数据库(database)保存有组织的数据的容器
表(table)某种特定类型数据的结构化清单。数据库中的每个表都有一个用来标识自己的名字。此名字是唯一的。
模式(schema)关于数据库和表的布局及特性的信息。
列(column)表中的一个字段。所有表都是由一个或多个列组成的。
数据类型(datatype)所容许的数据的类型。每个表列都有相应的数据类型,它限制该列中存储的数据。
行(row)表中的一个记录。
主键(primary key)一列,其值能够唯一标识表中每一行。
结构化查询语言(SQL)Structured Query Language
班级信息ClassInfo
|
班级编号 |
班主任编号 |
学生编号 |
年级 |
|
ClassID |
TeacherID |
StudentID |
Grade |
学生信息StudentInfo
|
学生编号 |
性别 |
年龄 |
身份证 |
学生姓名 |
|
StudentID |
Gender |
Age |
CardID |
StudentName |
学生成绩StudentAchieve
|
学生编号 |
语文 |
数学 |
英语 |
年份 |
班级编号 |
|
StudentID |
Chinese |
Math |
English |
TestYear |
ClassID |
为利用CREATE TABLE创建表,必须给出下列信息:
CREATE TABLE ClassInfo
(
ClassID CHAR(20) NOT NULL, --班级编号
TeacherID CHAR(20) NOT NULL, --班主任编号
StudentID CHAR(20) NOT NULL, --学生编号
Grade CHAR(15) NOT NULL --年级
)CREATE TABLE StudentInfo
(
StudentID CHAR(20) NOT NULL, --学生编号
StudentName CHAR(50) NOT NULL, --学生姓名
Gender CHAR(5) NOT NULL, --性别
Age INT NOT NULL DEFAULT 0, --年龄
CardID VARCHAR(50) NULL DEFAULT '' --身份证
)CREATE TABLE StudentAchieve
(
StudentID CHAR(20) NOT NULL, --学生编号
ClassID CHAR(20) NOT NULL, --班级编号
Chinese DECIMAL(10,5) NOT NULL DEFAULT 0, --语文
Math DECIMAL(10,5) NOT NULL DEFAULT 0, --数学
English DECIMAL(10,5) NOT NULL DEFAULT 0 --英语
)为更新表定义,可使用ALTER TABLE语句。
为了使用ALTER TABLE更改表结构,必须给出下面的信息:
ALTER TABLE dbo.StudentAchieve ADD TestYear CHAR(20) NOT NULL --考试年份添加考试年份的列
ALTER TABLE dbo.StudentAchieve DROP COLUMN TestYear删除考试年份的列
DROP TABLE dbo.StudentAchieve删除学生成绩这张表。删除表没有确认,也不能撤销,执行这条语句将永久删除该表。
注:可使用关系规则防止意外删除
SELECT StudentName FROM dbo.StudentInfo 
SELECT StudentID,Gender,StudentName FROM dbo.StudentInfo 
SELECT * FROM dbo.StudentInfo 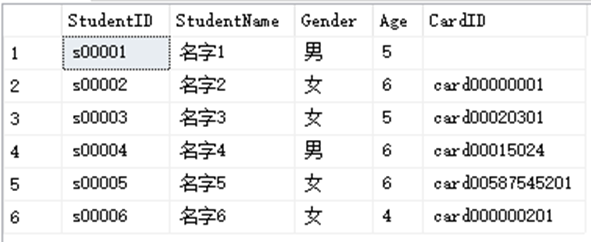
SELECT StudentName FROM dbo.StudentInfo ORDER BY StudentName  Order by子句的位置:应保证它是slect语句中最后一条子句。
Order by子句的位置:应保证它是slect语句中最后一条子句。
SELECT StudentID,Gender,StudentName FROM dbo.StudentInfo ORDER BY StudentName,StudentID 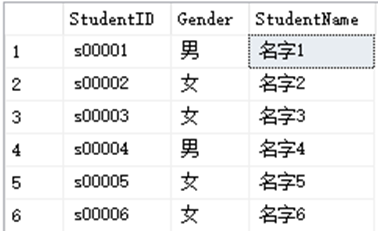
SELECT StudentID,Gender,StudentName FROM dbo.StudentInfo ORDER BY 1,3 
