使用feign之前需要引入相关的依赖 (在服务消费端也就是客户端使用)
<!--Spring Cloud OpenFeign Starter -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
application.yml
server:
port: 8195
spring:
cloud:
nacos:
discovery:
server-addr: 192.168.122.131:8848
application:
name: Feign-consumerOpenFeign提供了日志打印的功能,我们可以调整日志的输出级别,去了解OpenFeign的http请求的细节。即对OpenFeign远程接口调用的情况进行监控和日志输出。
OpenFeign的日志级别:
OpenFeign的默认日志级别为NONE,不记录任何请求信息,SpringBoot默认的日志级别是info,而FeignClient日志级别是debug,debug<info。所以当我们修改完FeignClient的日志级别后,需要修改SpringBoot的日志级别为debug,日志输出才会生效。
application.yml文件的配置:
feign:
client:
config:
default: #表示所有的feign 也可以写具体的feign
loggerLevel: full #开启feign日志
logging:
level:
com.xxx.feign: debug
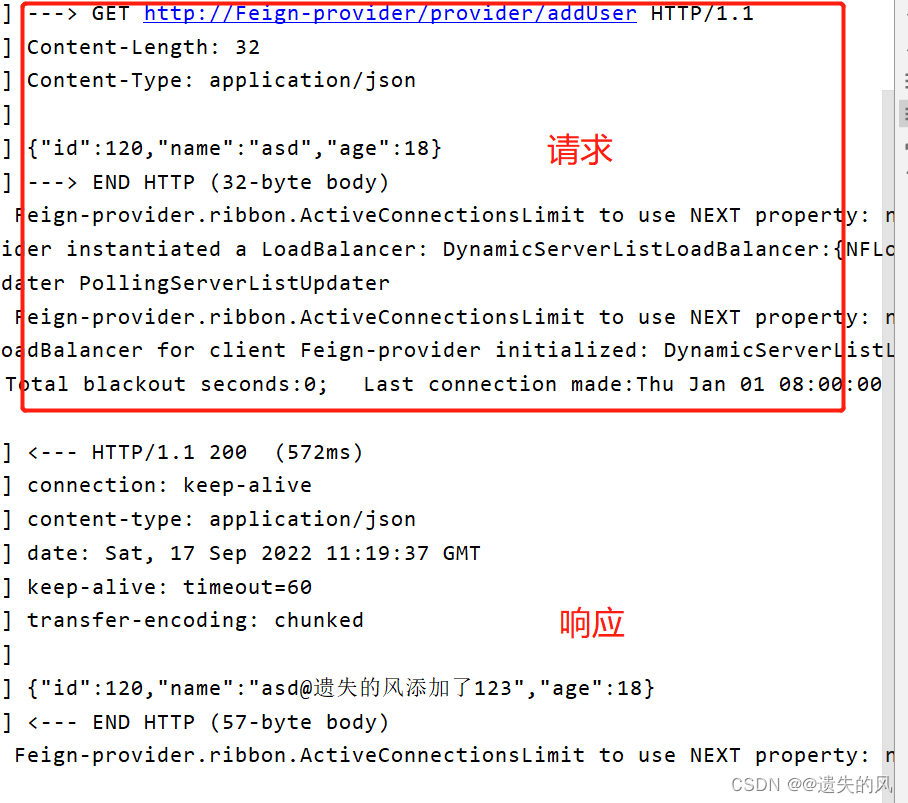
Feign默认使用HttpURLConnection去发送请求,每次请求都会建立、关闭连接,很消耗时间。但是Feign还支持使用Apache的httpclient 以及OKHTTP去发送请求,其中Apache的HTTPClient和OKHTTP都是支持连接池的。
http连接池省去了tcp的3次握手和4次挥手的时间,可以节约大量的时间。
使用httpclient
1,加入依赖
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>2,application.yml文件的配置:
feign:
httpclient:
enabled: true #默认是ture 可以不写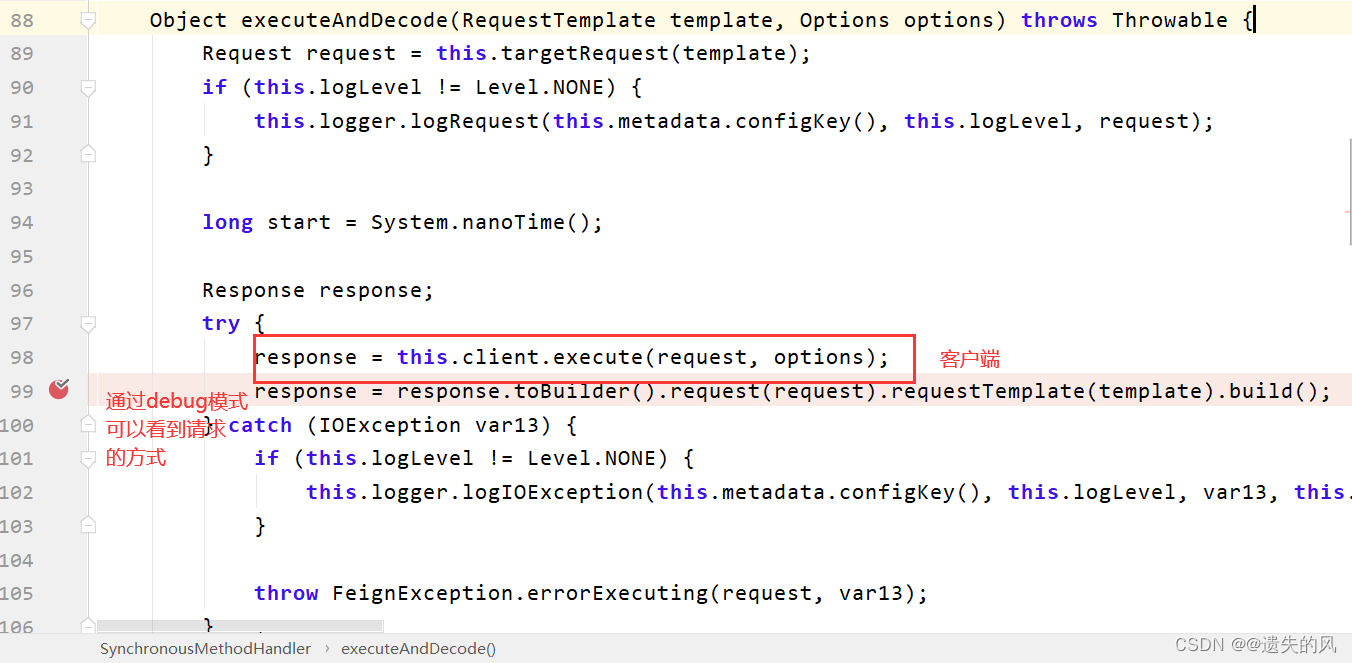
