PostgreSQL 高可用数据库的常见搭建方式主要有两种,逻辑复制和物理复制,上周已经写过了关于在Windows环境搭建PostgreSQL逻辑复制的教程,这周来记录一下 物理复制的搭建方法。
首先介绍一下逻辑复制和物理复制的一些基本区别:
关于 Windows 系统 PostgreSQL 的安装方法可以直接看之前的博客 Windows 系统 PostgreSQL 手工安装配置方法
如果追求高性能,高一致性的数据库复制备份方案建议采用物理复制的方式。
搭建物理复制模式的主从订阅首先要调整主实例的 postgresql.conf 文件
wal_level = replica
synchronous_commit = remote_apply

因为我们采用的 synchronous_commit = remote_apply 是同步复制的模式,该模式可以理解为同步复制,当客户端像主实例提交事务之后,需要等 synchronous_standby_names 总配置的节点全部完成 remote_apply 收到数据之后,主实例才会给备库返回事务成功提交的状态,创建好名为 s 的订阅创建之后,我们再次打开 主实例的 postgresql.conf 文件进行调整设置
synchronous_standby_names = 's'

当有多个从实例从主实例同步的时候synchronous_standby_names 还可以采用以下配置模式
这里有一点需要注意,这是 PostgreSQL 在同步复制时的一个已知问题,假设 一个主实例,一个备库 s1,采用同步模式,然后 synchronous_standby_names 配置为 synchronous_standby_names='s1',虽然从配置上来看似乎数据必须要提交到s1并且s1成功响应之后,主实例才会为客户端返回事务操作成功的响应,但是实际情况下,当备库挂掉的情况下,主实例在收到一个事务操作时,在等待 s1 备库的返回时因为 s1库已经挂掉了所以这个操作肯定会超时,当主备节点通信超时之后,主节点还是会像客户端返回事务成功提交的命令,客户端的操作还是会成功,同时因为每个事务操作都要经历这个超时的流程,所以客户端的所有事务操作都会相对很卡。
比如每个 insert 都会经过主实例和备库的这个通信超时过程,所以每个 insert 动作都变成了大约30秒次才能完成,就会导致应用程序很卡。这时候就相当于主实例在以(很卡的)独立模式运行,这个情况在备库重新上线之后就会恢复正常(如果备库短期之内无法恢复,可以调整主实例的 synchronous_standby_names设置 移除对于s1备库的事务等待验证,变为单库运行模式重启实例之后也就不会卡了),但是要注意当主实例脱离备库独立运行时,如果这个时候主实例发生灾难比如硬盘坏掉,则就会产生数据丢失。所以建议至少有2个从实例来提升保障级别。
然后还需要调整主实例的 pg_hba.conf,添加 replication 模式的连接白名单配置。
host replication all 0.0.0.0/0 scram-sha-256