SELECT StudentID,Gender,StudentName FROM dbo.StudentInfo ORDER BY Gender DESC 
DESC降序排列,DESCENDING
ASC升序排列,默认
SELECT StudentID,StudentName FROM dbo.StudentInfo WHERE Age=5 
|
操作符 |
说明 |
|
= |
等于 |
|
<> |
不等于 |
|
!= |
不等于 |
|
< |
小于 |
|
<= |
小于等于 |
|
!< |
不小于 |
|
> |
大于 |
|
>= |
大于等于 |
|
!> |
不大于 |
|
BETWEEN |
再指定的两个值之间 |
|
IS NULL |
为NULL值 |
SELECT StudentID,ClassID FROM dbo.StudentAchieve WHERE Chinese<95 
SELECT * FROM dbo.StudentInfo WHERE CardID <>'' 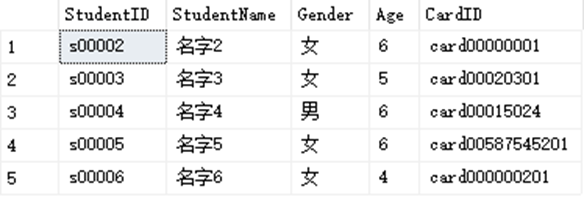
SELECT StudentID,Math FROM dbo.StudentAchieve WHERE Math BETWEEN 90 AND 100 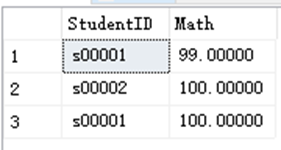
SELECT StudentName,StudentID FROM dbo.StudentInfo WHERE CardID IS NULL 
SELECT StudentID,StudentName FROM dbo.StudentInfo WHERE Gender='女' AND Age=6 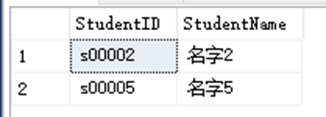
SELECT StudentID,StudentName FROM dbo.StudentInfo WHERE Gender='女' OR Age=6 
SELECT StudentID,StudentName FROM dbo.StudentInfo WHERE Age IN (5,6) 
SELECT StudentID,StudentName,Gender FROM dbo.StudentInfo WHERE NOT Gender='女' 
通配符(wildcard)用来匹配值的一部分的特殊字符。
搜索模式(search pattern)由字面值、通配符或两者组合构成的搜索条件。
SELECT StudentID,StudentName,CardID FROM dbo.StudentInfo WHERE CardID LIKE 'card%' 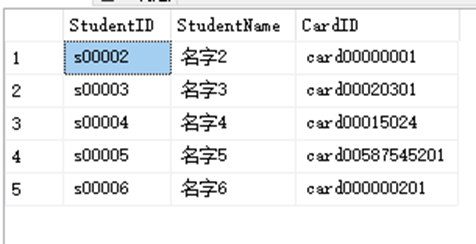
检索任意以card起头的词。
%告诉DBMS接受card之后的任意字符,不管他有多少字符。
SELECT StudentID,StudentName,CardID FROM dbo.StudentInfo WHERE CardID LIKE '%01%' 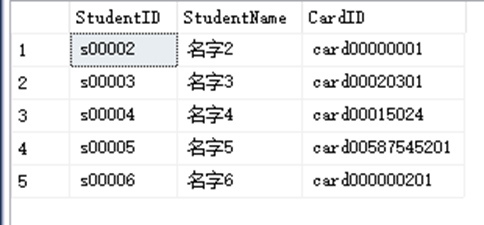
%可以匹配0个字符。%代表搜索模式中给定位置的0个、1个或多个字符。
下划线的用途与%一样,但下划线只匹配一个字符而不是多个字符。
SELECT StudentID,StudentName,CardID FROM dbo.StudentInfo WHERE StudentName LIKE '名_2' 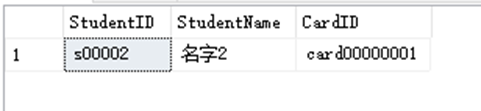
方括号通配符用来指定一个字符集,它必须匹配指定位置得一个字符。
SELECT * FROM dbo.StudentInfo WHERE CardID LIKE 'card000[23]%' 
找出以card0002或card0003开头得cardid
此通配符可以用前缀字符^(脱子号)来否定。
SELECT * FROM dbo.StudentInfo WHERE CardID LIKE 'card000[^23]%' 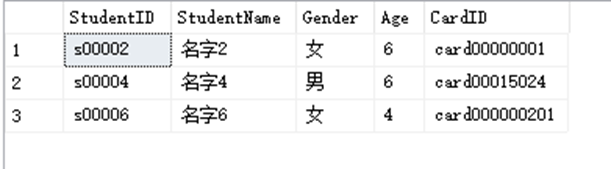
字段(field)基本上与列(column)的意思相同,经常互换使用,不过数据列一般称为列,而术语字段通常用在计算字段的连接上。
拼接(concatenate)将值联结到一起构成单个值。
SELECT StudentID+'name: '+StudentName FROM dbo.StudentInfo 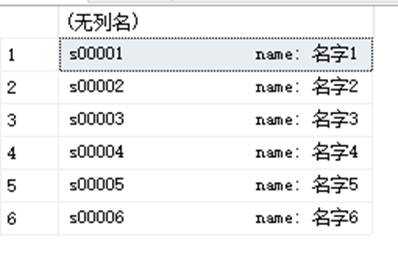
SELECT RTRIM(StudentID)+'name: '+RTRIM(StudentName) FROM dbo.StudentInfo RTRIM()函数去掉右边的所有空格。 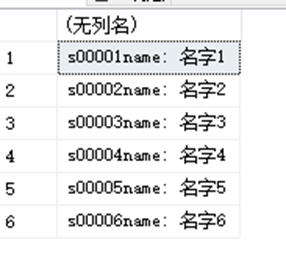
SELECT RTRIM(StudentID)+'name: '+RTRIM(StudentName) info FROM dbo.StudentInfo 使用别名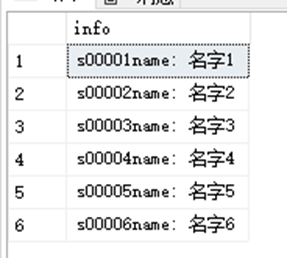
SELECT StudentID,Chinese+Math+English AS total FROM dbo.StudentAchieve 
可移植(portable)所编写的代码可以在多个系统上运行。
SELECT StudentID,UPPER(CardID) cardinfo FROM dbo.StudentInfo UPPER()将文本转换为大写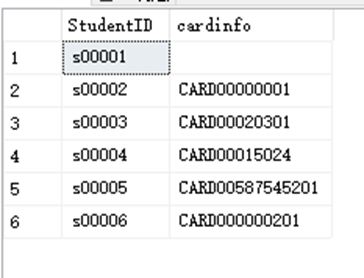
常用的文本处理函数
|
函数 |
说明 |
|
LEFT() |
返回串左边的字符 |
|
LENGTH() |
返回串的长度 |
|
LOWER() |
将串转换为小写 |
|
LTRIM() |
去掉串左边的空格 |
|
RIGHT() |
返回串右边的字符 |
|
RTRIM() |
去掉串右边的空格 |
|
SOUNDEX() |
返回串的SOUNDEX值 |
|
UPPER() |
将串转换为大写 |
SOUNDEX()函数是一个将任何文本串转换为描述其语音表达的字母数字模式的算法。SOUNDEX考虑了类似的发音字符和音节,使得能对串进行发音比较而不是字母比较。
日期和时间采用相应的数据类型存储在表中,每种DBMS都有自己的变体。日期和时间值以特殊的格式存储,以便能快速和有效地排序或过滤,并且节约物理存储空间。
|
函数 |
说明 |
|
ABS() |
绝对值 |
|
COS() |
余弦 |
|
EXP() |
指数 |
|
PI() |
圆周率 |
|
SIN() |
正弦 |
|
SQRT() |
平方根 |
|
TAN() |
正切 |
聚集函数(aggregate function)运行在行组上,计算和返回单个值的函数。
|
函数 |
说明 |
|
AVG() |
平均值 |
|
COUNT() |
行数 |
|
MAX() |
最大值 |
|
MIN() |
最小值 |
|
SUM() |
和 |
SELECT AVG(Chinese) AS avg_chinese FROM dbo.StudentAchieve 
SELECT AVG(Chinese) AS avg_chinese_11 FROM dbo.StudentAchieve WHERE ClassID='c00011' 
AVG()只能用来确定特定数值列的平均值,而且列名必须作为函数参数给出。只能用于单个列。
AVG()函数忽略值为NULL的行。
COUNT()函数又两种使用方式
SELECT COUNT(*) AS num FROM dbo.StudentInfo 
SELECT COUNT(StudentID) AS num FROM dbo.StudentInfo 
SELECT MAX(Math) AS max_math FROM dbo.StudentAchieve 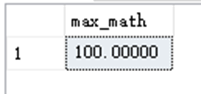
SELECT MIN(Math) AS min_math FROM dbo.StudentAchieve 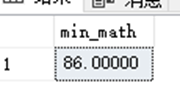
SELECT sum(Math) AS sum_math FROM dbo.StudentAchieve 
SELECT sum(Math+Chinese) AS total FROM dbo.StudentAchieve 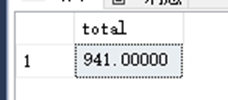
以上5个聚集函数都可以如下使用:
SELECT AVG(distinct Math) AS math_avg FROM dbo.StudentAchieve 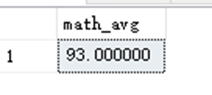
SELECT COUNT(*) as num_count,MIN(Math) AS min_math,MAX(Math) AS max_math FROM dbo.StudentAchieve 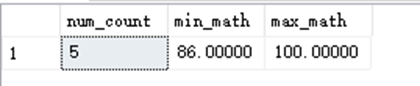
SELECT COUNT(*) AS math_95 FROM dbo.StudentAchieve WHERE Math>95 
SELECT StudentID,COUNT(*) AS column1 FROM dbo.StudentAchieve GROUP BY StudentID 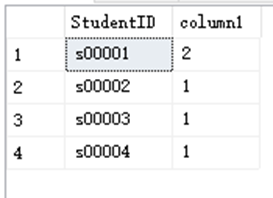
在具体使用GROUP BY子句前,需要知道一些重要的规定:
SELECT StudentID,COUNT(*) AS column1 FROM dbo.StudentAchieve GROUP BY StudentID HAVING COUNT(*)=2 
ORDER BY与GROUP BY
|
ORDER BY |
GROUP BY |
|
排序产生的输出 任意列都可以使用(甚至非选择的列也可以使用) 不一定需要 |
分组行。但输出可能不是分组的顺序 只可能使用选择列或表达式列,而且必须使用每个选择列表达式 如果与聚集函数一起使用列(或表达式),则必须使用 |
|
子句 |
说明 |
是否必须使用 |
|
SELECT |
要返回的列或表达式 |
是 |
|
FROM |
从中检索数据的表 |
仅在从表选择数据时使用 |
|
WHERE |
行级过滤 |
否 |
|
GROUP BY |
分组说明 |
仅在按组计算聚集时使用 |
|
HAVING |
组级说明 |
否 |
|
ORDER BY |
输出排序顺序 |
否 |
查询(query)任何SQL语句都是查询。
SQL还允许创建子查询(subquery),即:嵌套在其他查询中的查询。
SELECT StudentName FROM dbo.StudentInfo WHERE StudentID IN ( SELECT StudentID FROM dbo.StudentAchieve WHERE Math > 95 ); 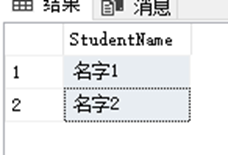
SELECT StudentID,( SELECT COUNT(*)FROM dbo.StudentAchieve WHERE StudentID = StudentID) AS column1 FROM dbo.StudentInfo; 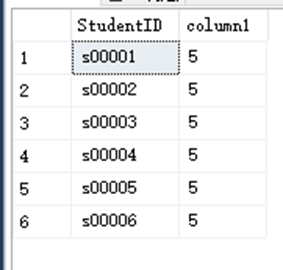
可伸缩性(scale)能够适应不断增加的工作量而不失败。设计良好的数据库或应用程序称之为可伸缩性好、
SELECT StudentName,Math, Chinese FROM dbo.StudentInfo,dbo.StudentAchieve WHERE StudentAchieve.StudentID = StudentInfo.StudentID; 
笛卡儿积(cartesian product)由没有联结条件的表关系返回的结果为笛卡儿积。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。
SELECT StudentName,Math,Chinese FROM dbo.StudentInfo,dbo.StudentAchieve 
SELECT StudentName, Math,Chinese FROM dbo.StudentInfo INNER join dbo.StudentAchieve ON StudentAchieve.StudentID = StudentInfo.StudentID 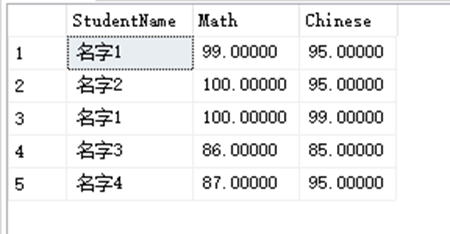
SELECT StudentName,Math,Chinese, Grade FROM dbo.StudentInfo,dbo.StudentAchieve, dbo.ClassInfo
WHERE StudentInfo.StudentID = StudentAchieve.StudentID AND ClassInfo.StudentID = StudentAchieve.StudentID AND Math > 90; 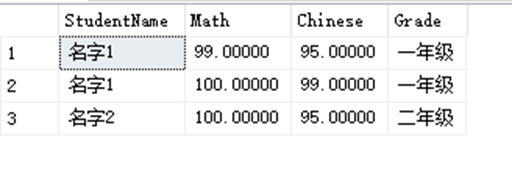
SELECT StudentName,Math, Chinese,Grade FROM dbo.StudentInfo AS a, dbo.StudentAchieve AS b, dbo.ClassInfo AS c
WHERE a.StudentID = b.StudentID AND c.StudentID = a.StudentID AND Math > 90; 
