阻塞队列--BlockingQueue,它是一个接口,
public interface BlockingQueue<E> extends Queue<E>
BlcokingQueue继承了Queue接口,是队列的一种,Queue和BlockingQueue都是在Java5中加入的,BlockingQueue是线程安全的,我们在很多场景下都可以利用线程安全的队列来优雅地解决我们业务自身的线程安全问题。
主要并发队列关系图
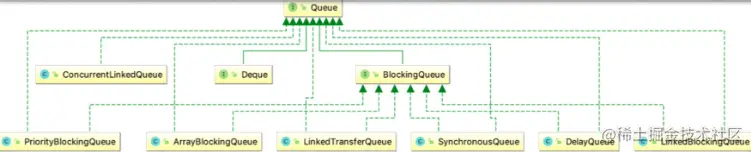
上图展示了Queue最主要的实现类,可以看出Java提供的线程安全的队列(也成为并发队列)主要分为阻塞队列和非阻塞队列俩大类。
阻塞队列的特点就是阻塞两个字,哈哈哈哈。像是废话。阻塞功能使得生产者和消费者两端的能力得以平衡,当有任何一端速度过快时,阻塞队列便会把过快的速度降下来。最重要的两个方法:take()和put();
take()
take方法的功能是获取并移除队列的头节点,通常在队列里有数据的时候是可以正常移除的,当队列里无数据,则阻塞,直到队列里面有数据。一旦有数据了,就立刻解除阻塞状态,并且获取到数据 put()
put方法插入元素时,如果队列没有满可以正常插入,如果队列满了,则阻塞,直到队列里面有了空闲空间,就会消除阻塞状态,并把数据添加进去。
阻塞队列容量问题
阻塞队列分为两种有界和无界。无界队列意味着里面可以容纳非常多的元素,例如LinkedBlcokingQueue的上限是Integer.MAX_VALUE。学过Java的人都知道这个数其实挺大的。但有界队列例如ArrayBlockingQueue如果队列满了,也不会扩容。
在阻塞队列中有很多方法,而且都非常相似,这里我把常用的8个方法总结了一下以添加、删除为主。主要分为三类:
add方法是往队列里面添加一个元素,如果队列满了,就会抛出异常来提示我们队列已满。
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue=new ArrayBlockingQueue<>(2);
blockingQueue.add(1);
blockingQueue.add(1);
blockingQueue.add(1);
}
这里我们指定队列容量为2,并且尝试加入3个值。超过了容量上限就会报IllegalStateException的错误。

remove方法是删除元素,如果我们队列为空的时候又进行了删除操作,同样会报NoSuchElementException。
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue=new ArrayBlockingQueue<>(2);
blockingQueue.add(1);
blockingQueue.add(1);
blockingQueue.remove();
blockingQueue.remove();
blockingQueue.remove();
}
这里我们指定容量为2,并且添加两个元素,然后删除三个元素。结果如下

element方法是返回队列的头节点,但是不会删除这个元素。当队列为空时同样会报NoSuchElementException的错误
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue=new ArrayBlockingQueue<>(2);
blockingQueue.element();
}

offer方法用来插入一个元素,如果插入成功会返回true,如果队列满了,再插入元素不会抛出异常但是会返回false。
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue=new ArrayBlockingQueue<>(2);
System.out.println(blockingQueue.offer(1));
System.out.println(blockingQueue.offer(1));
System.out.println(blockingQueue.offer(1));
}

poll方法和remove方法是对应的都是删除元素,都会返回删除的元素,但是当队列为空时则会返回null
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<>(2);
blockingQueue.offer(1);
blockingQueue.offer(1);
System.out.println(blockingQueue.poll());
System.out.println(blockingQueue.poll());
System.out.println(blockingQueue.poll());
}

peek方法和element方法对应,返回队列的头节点但并不删除,如果队列为空则直接返回null
public static void main(String[] args) {
BlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<>(2);
System.out.println(blockingQueue.peek());
}

带超时时间的offer和poll
offer(E e, long timeout, TimeUnit unit)
它有三个参数,分别是元素、超时时长和时间单位。通常情况下,这个方法会插入成功并且返回true;如果队列满了导致插入不成功,在调用带超时时间重载方法的offer的时候,则会等待指定的超时时间,如果到了时间依然没有插入成功,则返回false。
E poll(long timeout, TimeUnit unit)
这个带参数的poll和上面的offer类似。如果能够移除,便会立即返回这个节点的内容;如果超过了我们定义的超时时间依然没有元素可以移除,便会返回null作为提示。
put方法的作用是插入元素,通常在队列没有满的时候是正常插入。如果队列满了无法继续插入,这时它不会立刻返回false和抛出异常,而是让插入的线程进入阻塞状态,直到队列里面有空闲空间了。此时队列就会让之前的线程接触阻塞状态,并把刚才那个元素添加进去。 take方法的作用是获取并移除队列的头节点。通常队列里面有元素会正常取出数据并移除;但是如果执行take的时候队列里无数据,则阻塞,直到队列里面有数据以后,就会立即解除阻塞状态,并且取到数据。 搞了个总结可以看一下

ArrayBlockingQueue是最典型的有界队列,其内部是用数组存储元素的,利用Reentrant实现线程安全
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
我们在创建它的时候就需要指定它的容量,之后也不可以在扩容了,在构造函数中我们同样可以指定是否是公平的。如果ArrayBlockingQueue被设置为非公平的,那么就存在插队的可能;如果设置为公平的,那么等待了最长时间的线程会优先被处理,其它线程不允许插队。
LinkedBlockingQueue内部使用链表实现的,如果我们不指定它的初始容量,那么它的默认容量就为整形的最大值Integer.MAX_VALUE,由于这个数特别特别的大,所以它也被称为无界队列。
SynchronousQueue最大的不同之处在于,它的容量不同,所以没有地方来暂存元素,导致每次取数据都要先阻塞,直到有数据放入;同理,每次放数据的时候也会阻塞,直到有消费者来取。SynchronousQueue的容量不是1而是0,因为SynchronousQueue不需要去持有元素,它做的就是直接传递。
PriorityBlockingQueue是一个支持优先级的无界阻塞队列,可以通过自定义类实现compareTo()方法来制定元素排序规则,或者初始化时通过构造器参数Comparator来制定排序规则。同时,插入队列的对象必须是可比较大小的,也就是Comparable的,否则就会抛出ClasscastException异常。
它的take方法在队列为空时会阻塞,但是正因为它是无界队列,而且会自动扩容,所以它的队列永远不会满,所以它的put()方法永远不会阻塞,添加操作始终都会成功。
Delay这个队列比较特殊,具有延迟的功能,我们可以设定在队列中的任务延迟多久之后执行。它是无界队列,但是放入的元素必须实现Delayed接口,而Delayed接口又继承了Comparable接口,所以自然就拥有了比较和排序的能力.
public interface Delayed extends Comparable<Delayed> {
/**
* Returns the remaining delay associated with this object, in the
* given time unit.
*
* @param unit the time unit
* @return the remaining delay; zero or negative values indicate
* that the delay has already elapsed
*/
long getDelay(TimeUnit unit);
}
可以看出这个Delayed接口继承自Comparable,里面需要涉嫌getDelay.这里的getDelay方法返回的是还剩下多长的延迟时间才会被执行。如果返回0或者负数则代表任务已过期。元素会根据延迟时间的长短被放到队列的不同位置,越靠近队列头代表越早过期。
先来看一下ArrayBlockingQueue的几个重要属性
//用于存放元素的数组
final Object[] items;
//下一次读取的位置
int takeIndex;
// 下一次写入的位置
int putIndex;
// 队列中元素的数量
int count;
/*
* 用于控制并发的工具类
*/
/** Main lock guarding all access */
final ReentrantLock lock;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
ArrayBlockingQueue实现并发同步的原理就是利用ReentrantLock和它的俩个Condition,读操作和写操作都需要先获取到ReentrantLock独占锁才能进行下一步操作。进行读操作时如果队列为空,线程就会进入到读线程专属的notEmpty的Condition的队列中去排队,等待写线程写入新的元素;同理队列已满,这个时候写操作的线程进入到写线程专属的notFull队列中去排队,等待读线程将队列元素移除并腾出空间。
看一下ArrayBlockingQueue的put方法。
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
在put方法中,首先用checkNotNull方法检查插入的元素是不是null,如果不是null,我们会用Reentrantlock上锁,并且使用的上锁方法是lock.lockInterruptibly()。这个方法在获取锁的同时是可以相应中断的,这也正是我们的阻塞队列调用put方法时,在尝试获取锁但还没拿到锁的期间可以响应中断的底层原因。紧接着在while循环中,它会检查当前队列是不是已经满了,也就是count的长度是否等于数组长度。如果等于代表已经满了,于是我们便会进行等待,直到有空余的时候,我们才会执行下一步操作,调用enqueue方法让元素进入队列,最后用unlock方法解锁。
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
// p is last node
if (p.casNext(null, newNode)) {
// Successful CAS is the linearization point
// for e to become an element of this queue,
// and for newNode to become "live".
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
else if (p == q)
// We have fallen off list. If tail is unchanged, it
// will also be off-list, in which case we need to
// jump to head, from which all live nodes are always
// reachable. Else the new tail is a better bet.
p = (t != (t = tail)) ? t : head;
else
// Check for tail updates after two hops.
p = (p != t && t != (t = tail)) ? t : q;
}
}
通过源码我们可以清晰的看出,非阻塞队列ConcurrentLinkedQueue它的主要流程就是在判空以后,会进入一个大循环中,p.casNext()方法,这个方法正是利用了CAS来操作的,这个死循环去配合CAS其实就是我们平时说的乐观锁的思想。其实非阻塞队列ConcurrentLickedQueue使用CAS非阻塞算法+不停重试的实际来实现线程安全的。
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
我基本上来自Java背景并且努力理解Ruby中的模运算。(5%3)(-5%3)(5%-3)(-5%-3)Java中的上述操作产生,2个-22个-2但在Ruby中,相同的表达式会产生21个-1-2.Ruby在逻辑上有多擅长这个?模块操作在Ruby中是如何实现的?如果将同一个操作定义为一个web服务,两个服务如何匹配逻辑。 最佳答案 在Java中,模运算的结果与被除数的符号相同。在Ruby中,它与除数的符号相同。remainder()在Ruby中与被除数的符号相同。您可能还想引用modulooperation.
Java的Collections.unmodifiableList和Collections.unmodifiableMap在Ruby标准API中是否有等价物? 最佳答案 使用freeze应用程序接口(interface):Preventsfurthermodificationstoobj.ARuntimeErrorwillberaisedifmodificationisattempted.Thereisnowaytounfreezeafrozenobject.SeealsoObject#frozen?.Thismethodretur