首先,我们需要明确梯度下降就是求一个函数的最小值,对应的梯度上升就是求函数最大值。简而言之:梯度下降的目的就是求函数的极小值点,例如在最小化损失函数或是线性回归学习中都要用到梯度下降算法。
##梯度下降算法作为很多算法的一个关键环节,其重要意义是不言而喻的。
梯度下降算法的思想:先任取点(x0,f(x0)),求f(x)在该点x0的导数f"(x0),在用x0减去导数值f"(x0),计算所得就是新的点x1。然后再用x1减去f"(x1)得x2…以此类推,循环多次,慢慢x值就无限接近极小值点。
损失函数用来衡量机器学习模型的精确度。一般来说,损失函数的值越小,模型的精确度就越高。 如果要提高机器学习模型的精确度,就需要尽可能降低损失函数的值。而降低损失函数的值,我们 一般采用梯度下降这个方法。所以,梯度下降的目的,就是为了最小化损失函数。
我们设定场景来帮助理解:
梯度下降法的基本思想可以类比为一个下山的过程。
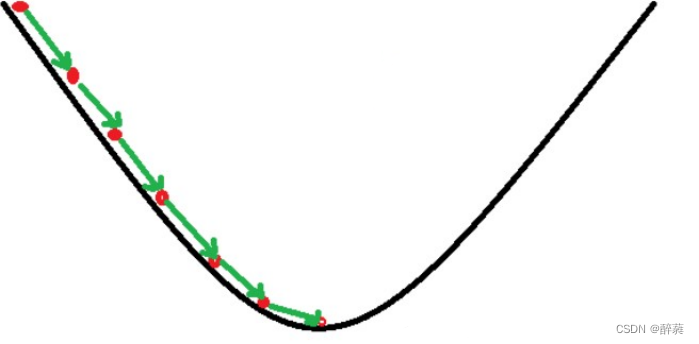
假设这样一个场景:一个人被困在山上(最左上),需要从山上下来(找到山的最低点,也就是山谷)。但此时山上的浓雾很大,导致可视度很低;因此,下山的路径就无法确定,必须利用自己周围的信息一步一步地找到下山的路。这个时候,便可利用梯度下降算法来帮助自己下山。怎么做呢,首先以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着下降方向走一步,然后又继续以当前位置为基准,再找最陡峭的地方,再走直到最后到达最低处。
如上图,假如为山的纵切面,那每次下山一小步,经过N次后你便可以到达山底。
这类似于“走一步,看一步的想法”。在原有的位置上找到能到达的最低点,再以该点为起点继续寻找当前的最低点,以此往复,即可以到达最低处。当然,这样理解比较抽象,所以,下面我们给出数学概念。
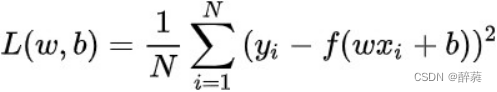
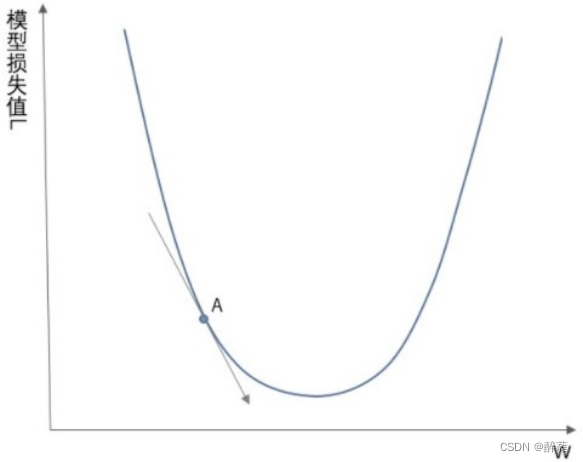
梯度下降其实就是我们学习人工智能算法的一个基本算法,比如我们小学开始接触数学时候我们学习 加减乘除,最基本的算法
一阶函数里梯度就是表示某一函数在该点处的方向导数沿 着该方向取得较大值,即函数在*当前位置的导数*。如果函数为一元函数,梯度就是该函数的导数。
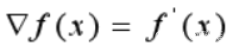
如果为二元函数,梯度定义为:
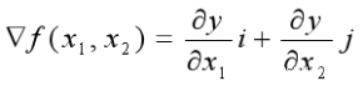
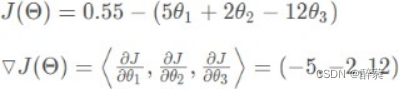
我们可以看到,梯度就是分别对每个变量进行微分,然后用逗号分割开,梯度是用<>包括起来,说明梯度其实一个向量。向量有方向,梯度的方向就指出了函数在给定点的上升最快的 方向。
再看刚才的例子,我们需要到达山底,就需要在每一步观测到此时最 陡峭的地方,梯度就恰巧告诉了我们这个方向。梯度的方向是函数在给定点上升最快的方向,那么梯度 的反方向就是函数在给定点下降最快的方向, 这正是我们所需要的 。所以我们只要沿着梯度的方向一直走,就能走到局部的最低点!