SELECT StudentID,StudentName,Gender FROM dbo.StudentInfo WHERE Gender =( SELECT Gender FROM dbo.StudentInfo WHERE StudentID = 's00001') 
SELECT a.StudentID,a.StudentName,a.Gender FROM dbo.StudentInfo AS a,dbo.StudentInfo AS b WHERE a.Gender = b.Gender AND b.StudentID = 's00001'; 
SELECT StudentName,Math, Chinese,Grade FROM dbo.StudentInfo AS a, dbo.StudentAchieve AS b, dbo.ClassInfo AS c WHERE a.StudentID = b.StudentID AND c.StudentID = a.StudentID AND Math > 90; 
SELECT StudentName,Gender,Math,Chinese FROM dbo.StudentInfo LEFT JOIN dbo.StudentAchieve ON StudentAchieve.StudentID = StudentInfo.StudentID; 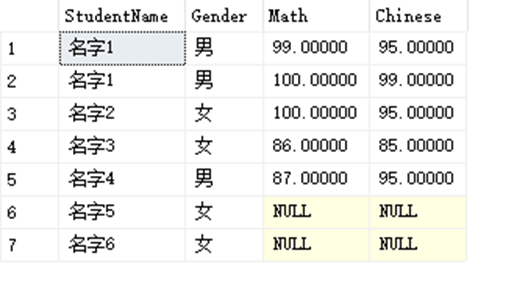
SELECT StudentName,Gender,Math,Chinese FROM dbo.StudentInfo RIGHT JOIN dbo.StudentAchieve ON StudentAchieve.StudentID = StudentInfo.StudentID; 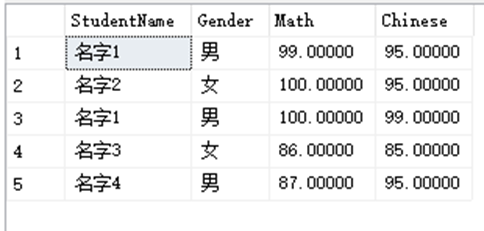
SELECT Grade,COUNT(Age) AS age_count,Age FROM dbo.StudentInfo INNER JOIN dbo.ClassInfo ON ClassInfo.StudentID = StudentInfo.StudentID GROUP BY ClassInfo.Grade,Age 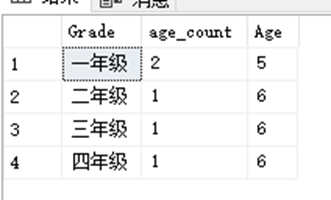
SQL允许执行多个查询,并将结果作为单个查询结果集返回。这些组合查询通常称为并(union)或复合查询(compound query)。
SELECT StudentID,StudentName,Age,Gender FROM dbo.StudentInfo WHERE Age=5
UNION
SELECT StudentID,StudentName,Age,Gender FROM dbo.StudentInfo WHERE Gender='男' 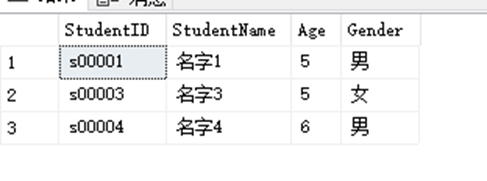
SELECT StudentID,StudentName,Age,Gender FROM dbo.StudentInfo WHERE Age=5 OR Gender='男' 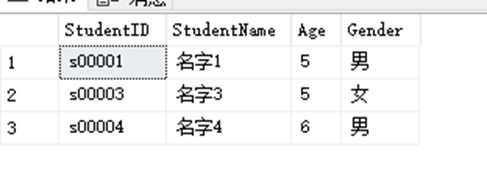
SELECT StudentID,StudentName,Age,Gender FROM dbo.StudentInfo WHERE Age=5
UNION ALL
SELECT StudentID,StudentName,Age,Gender FROM dbo.StudentInfo WHERE Gender='男' 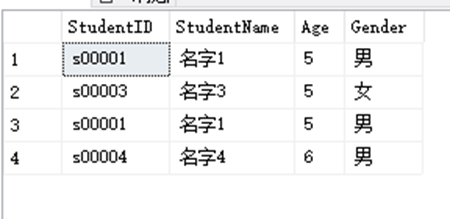
SELECT StudentID,StudentName,Age,Gender FROM dbo.StudentInfo WHERE Age=5
UNION
SELECT StudentID,StudentName,Age,Gender FROM dbo.StudentInfo WHERE Gender='男'
ORDER BY Gender 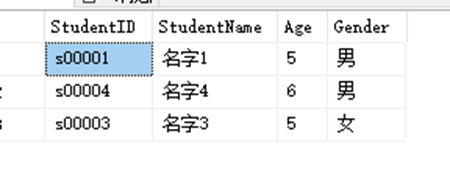
INSERT INTO dbo.StudentInfo
VALUES( 's00010','新的名字', '男',7,'cardcard' ) 
更标准的写法:
INSERT INTO dbo.StudentInfo(StudentID,StudentName,Gender,Age,CardID)
