使用abaqus软件进行二次开发,往往在.rpy文件自动生成的代码基础上进行修改。
然而,在对点、线、面、体进行选择时,abaqus默认生成的代码为
cells = c.getSequenceFromMask(mask=('[#1 ]', ), )
这种形式的mask掩码,显然不利于参数化建模操作。
此时,可以通过在下图所示abaqus界面的命令行中,输入命令更改abaqus自动生成代码的索引类型:

1. 将rpy文件中的代码索引形式更改为:“实际特征索引号”
session.journalOptions.setValues(replayGeometry=INDEX,recoverGeometry=INDEX)2. 将rpy文件中的代码索引形式更改为:“findAt()函数配合点坐标”
session.journalOptions.setValues(replayGeometry=COORDINATE,recoverGeometry=COORDINATE)以下图所示纤维-基体结构对应的三种不同索引结果对三种索引类型进行说明:
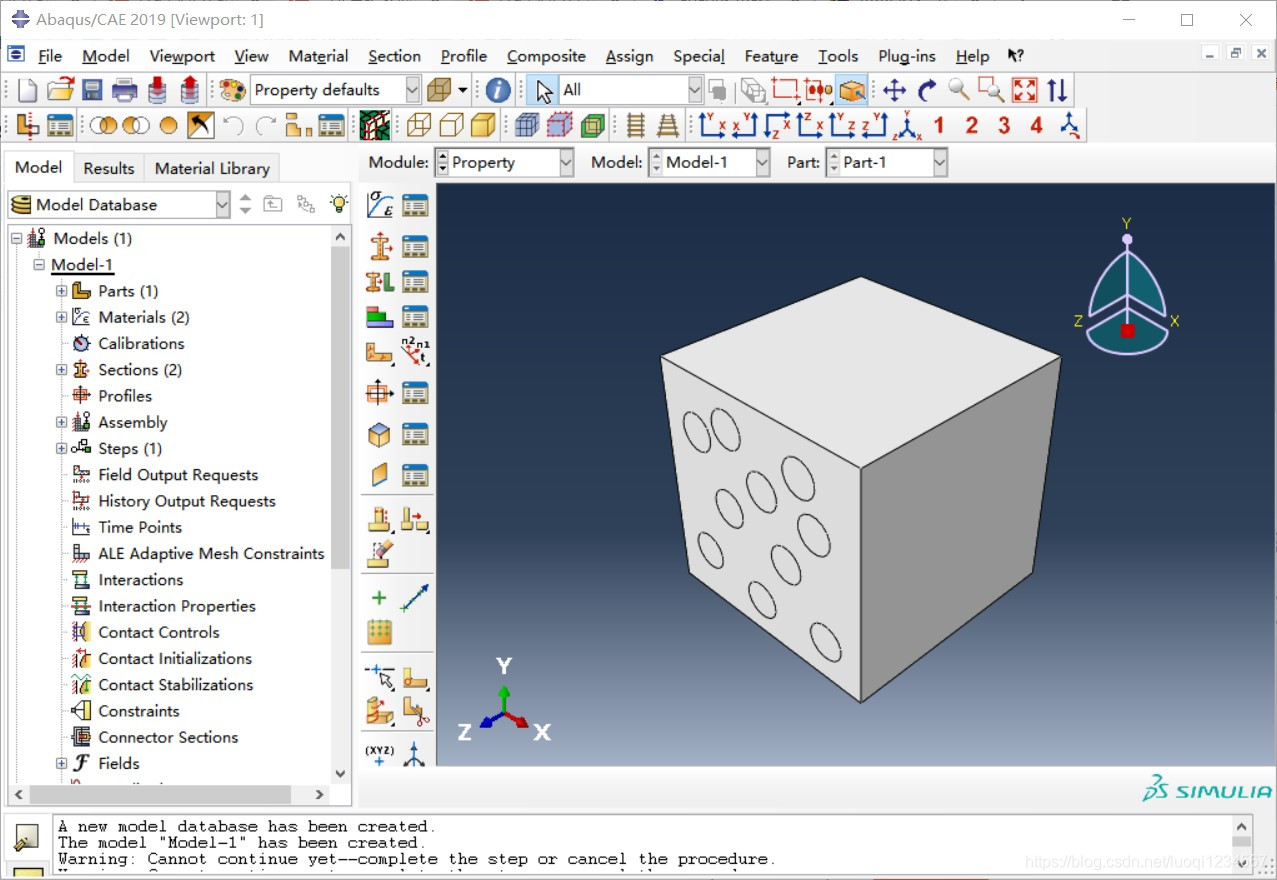
对图示结构中纤维赋予材料属性:
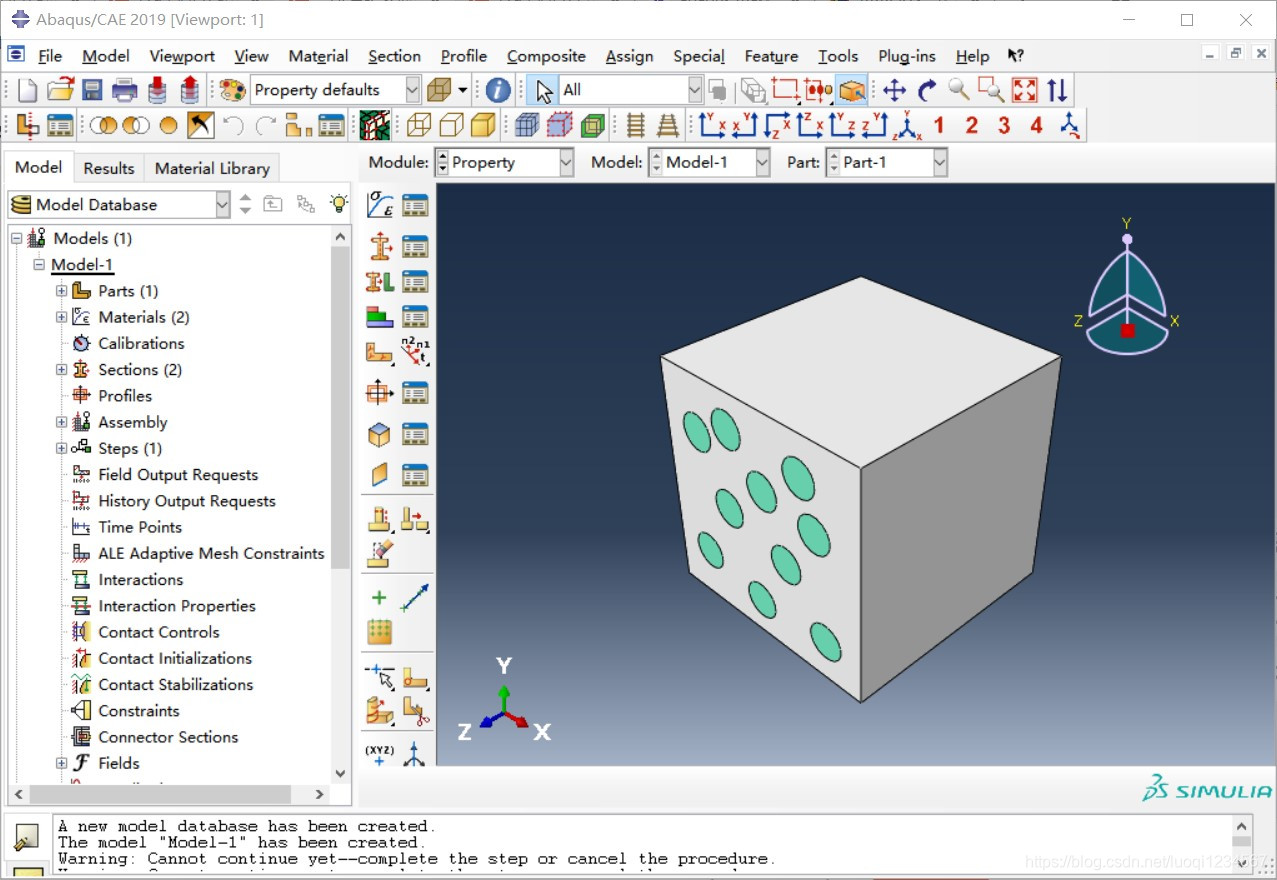
此时getSequenceFromMask生成的掩码为 [#7fe],难以从几何意义上进行编程。
p = mdb.models['Model-1'].parts['Part-1']
c = p.cells
cells = c.getSequenceFromMask(mask=('[#7fe ]', ), )
region = p.Set(cells=cells, name='Set-1')
p = mdb.models['Model-1'].parts['Part-1']
p.SectionAssignment(region=region, sectionName='Section-1', offset=0.0,