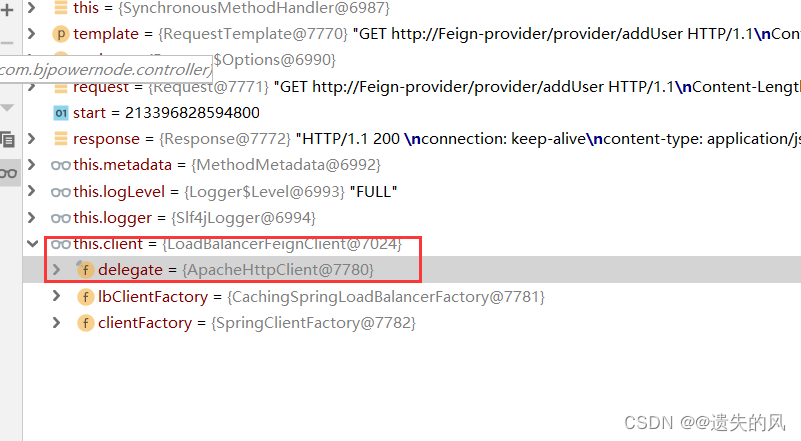 如图我们可以看到使用的是http连接池的方式。
如图我们可以看到使用的是http连接池的方式。
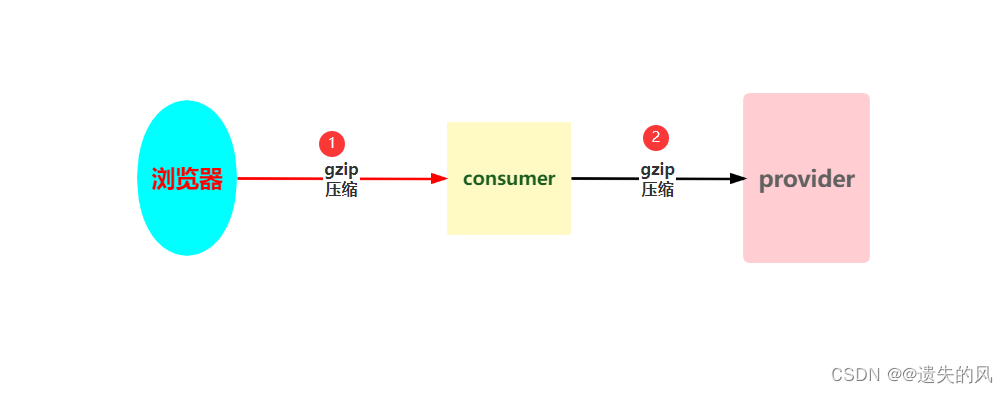
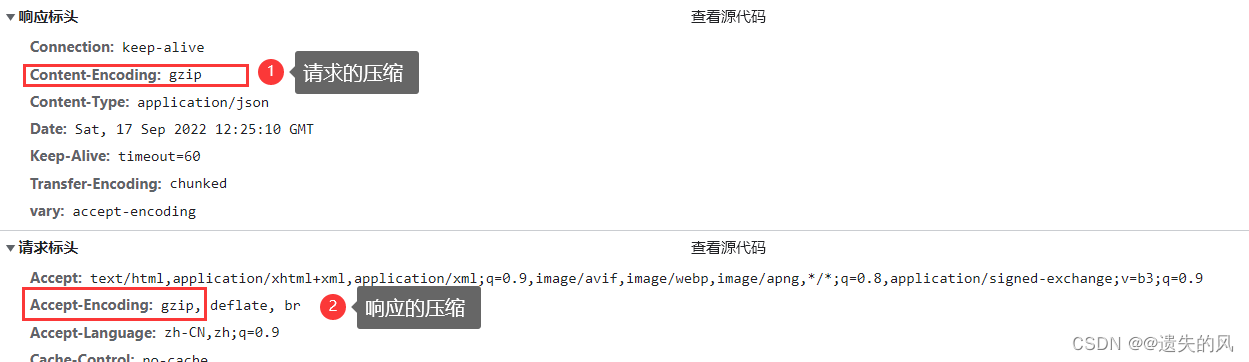
减少文件大小有两个明显的好处,一是可以减少存储空间,二是通过网络传输文件时,可以减少传输的时间。gzip 是在 Linux 系统中经常使用的一个对文件进行压缩和解压缩的命令,既方便又好用。
介绍:Gzip是若干种文件压缩程序的简称,是一种数据可是,采用DEFLATE无损数据压缩算法。
作用:Gzip压缩纯文本是的效果非常好,可以减少70%以上的文件大小,压缩后可以大大降低了网络传输的字节数,使用Gzip的好处就是可以加快网页加载的速度
1,项目中启用gzip压缩:1和2两过程可以只开一个压缩,也可以两个过程都开压缩
# (1)浏览器和consumer之间的压缩
server:
compression: #是否开启压缩
enabled: true #浏览器<------>consumer的gzip压缩
#配置支持的压缩mime-types 下面的是默认值,可以不写
mime-types: text/html,text/xml,text/plain,application/xml,application/json
# (2)consumer与provider之间的压缩
feign:
compression:
request:
enabled: true #consumer<------>provider的gzip压缩
#配置支持的压缩mime-types 下面的是默认值,可以不写
mime-types: text/html,text/xml,text/plain,application/xml,application/json
response:
enabled: true
对服务提供的peovider的service实现类改造
@Override
public User addUser(User user) {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
user.setName(user.getName() + "@遗失的风添加了123");
return user;
}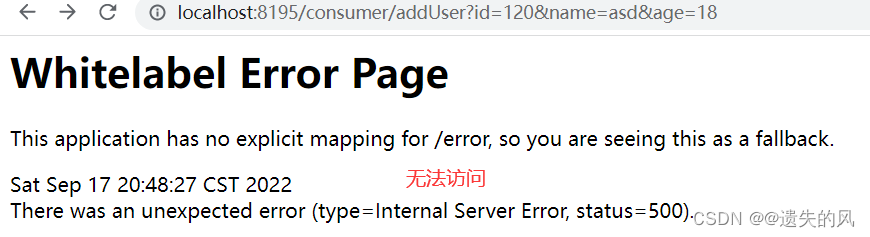
 在平时,会因为网速慢等原因导致访问超时,所以提高连接超时时间和读取超时时间可以有效的提高程序的性能。
在平时,会因为网速慢等原因导致访问超时,所以提高连接超时时间和读取超时时间可以有效的提高程序的性能。
application.yml文件的配置:
ribbon:
ConnectionTimeout: 5000
ReadTimeout: 5000
#或者是
# client:
# config:
# default:
# Feign-provider: #具体的某个服务的超时配置
# ConnectionTimeout: 5000
# ReadTimeout: 5000 
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
LL库和HAL库简介LL:Low-Layer,底层库HAL:HardwareAbstractionLayer,硬件抽象层库LL库和hal库对比,很精简,这实际上是一个精简的库。LL库的配置选择如下:在STM32CUBEMX中,点击菜单的“ProjectManager”–>“AdvancedSettings”,在下面的界面中选择“AdvancedSettings”,然后在每个模块后面选择使用的库总结:1、如果使用的MCU是小容量的,那么STM32CubeLL将是最佳选择;2、如果结合可移植性和优化,使用STM32CubeHAL并使用特定的优化实现替换一些调用,可保持最大的可移植性。另外HAL和L
是否存在GC.disable会降低性能的情况?只要我使用的是真正的RAM而不是交换内存,就可以这样做吗?我正在使用MRIRuby2.0,据我所知,它是64位的,并且使用的是64位的Ubuntu:ruby2.0.0p0(2013-02-24revision39474)[x86_64-linux]Linux[redacted]3.2.0-43-generic#68-UbuntuSMPWedMay1503:33:33UTC2013x86_64x86_64x86_64GNU/Linux 最佳答案 GC.disable将禁用垃圾回收。像rub