可以看出:单变量函数中,梯度代表的是图像斜率的变化,多变量函数中,梯度代表的是向量,变化最快的地方,即最陡峭的方向
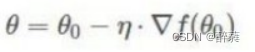

 (学习率)
(学习率)前面一直讨论如何下山最快和如何用数学方法来解决下山最快和下山的方向,那么还忽视了一个问题,就是下山的步子。
我们可以通过来控制每一步走的距离,步长太大走的就容易偏离路线,其实就是不要走太快,错过了最低点。同时也要保证不要走的太慢,导致太阳下山了,还没有走到山下。所以的选择在梯度下降法中往往是很重要的!不能太大也不能太小,太小的话,可能导致迟迟走不到最低点,太大的话,会导致错过最低点!
小步长表现为计算量大,耗时长,但比较精准。
大步长,即较大的a aa,表现为震荡,容易错过最低点,计算量相对较小。
注意:由于函数凹凸性,对于凸函数能够无限逼近其最优解,对于非凸函数,只能获取局部最优解

即:
1、给定待优化连续可微分的函数J(θ),学习率或步长,以及一组初始值(真实值)
2、计算待优化函数梯度
3、更新迭代
4、再次计算新的梯度
5、计算向量的模来判断是否需要终止循环
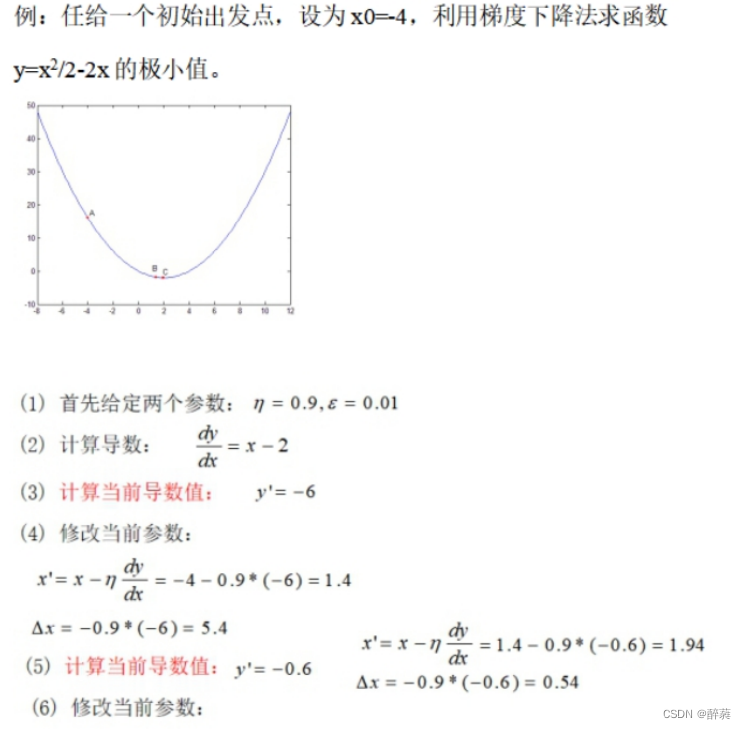

代码段
#f(x)=x^2
import numpy as np
#定义原函数f(x)=x^2
def f(x):
return np.power(x, 2)
#定义函数求导公式1
def d_f_1(x):
return 2.0 * x
#定义函数求导公式2
def d_f_2(f, x, delta=1e-4):
return (f(x+delta) - f(x-delta)) / (2 * delta)
xs = np.arange(-10, 11)# 限制自变量x的范围
plt.plot(xs, f(xs))#绘图
plt.show()
learning_rate = 0.1# 学习率(步长)
max_loop = 30# 迭代次数
x_init = 10.0# x初始值
x = x_init
lr = 0.01# ε值,不过我们下面用的是迭代次数限制
for i in range(max_loop):
# d_f_x = d_f_1(x)
d_f_x = d_f_2(f, x)
x = x - learning_rate * d_f_x
print(x)
print('initial x =', x_init)
print('arg min f(x) of x =', x)
print('f(x) =', f(x))//能做,但不建议使用
#include "stdio.h"
double fun(double x){ //定义初始函数
return x*x/2.0 - 2*x;
}
double der_fun(double x){ //求函数的导数
return x - 2.0;
}
int main(){
double length,accuracy; //定义步长,精确度
double x0,x1; //定义初始位置
printf("请输入步长,精确度及其初始位置:");