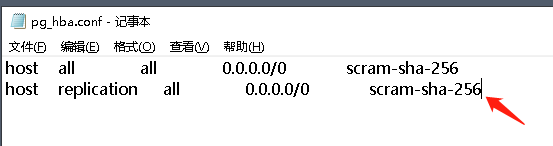
调整配置文件之后记得重启主实例。
主实例重启之后,我们还需要连接到主实例创建复制槽,默认情况下WAL归档文件是循环滚动清理,这就会导致一个问题如果我们的从实例挂机之后离线的时间较长,就有可能因为主实例的WAL文件已经循环滚动删除了,这种情况下就算从实例修复好之后重新上线,因为主实例的部分WAL归档文件已经清理了,也无法再追赶上我们主实例的数据进度,从实例会直接报错。因为有这种场景的存在所以 PostgreSQL 里面出现了一个复制槽的概念,主实例可以创建多个复制槽,一个复制槽绑定给一个从实例使用,复制槽的好处在于会确保从实例获取到WAL文件之后才会进行清理,不会有前面说的滚动循环自动清理的问题。
复制槽的维护都在主实例进行:创建,查询,删除的语句如下
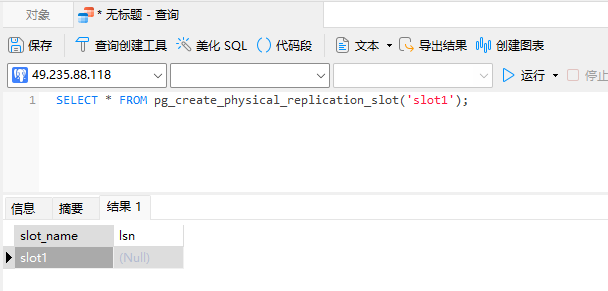
创建复制槽
SELECT * FROM pg_create_physical_replication_slot('slot1');
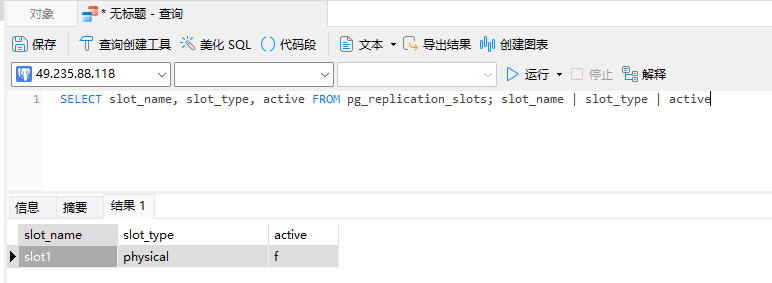
查询全部的复制槽
SELECT slot_name, slot_type, active FROM pg_replication_slots; slot_name | slot_type | active
删除复制槽
SELECT * FROM pg_drop_replication_slot('slot1')
至此主实例的配置就都完成了,接下来就是准备我们的从实例,可以直接停止主实例的运行,然后把PostgreSQL文件夹和Data整体打包压缩复制一份到新的服务器上启动起来作为从实例。
我这里选择直接把云服务器上的 PostgreSQL 打包压缩然后复制到本地解压,作为从实例
在本地解压之后,做为 从实例 需要做如下的调整,postgresql.conf
primary_conninfo = 'host=x.x.x.x port=5432 user=postgres password=xxxxxx application_name=s'
primary_slot_name = 'slot1'
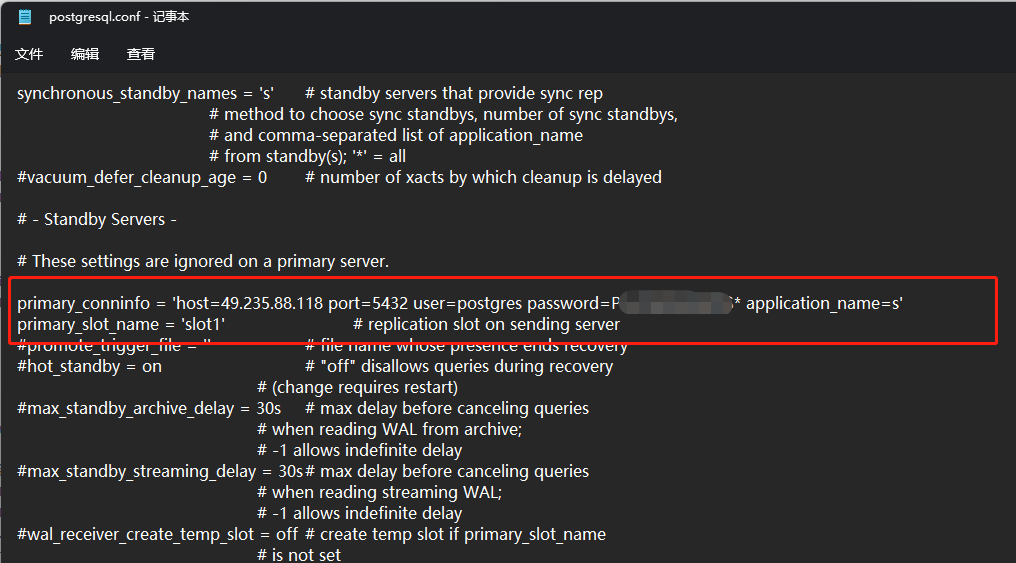
primary_conninfo 主要内容就是我们主实例的连接字符串信息然后加一个 application_name ,application_name 和我们前面在主实例上配置的 synchronous_standby_names 关联,前面我们配置了主实例的所有事务操作都需要同步等待 名字为 s 的备库执行完成
primary_slot_name 则是复制槽的名称我们前面创建了一个 slot1 的复制槽,给我们的这个从实例使用。
这里需要注意一点,在配置的时候如果有多个从实例,则一个从实例对应一个复制槽,绑定一个 application_name。
然后在 data 目录下新建一个空文件
standby.signal
