文章目录
首先先要介绍一下C语言中一些常见的存储单元
bit 存放一个二进制位
Byte 1Byte = 8 bit
KB 1KB = 1024 Byte
MB 1MB = 1024 KB
GB 1GB = 1024 MB
TB 1TB = 1024 GB
PB 1PB = 1024 TB
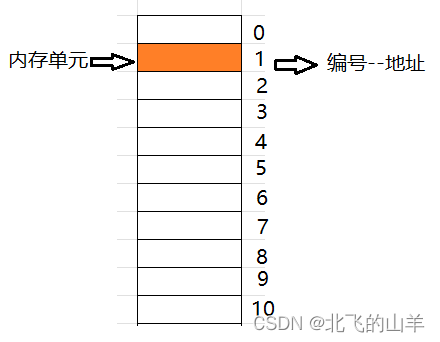
一个内存单元的大小占一个字节(Byte)。内存单元是一片连续的空间,对其的编号也是连续的。
如下图所示:
接下来,我们来探讨一下地址编号是如何产生的:
其实,在我们的计算机上,存在着这样的一种物理的电线,叫地址线。地址线一旦通电以后,就会产生电信号,形成高电平或者低电平。高低电平信号可以转换成数字信号,对应的就是1或者0。32位机器上有32根地址线,32根地址线通电后32个电平信号就可以转换成对应的32位的01二进制序列。

从上图可以看到,32根地址线产生的地址编号总共就有个。假设32个0序列用来管理上上图中0编号所指向的内存单元,31个0序列和最后的一个1所组成的序列用来管理1号所指向的内存单元,以此类推。这样,物理电线上所产生的电信号转换成的数字信号就可以被用来管理内存单元。也就是说,32位机器下就可以管理就可以管理
个Byte大小的内存,也就是4GB大小的内存。
1. 第一个成员在与结构体偏移量为0的地址处。
2. 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。注意:对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。(VS中默认的对齐数为8)
3. 结构体总大小为:最大对齐数(所有变量类型最大者与默认对齐参数取最小)的整数倍。
4. 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
下面我将对这四条规则进行解释:
1.第一个成员在与结构体偏移量为0的地址处。
首先我们应理解什么是偏移量,见下图:
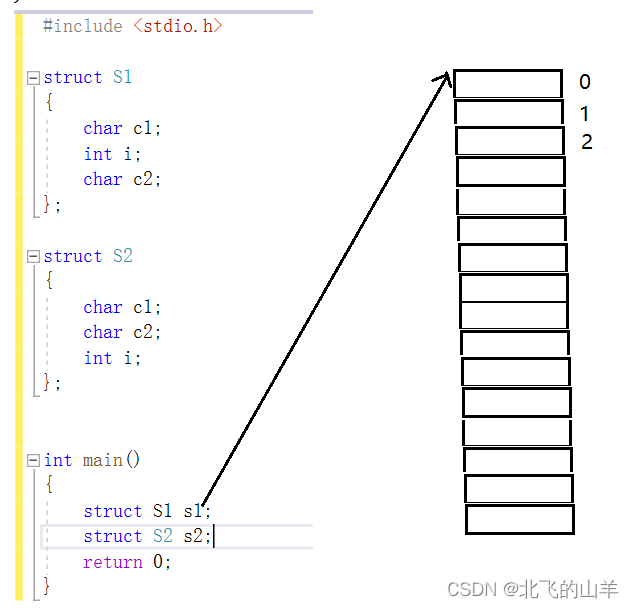
假定由结构体S1创建出的s1在内存中的起始位置是图中所指向的横线,那么其下面的第一个存储单元的偏移量就是0,s1的第一个成员就从偏移量为0这个存储单元开始存储。
2.其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。注意:对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。(VS中默认的对齐数为8)
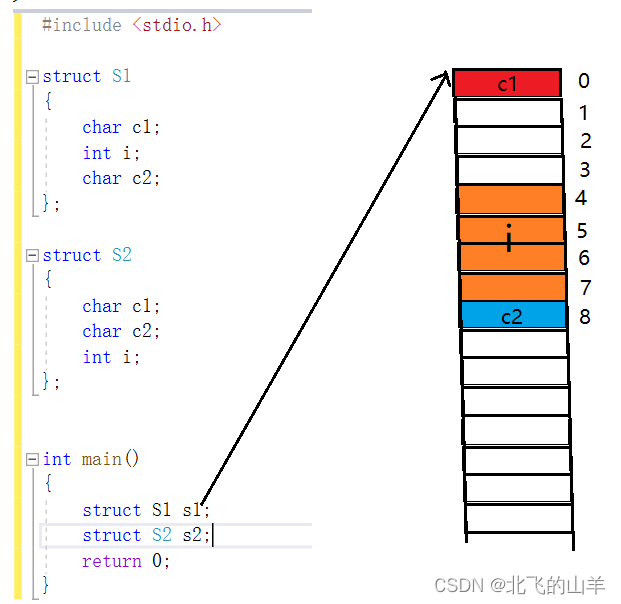
如图所示:c1是s1的第一个成员,存放在偏移量为0处,s1的第二个成员i的类型为int,大小为4个Byte,因为4小于8,所以i这个变量应该从偏移量为4的倍数处开始存放,存放4个Byte。最后c2的大小为1,从偏移量为1的倍数处开始存放,即紧跟着i变量存储即可。