scanf("%lf %lf %lf",&length,&accuracy,&x0);
while(length*(-1)*der_fun(x0) > accuracy){
x0 = x0 - length*der_fun(x0);
}
printf("x = %.5lf\ny = %.5lf",x0,fun(x0));
return 0;
}
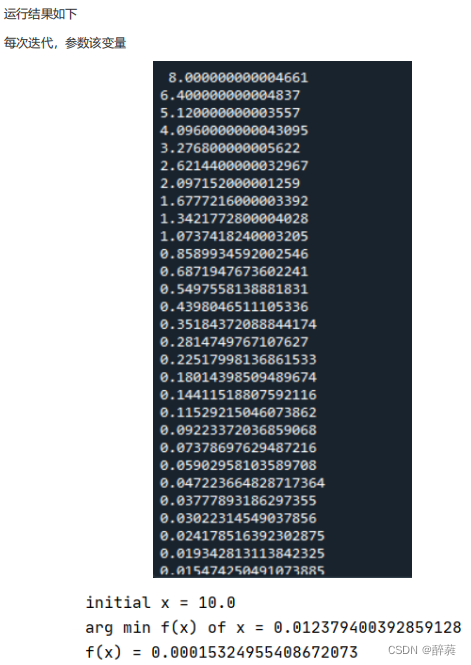
前面所讨论中使用的梯度下降算法公式为: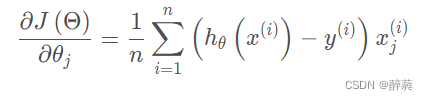
可以看出,计算机会每次从所有数据中计算梯度,然后求平均值,作为一次迭代的梯度,对于高维数据,计算量相当大,因此,把这种梯度下降算法称之为批量梯度下降算法。
随机梯度下降算法是利用批量梯度下降算法每次计算所有数据的缺点,随机抽取某个数据来计算梯度作为该次迭代的梯度,梯度计算公式: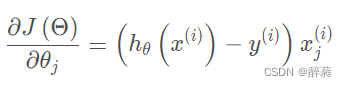
迭代公式可写为: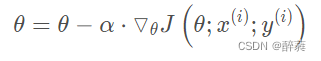
由于随机选取某个点,省略了求和和求平均的过程,降低了计算复杂度,提升了计算速度,但由于随机选取的原因,存在较大的震荡性。
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
3月26日,映宇宙(HK:03700,即“映客”)发布截至2022年12月31日的2022年度业绩财务报告。财报显示,映宇宙2022年的总营收为63.19亿元,较2021年同期的91.76亿元下降31.1%。2022年,映宇宙的经营亏损为4698.7万元,2021年同期则为净利润4.57亿元;期内亏损(净亏损)为1.68亿元,2021年同期的净利润为4.33亿元;非国际财务报告准则经调整净利润为3.88亿元,2021年同期为4.82亿元,同比下降19.6%。 映宇宙在财报中表示,收入减少主要是由于行业竞争加剧,该集团对旗下产品采取更为谨慎的运营策略以应对市场变化。不过,映宇宙的毛利率则有所提升
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s
下面是我写的一个计算斐波那契数列中的值的方法:deffib(n)ifn==0return0endifn==1return1endifn>=2returnfib(n-1)+(fib(n-2))endend它工作到n=14,但在那之后我收到一条消息说程序响应时间太长(我正在使用repl.it)。有人知道为什么会这样吗? 最佳答案 Naivefibonacci进行了大量的重复计算-在fib(14)fib(4)中计算了很多次。您可以将内存添加到您的算法中以使其更快:deffib(n,memo={})ifn==0||n==1returnnen
