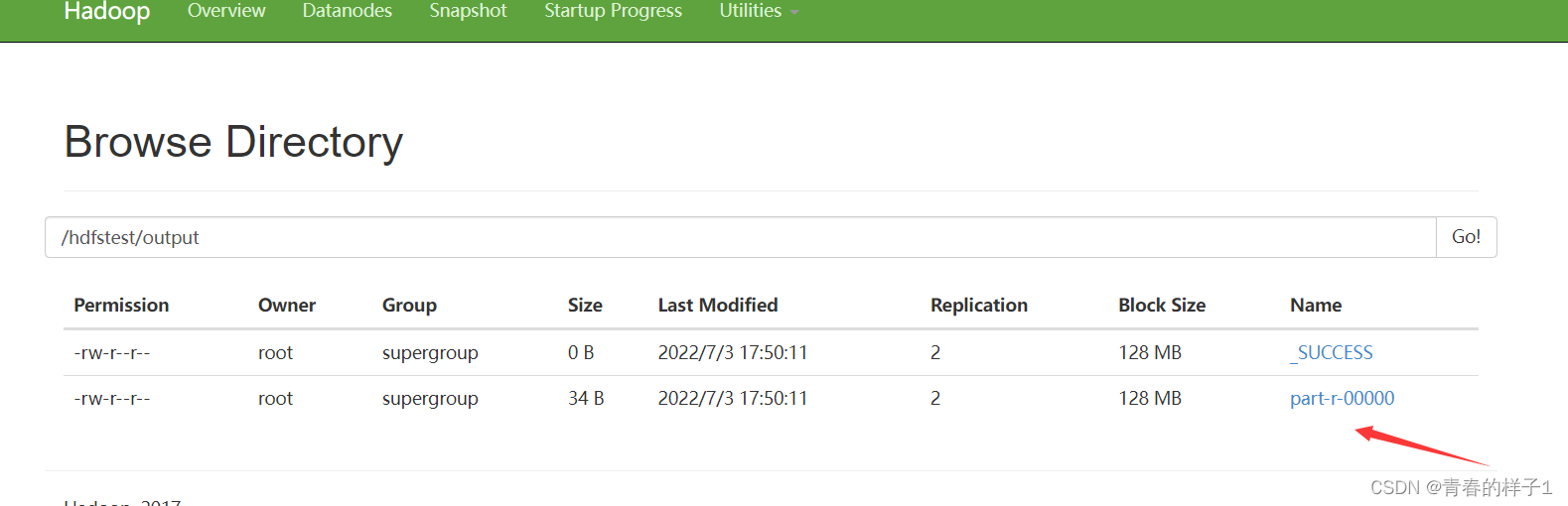
以上测试都没有问题,表明hadoop集群搭建成功。
在master的终端中输入命令用于关闭整个Hadoop集群,如果只是关闭HDFS,可使用stop-hdfs.sh命令。Hadoop集群关闭后,在各个主机上通过jps命令查看进程是否都正常关闭,如果还有僵尸进程存在,则使用kill命令将其杀死。(master)
stop-all.sh
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您