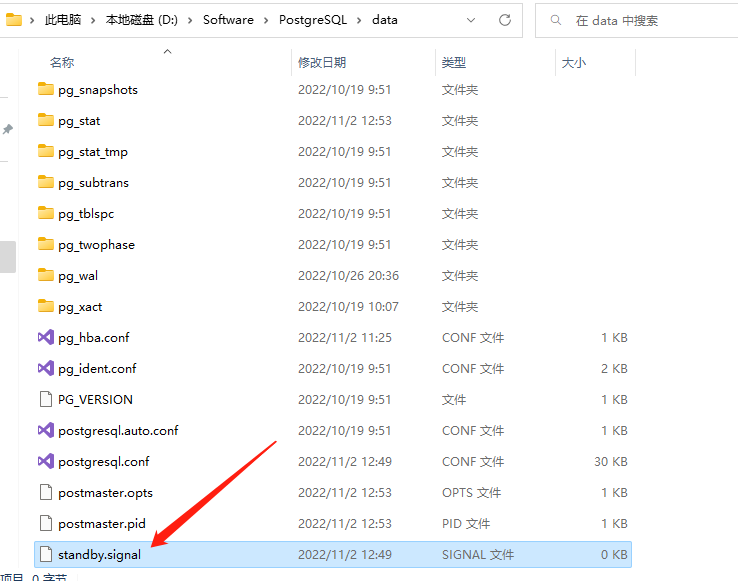
这个文件的其实一个信号标记,标识我们当前的实例时一个只读实例,不可以用于数据插入。
然后启动备库就可以了,正常情况会看到如下界面
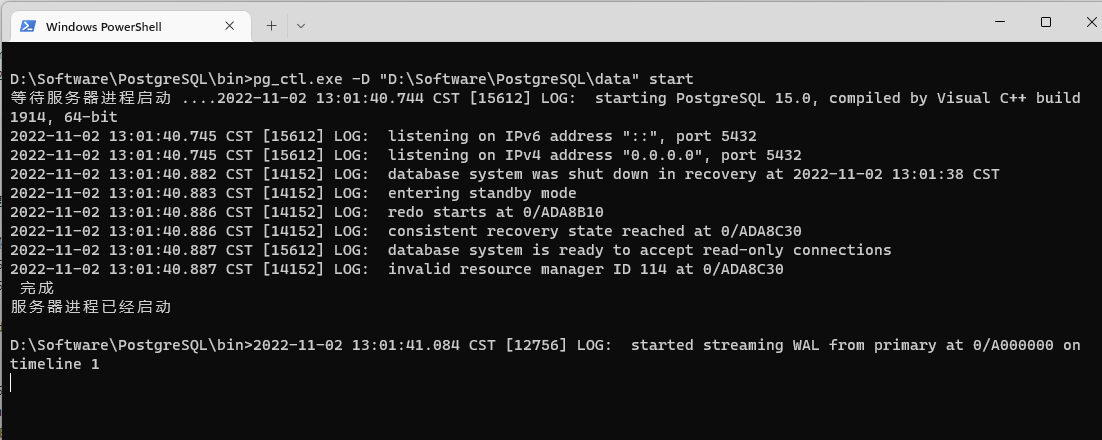
这时候我们可以尝试去主实例创建一个数据库做一些操作,然后连接从实例,就会发现两边都是互相同步的。
如果要解除从实例和主实例的关联,操作如下:
从主实例的 postgresql.conf 找到 synchronous_standby_names 删除 s 节点的配置
#synchronous_standby_names='s'
如果只有一个从节点的,则直接添加 # 对 synchronous_standby_names 进行注释即可
调整之后重启主实例。
然后打开从实例的 postgresql.conf,注释
#primary_conninfo
#primary_slot_name
配置节点的信息,然后删除 data 目录下的 standby.signal 文件,重新启动从实例即可。
至此 Windows 环境搭建 PostgreSQL 物理复制高可用架构数据库服务 就讲解完了,有任何不明白的,可以在文章下面评论或者私信我,欢迎大家积极的讨论交流,有兴趣的朋友可以关注我目前在维护的一个 .NET 基础框架项目,项目地址如下
https://github.com/berkerdong/NetEngine.git
https://gitee.com/berkerdong/NetEngine.git
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我试图在rails中了解rubygems是如何变得可以自动使用的,而不是在使用required的文件中gem? 最佳答案 这是通过bundler/setup完成的:http://bundler.io/v1.3/bundler_setup.html.它在您的config/boot.rb文件中是必需的。简而言之,它首先将环境变量设置为指向您的Gemfile:ENV['BUNDLE_GEMFILE']||=File.expand_path('../../Gemfile',__FILE__)然后它通过要求bundler/setup将所有ge
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration
我已经找到了几个使用datamapper的示例,并且能够让它们正常工作。不过,所有这些示例都是针对sqlite数据库的。我正在尝试将数据映射器与postgresql一起使用。我将datamapper中的调用从sqlite3更改为postgres,并且我已经安装了dm-postgres-adapter。但它仍然不起作用。我还需要做什么? 最佳答案 与SQLite不同,PostgreSQL不将数据库存储在单个文件中。在你拥有createdyourdatabase之后,尝试这样的事情:DataMapper.setup:default,{: