2022 年 9 月 24 日,阿里云用户组(AUG)第 12 期活动在厦门举办。活动现场,阿里云消息中间件研发工程师刘睿,向参会企业代表分享了阿里云消息生态及最佳实践。本文根据演讲内容整理而成。
众所周知,消息中间件作为现代软件体系中的底层基础软件,和数据库一样广泛应用于各种场景中。比如大数据 ETL、日志处理、IoT 的一些场景以及事件分发,还有 SaaS 集成等这些各种各样的场景里面都需要用到消息中间件。
消息全家桶:简单、稳定、开源

面对如此众多的消息中间件应用场景,阿里云在消息产品这一块也有非常丰富的产品矩阵。其中,有主打业务消息和订单交易场景的 Rocket MQ;有在国际上知名度也比较高、主打业务日志流式处理的数据通路消息产品 Kafka;还有其他一些面向细化场景业务的产品,例如对标开源,作为业务消息选型补充的 Rabbit MQ,面向 IoT 领域的消息队列 MQTT,以及轻量版的 Rocket MQ——消息服务 MNS。这些产品,组成了阿里云的比较完整的消息中间件产品的矩阵。
阿里云的消息中间件具备较强的技术优势和核心竞争力,体现在很高的 SLA,最高达到 4 个 9,支持异地多活/灾备、故障秒级恢复、高吞吐和低延时的能力,并且支持海量的连接、百万队列、分级存储和 Serverless 弹性能力。
这里重点分享的消息队列 Kafka,作为一款全托管的 kafka 服务包括生态相关的云产品,解决了非常多的用户痛点,是大数据生态领域中使用率非常高的产品,其主打的价值是内核更加的稳定、成本更加的低廉,同时具备更高的性能。
企业级大数据消息通道:消息系列 Kafka

消息队列 Kafka 版集成了更丰富的生态,不仅是兼容开源的生态,还对接融合了各种阿里云内部产品的生态。具体表现在:
页面交互上,我们的控制台会有非常多且直观的功能,可以让用户使用一键迁移等生态功能,通过 Connector 对接其他云服务例如 RDS。研发同学也会持续维护更新 kafka 服务版本,让用户能够使用到最新的开源对标能力,同时也会持续做好内部优化版本,不断修复各种开源的问题,让用户有更好的使用体验;
支持服务编排、阿里云内部 Tag 的资源管理能力,以及可观测的一些基本能力;
优化模块,涉及到底层的技术优化,比如分级存储,多盘的支持等;
完善的运维底座,可以做到自动化的巡检运维,支持自动化专家诊断。
自研双引擎支持

本节将简单介绍一些消息队列 Kafka 的技术优化。消息队列 Kafka 同时支持阿里云自研的存储引擎和开源存储引擎,可以解决用户的痛点,如:开源劣势、兼容性担忧、支持 Topic 粒度使用不同的存储引擎。
开源自建 Kafka 很难解决的一些问题可以通过我们的云 Topic 引擎去支持。云 Topic 引擎的优势包括更好的可用性、弹性和更低的成本;研发同学通过优化引擎解决开源的生存 Bug,还可以全面兼容开源的不同版本,包括 0.10 版本、2.2 版本、2.6 版本等;以及支持不同引擎 Topic 混用,引擎设置粒度细化到 Topic 级别。
刷盘机制优化

其次是刷盘机制的优化,对于开源 Kafka 来说,他的 ISR 机制支持多副本的能力。但是这个能力需要在不同的 Broker 节点上去复制和拷贝数据,要占用相当的一部分网络流量。消息队列 Kafka 版内部做了一些优化,包括和底层的阿里云盘,盘古文件系统这些做了深度的整合优化,把这个多副本的能力直接做到底层,这样可以优化阿里 Kafka 的刷盘效率,降低磁盘使用和成本,并且提升了性能,同时扩容稳定性也得到了保障,数据可靠性可以达到 8 个 9。
分级存储

还有一项比较重要的技术优化是分级存储。消息队列 Kafka 通过结合底层 NAS 等存储服务,使用分级存储降低成本,同时提供海量存储容量的能力,允许用户自定义时长的消息保存能力,大大延长了消息保留时间,支持保存长达数月的时间。同时,支持冷热数据分离,保证新的消息读写性能不受到影响。
巡检组件

提到自动化运维,必然少不了巡检组件。巡检组件保证了整个服务的稳定性。巡检系统会及时地检查所有集群有没有潜在的问题和故障,然后快速进行自我恢复。自我恢复一般是个秒级响应切换的过程,能够保证整个集群在运行中保持稳定,对用户来说,是保障高 SLA 的基础。
容灭方案

消息队列 Kafka 也具备完善的容灾方案,包括如果用户购买了专业版,部署的时候可以选择不同的可用区,对应不同的机房。当其中的一个机房出现故障,容灭方案会自动将这个服务熔断并摘除,将服务的流量切换到其他可用区,这样就可以达到全集群的自动切换,且切换时间很短,同时保证消息不会丢失。解决了开源可用性和可靠性的矛盾问题。
Connector 组件:支持配置化转储到大数据相关产品

本节介绍消息队列 Kafka 的生态支持,说到生态,就不得不提到 Kafka Connector 组件。消息队列 Kafka Connector 支持配置化地设置转储任务将 Kafka 数据连通到其他大数据相关云产品。
用户只需要简单地配置后,就可以将上游的数据,比如说从 MySQL、Logstash 进来的数据,经过 Kafka 然后通过 Kafka 的 Connector 组件运维调度 Connector 运行时任务,自动地对接到下游,比如 OSS、FunctionComputer、Flink 、Hbase 等这些下游的计算,或者是存储分析的服务,可以自动地做到免运维的全托管的数据对接。还支持包括像 ETL 轻量化数据清洗转储,都有非常成熟的行业解决方案。
ETL 组件:轻量化消息流处理

关于 ETL 服务组件,它是轻量级消息流处理系统,可以通过接收上游采集的客户业务数据,例如生产数据、数据库的数据、物联网设备的 IoT 时序数据,进入到 Kafka,通过 Kafka 的 ETL 功能,用户可以自定义数据处理的函数,通过配置化的方式填写到 ETL 页面中。函数会自动的对某一些 Topic 的数据进行清洗和数据的流转,将这些数据通过这个加工模板/算子传到下游的目标数据源,例如 RDS、OSS、Maxcompute 这些下游的服务,自动实现数据的清理、清洗、流转的功能。
发送最佳实践

本节介绍 Kafka 客户端的一些最佳实践。首先关于 Producer 这里,有经验上的比较普适的一些建议,如配置的参数优化、配置的计算选取。建议非业务需要不要使用 Key,因为如果使用 Key 的话,有可能因为 Key 的分布不均导致一些分区写入热点问题,因为 Key 决定了消息写入到哪一个分区,为了减少碎片化写入,更好地负载均衡,建议可以使用粘性的分区策略,以及分区数使用控制台创建 Topic 时推荐的值。
消费最佳实践

关于消费者的最佳实践,通过文档建议的参数调优方法,可以尽量减少发生 Rebalance 的可能,提高消费能力。具体的典型应用场景,像消息中间件发布订阅消息,这是它的基础能力。在跟踪网站的应用场景中,可以做到发布到特定的 Topic 和订阅 Topic,做到数据实时的处理和监控。像数据监控、日志转储、聚合日志提交,这些都可以基于现有的开源组件来实现,例如使用 File beat 开源组件,都可以直接做到基于 Kafka、开源组件这一套的能力去快速地实现日志采集分析。
典型场景


Kafka 也可以应用到反作弊的实时分析场景中,可以通过 Kafka 作为消息的中间流转组件,由上游的 FileBeat 和 LogStash 采集游戏服务的日志。把消息路由到 Flink 实时去做计算,然后把这个计算后的数据存储到 ES 或者 Click house。把 Kafka 的数据流转到一些下游的风控服务,最后反过来形成闭环,对游戏服务的反作弊分析进行处理。
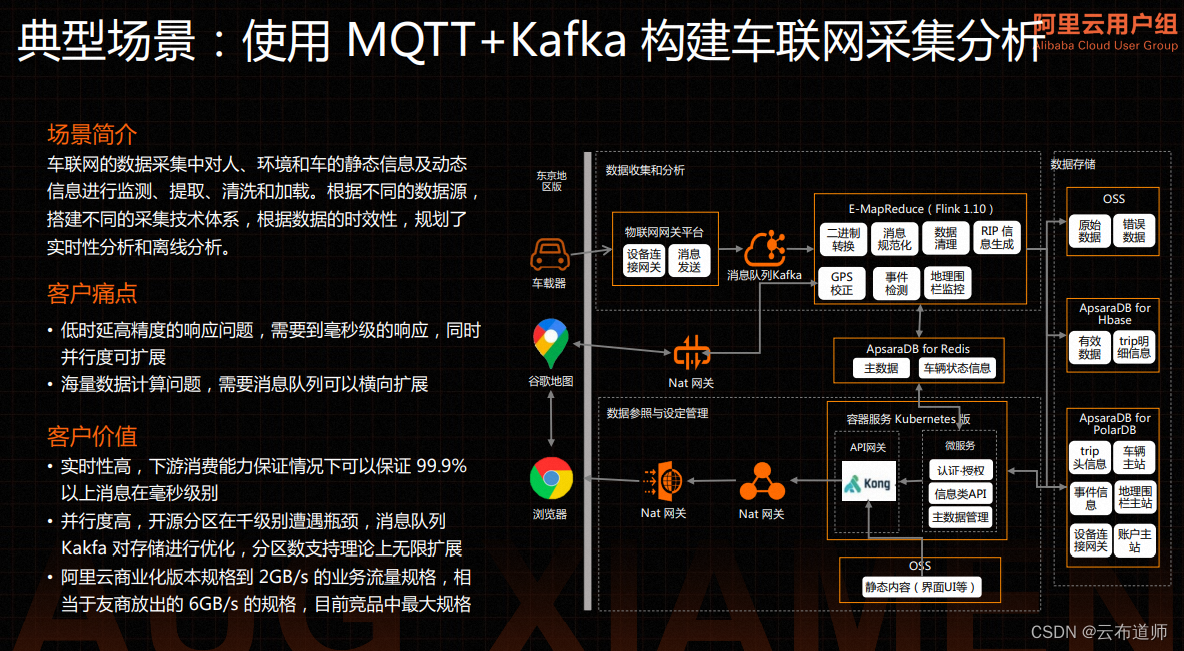
MQTT 和 Kafka 一起构建的车联网,也是有一套比较成熟的体系,可以通过 Kafka 作为消息中转的总线,把不同的 IoT 数据流转到下游的各种服务。
从上述应用场景中我们可以看到,在 Serverless 趋势下的现代化软件架构体系中,消息队列 Kafka,包括其他的消息产品,在云服务 Serverless 化的过程中成为了非常重要的一环。也希望大家在将来的 Serverless 实践中多体验和使用消息中间件 Kafka 云产品,为我们提出宝贵建议。(正文完)
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我是rails的新手,想在form字段上应用验证。myviewsnew.html.erb.....模拟.rbclassSimulation{:in=>1..25,:message=>'Therowmustbebetween1and25'}end模拟Controller.rbclassSimulationsController我想检查模型类中row字段的整数范围,如果不在范围内则返回错误信息。我可以检查上面代码的范围,但无法返回错误消息提前致谢 最佳答案 关键是您使用的是模型表单,一种显示ActiveRecord模型实例属性的表单。c
我的工作要求我为某些测试自动生成电子邮件。我一直在四处寻找,但未能找到可以快速实现的合理解决方案。它需要在outlook而不是其他邮件服务器中,因为我们有一些奇怪的身份验证规则,我们需要保存草稿而不是仅仅发送邮件的选项。显然win32ole可以做到这一点,但我找不到任何相当简单的例子。 最佳答案 假设存储了Outlook凭据并且您设置为自动登录到Outlook,WIN32OLE可以很好地完成此操作:require'win32ole'outlook=WIN32OLE.new('Outlook.Application')message=
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我正在使用Ruby,我正在与一个网络端点通信,该端点在发送消息本身之前需要格式化“header”。header中的第一个字段必须是消息长度,它被定义为网络字节顺序中的2二进制字节消息长度。比如我的消息长度是1024。如何将1024表示为二进制双字节? 最佳答案 Ruby(以及Perl和Python等)中字节整理的标准工具是pack和unpack。ruby的packisinArray.您的长度应该是两个字节长,并且按网络字节顺序排列,这听起来像是n格式说明符的工作:n|Integer|16-bitunsigned,network(bi
如果我在模型中设置验证消息validates:name,:presence=>{:message=>'Thenamecantbeblank.'}我如何让该消息显示在闪光警报中,这是我迄今为止尝试过的方法defcreate@message=Message.new(params[:message])if@message.valid?ContactMailer.send_mail(@message).deliverredirect_to(root_path,:notice=>"Thanksforyourmessage,Iwillbeintouchsoon")elseflash[:error]
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
RSpec似乎按顺序匹配方法接收的消息。我不确定如何使以下代码工作:allow(a).toreceive(:f)expect(a).toreceive(:f).with(2)a.f(1)a.f(2)a.f(3)我问的原因是a.f的一些调用是由我的代码的上层控制的,所以我不能对这些方法调用添加期望。 最佳答案 RSpecspy是测试这种情况的一种方式。要监视一个方法,用allowstub,除了方法名称之外没有任何约束,调用该方法,然后expect确切的方法调用。例如:allow(a).toreceive(:f)a.f(2)a.f(1)