VALUES('s00010','新的名字','男',7,'cardcard')INSERT INTO dbo.StudentInfo( StudentID,StudentName,Gender, Age)
VALUES( 's00014','新的名字2', '女',7)INSERT INTO dbo.StudentInfo(StudentID,StudentName,Gender,Age)
VALUES('s00014','新的名字2', '女',7)SELECT * INTO #tmp1 FROM dbo.StudentInfoUPDATE dbo.StudentInfo SET CardID='cardnew' WHERE StudentID='s00002' AND Age=7DELETE FROM dbo.StudentInfo WHERE StudentID='s00002' AND Age=7视图不包含任何列或数据,它包含的是一个查询。
CREATE VIEW student_view
AS
SELECT StudentName,Gender,Math,Chinese FROM dbo.StudentInfo LEFT JOIN dbo.StudentAchieve ON StudentAchieve.StudentID = StudentInfo.StudentID;CREATE VIEW student_view
AS
SELECT RTRIM(StudentID)+'('+RTRIM(StudentName)+')' AS stuinfo FROM dbo.StudentInfoSELECT * FROM student_view 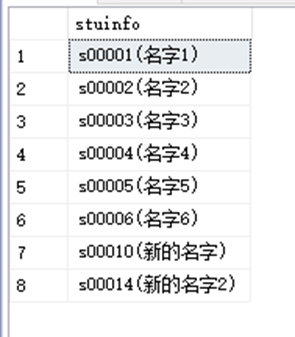
存储过程简单来说,就是为了以后的使用而保存的一条或多条SQL语句的集合。可将其视为批文件。
简单、安全、高性能。
EXECUTE
EXECUTE后面跟着存储过程和需要传递给它的任何参数。
CREATE PROCEDURE test
AS
DECLARE @n INTEGER
SELECT @n=COUNT(*) FROM dbo.StudentInfo WHERE CardID IS NOT NULL
RETURN @n事务处理(transaction processing)可以用来维护数据库的完整性,它保证成批的SQL操作要么完全执行,要么完全不执行。
BEGIN TRANSACTION operation
--****
COMMIT TRANSACTION operationROLLBACK operationSAVE TRANSACTION operation结果集(result set)SQL查询所检索出的结果。
游标(cursor)是一个存储在DBMS服务器上的数据库查询,它不是一条SELECT语句,二十被该语句检索出来的结果集。
DECLARE testcursor CURSOR
FOR
SELECT StudentID FROM dbo.StudentInfoDECLARE @n [char] (20)
DECLARE testcursor CURSOR
FOR
SELECT StudentID FROM dbo.StudentInfo
OPEN testcursor
FETCH NEXT FROM testcursor INTO @n
BEGIN
--***
FETCH NEXT FROM testcursor INTO @n
ENDCLOSE testcursor约束(constraint)管理如何插入或梳理数据库数据的规则
表中任意列只要满足以下条件,都可以用于主键:
外键是表中的一个列,其值必须再另一个表的主键中列出。
外键可以帮助防止意外的删除。
唯一约束用来保证一个列(或一组列)中的数据唯一。
检查约束用来保证一个列(或一组列)中的数据满足一组指定的条件。
CHECK
CREATE INDEX
CREATE TRIGGER
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我找到了这样的东西:Rails:Howtolistdatabasetables/objectsusingtheRailsconsole?这一行没问题:ActiveRecord::Base.connection.tables并返回所有表但是ActiveRecord::Base.connection.table_structure("users")产生错误:ActiveRecord::Base.connection.table_structure("projects")我认为table_structure不是Postgres方法。如何列出Postgres数据库的Rails控制台中表中的所有