3.结构体总大小为:最大对齐数(所有变量类型最大者与默认对齐参数取最小)的整数倍。
以上图中的S1来举例,其三个成员的类型分别为char,int,char,类型大小分别为1,4,1,所以所有变量类型最大者即为int,其大小为4Byte,小于VS的默认对齐参数(8Byte),所以最大对齐数为4,即创建出来的结构体变量s1的大小必须为4的倍数。从上图可知,此时s1已经占用了9个Byte,但还需向内存申请3个Byte大小的空间,构成12个Byte大小的空间,即s1的大小占12个Byte。
4. 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
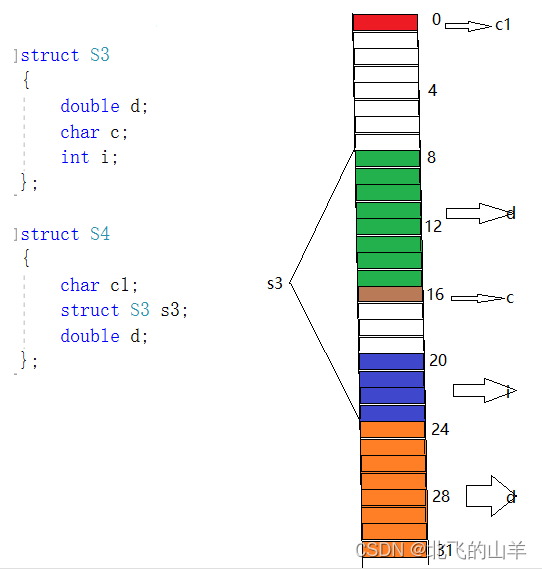
由上图以及两个结构体成员可知,S3的最大默认对齐数是8,所以s3的第一个成员要从偏移量为8的位置开始存放,其他存放规则与上面三条规则相同,最终S4的大小占32个Byte。
1. 平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2. 性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。
原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
为什么未对齐的内存,处理器需要作两次内存访问呢?见下图:
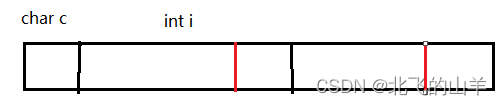
在32位机器下,一次可以访问4个Byte,假设不采用内存对齐的方式,int类型的变量前有一个char类型的变量c,那么处理器要完全访问到i,第一次需要先访问c变量以及i变量的前三个字节,第二次再访问i的最后一个字节,这样就需要访问两次才能完全访问完i。
总体来说:
结构体的内存对齐是拿空间来换取时间的做法。
那在设计结构体的时候,我们既要满足对齐,又要节省空间,我们应该:
让占用空间小的成员尽量集中在一起。
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我的工作要求我为某些测试自动生成电子邮件。我一直在四处寻找,但未能找到可以快速实现的合理解决方案。它需要在outlook而不是其他邮件服务器中,因为我们有一些奇怪的身份验证规则,我们需要保存草稿而不是仅仅发送邮件的选项。显然win32ole可以做到这一点,但我找不到任何相当简单的例子。 最佳答案 假设存储了Outlook凭据并且您设置为自动登录到Outlook,WIN32OLE可以很好地完成此操作:require'win32ole'outlook=WIN32OLE.new('Outlook.Application')message=