为了防止在迁移到生产站点期间出现数据库事务错误,我们遵循了https://github.com/LendingHome/zero_downtime_migrations中列出的建议。(具体由https://robots.thoughtbot.com/how-to-create-postgres-indexes-concurrently-in概述),但在特别大的表上创建索引期间,即使是索引创建的“并发”方法也会锁定表并导致该表上的任何ActiveRecord创建或更新导致各自的事务失败有PG::InFailedSqlTransaction异常。下面是我们运行Rails4.2(使用Acti
我正在开发一个类似微论坛的项目,其中一个特殊用户发布一条快速(接近推文大小)的主题消息,订阅者可以用他们自己的类似大小的消息来响应。直截了当,没有任何形式的“挖掘”或投票,只是每个主题消息的响应按时间顺序排列。但预计会有很高的流量。我们想根据它们引起的响应嗡嗡声来标记主题消息,使用0到10的等级。在谷歌上搜索了一段时间的趋势算法和开源社区应用示例,到目前为止已经收集到两个有趣的引用资料,但我还没有完全理解它们:Understandingalgorithmsformeasuringtrends,关于使用基线趋势算法比较维基百科页面浏览量的讨论,在SO上。TheBritneySpearsP
我收到错误:unsupportedcipheralgorithm(AES-256-GCM)(RuntimeError)但我似乎具备所有要求:ruby版本:$ruby--versionruby2.1.2p95OpenSSL会列出gcm:$opensslenc-help2>&1|grepgcm-aes-128-ecb-aes-128-gcm-aes-128-ofb-aes-192-ecb-aes-192-gcm-aes-192-ofb-aes-256-ecb-aes-256-gcm-aes-256-ofbRuby解释器:$irb2.1.2:001>require'openssl';puts
文章目录一.Dijkstra算法想解决的问题二.Dijkstra算法理论三.java代码实现一.Dijkstra算法想解决的问题解决的问题:求解单源最短路径,即各个节点到达源点的最短路径或权值考察其他所有节点到源点的最短路径和长度局限性:无法解决权值为负数的情况二.Dijkstra算法理论参数:S记录当前已经处理过的源点到最短节点U记录还未处理的节点dist[]记录各个节点到起始节点的最短权值path[]记录各个节点的上一级节点(用来联系该节点到起始节点的路径)Dijkstra算法步骤:(1)初始化:顶点集S:节点A到自已的最短路径长度为0。只包含源点,即S={A}顶点集U:包含除A外的其他顶
对于体育新闻中文文本的关键字提取,常用的算法包括TF-IDF、TextRank和LDA等。它们的基本步骤如下:1.TF-IDF算法: -将文本进行分词和词性标注处理。-统计每个词在文本中的词频(TF)。-计算每个词在整个语料库中出现的文档频率(DF)和逆文档频率(IDF)。-计算每个词的TF-IDF值,并按照值的大小进行排序,选择排名前几的词作为关键字。2.TextRank算法:-将文本进行分词和词性标注处理。-将分词结果转化成图模型,每个词语为节点,根据词语之间的共现关系建立边。-对图模型进行迭代计算,计算每个节点的PageRank值,表示该节点的重要性。-选择排名前几的节点作为关键字。3.