Ruby中防止SQL注入(inject)的好方法是什么? 最佳答案 直接使用ruby?使用准备好的语句:require'mysql'db=Mysql.new('localhost','user','password','database')statement=db.prepare"SELECT*FROMtableWHEREfield=?"statement.execute'value'statement.fetchstatement.close 关于ruby-防止SQL注入(inject
我正在编写一个Rails应用程序,它将监视某些特定数据库的数据质量。为了做到这一点,我需要能够对这些数据库执行直接SQL查询——这当然与用于驱动Rails应用程序模型的数据库不同。简而言之,这意味着我无法使用通过ActiveRecord基础连接的技巧。我需要连接的数据库在设计时是未知的(即:我不能将它们的详细信息放在database.yaml中)。相反,我有一个模型“database_details”,用户将使用它来输入应用程序将在运行时执行查询的数据库的详细信息。因此与这些数据库的连接实际上是动态的,细节仅在运行时解析。 最佳答案
我正在使用Rails4应用程序,它需要创建大量对象以响应来自另一个系统的事件。当我调用create!时,主键列上出现非常频繁的ActiveRecord::RecordNotUnique错误(由PG::UniqueViolation引起)我的模型之一。我在SO上找到了其他答案,建议挽救异常并调用retry:beginTableName.create!(data:'here')rescueActiveRecord::RecordNotUnique=>eife.message.include?'_pkey'#Onlyretryprimarykeyviolationslog.warn"Retr
我有一个PORO(普通旧Ruby对象)来处理一些业务逻辑。它接收一个ActiveRecord对象并对其进行分类。为了简单起见,以下面为例:classClassificatorSTATES={1=>"Positive",2=>"Neutral",3=>"Negative"}definitializer(item)@item=itemenddefnameSTATES.fetch(state_id)endprivatedefstate_idreturn1if@item.value>0return2if@item.value==0return3if@item.value但是,我还想根据这些st
我正在使用ARincludes在对象User和Building之间执行LEFTOUTERJOIN的方法,其中User可能有也可能没有Building关联:users=User.includes(:building).references(:buildings)因为我正在使用references,任何关联的Building对象都将被预先加载。我的期望是我随后能够遍历用户列表,并检查用户是否有与其关联的建筑物而不会触发额外的查询,但实际上每当我尝试访问建筑物属性时我都会看到对于没有建筑物的用户,AR会进行另一个SQL调用以尝试检索该建筑物(尽管在后续尝试中它只会返回nil)。这些查询显然是
我有以下模型:activity.rbtag.rbtagging.rb标签是事件和标签的连接模型。我想搜索具有2个或更多标签的事件。我如何在Rails中执行此操作?例如:我有tag1=Christmas,tag2=Florida,tag3=John如果存在,我想找到tag1、tag2和tag3存在的Activity。[编辑]我最终做了什么:tags=[tag1,tag2,tag3]activities=[]tags.eachdo|tag|activities如果任何组值的大小等于tags.size,则该事件包含所有标签。 最佳答案 如
在我的Rails应用程序中,我有users,它可以有许多invoices,而invoices又可以有许多payments。现在在dashboardView中,我想总结一个user曾经收到的所有payments,按年、季度或月。付款也分割为毛额、Netty和税额。user.rb:classUser:items).allpayments_with_invoice.select{|x|range.cover?x.date}.sum(&:"#{kind}_amount")endend发票.rb:classInvoicepayment.rb:classPaymentdashboards_cont