我希望Ruby的解析器会进行这种微不足道的优化,但似乎并没有(谈到YARV实现,Ruby1.9.x、2.0.0):require'benchmark'deffib1a,b=0,1whileb由于这两种方法除了在第二种方法中使用预定义常量而不是常量表达式外是相同的,因此Ruby解释器似乎在每个循环中一次又一次地计算幂常数。是否有一些Material说明为什么Ruby根本不进行这种基本优化或只在某些特定情况下进行? 最佳答案 很抱歉给出了另一个答案,但我不想删除或编辑我之前的答案,因为它下面有有趣的讨论。正如JörgWMittag所说,
我尝试在Internet上搜索有关使用angularJS进入RubyonRails项目与RubyonRailspure的View性能的信息。我的问题是因为2个月前我开始使用纯AngularJS,现在我需要将AngularJS集成到一个新项目中,但需要展示使用带有RubyonRails的AngularJS呈现View的性能如何,并消除对RubyonRails的负担.例如:带Rails的Angular:使用RubyonRails获取数据(从数据库或GET请求),将信息发送到file.js.erb并使用AngularJS操作数据并显示带有解析数据的View。纯粹的Rails:(自然流程)使用
我觉得我理解require和require_dependency之间的区别(来自Howarerequire,require_dependencyandconstantsreloadingrelatedinRails?)。但是,我想知道如果我使用一些不同的方法(参见http://hemju.com/2010/09/22/rails-3-quicktip-autoload-lib-directory-including-all-subdirectories/和Bestwaytoloadmodule/classfromlibfolderinRails3?)来加载所有文件会发生什么,所以我们:
我正在尝试从数据库中读取大量单元格(超过100.000个)并将它们写入VPSUbuntu服务器上的csv文件。碰巧服务器没有足够的内存。我正在考虑一次读取5000行并将它们写入文件,然后再读取5000行,等等。我应该如何重构我当前的代码以使内存不会被完全消耗?这是我的代码:defwrite_rows(emails)File.open(file_path,"w+")do|f|f该函数由sidekiqworker调用:write_rows(user.emails)感谢您的帮助! 最佳答案 这里的问题是,当您调用emails.each时,