offsetType=MIDDLE_SURFACE, offsetField='',
thicknessAssignment=FROM_SECTION)转化为特征索引号后,代码如下:
p = mdb.models['Model-1'].parts['Part-1']
c = p.cells
cells = c[1:11]
region = p.Set(cells=cells, name='Set-2')
p = mdb.models['Model-1'].parts['Part-1']
p.SectionAssignment(region=region, sectionName='Section-2', offset=0.0,
offsetType=MIDDLE_SURFACE, offsetField='',
thicknessAssignment=FROM_SECTION)c[1:11] 表示结构中的十根纤维,该特征索引号与纤维和基体的生成顺序相关。显然,此时纤维基体对应的特征索引号为c[0]
转化为findAt类型后,代码如下:
p = mdb.models['Model-1'].parts['Part-1']
c = p.cells
cells = c.findAt(((18.962994, 14.585984, 0.0), ), ((48.349822, 22.238453,
100.0), ), ((64.427994, 34.070985, 0.0), ), ((82.989822, 24.403453, 100.0),
), ((18.962994, 68.710983, 0.0), ), ((35.359821, 91.518456, 100.0), ), ((
34.117994, 42.730985, 0.0), ), ((52.679821, 74.198453, 100.0), ), ((
78.659823, 69.868454, 100.0), ), ((73.087995, 75.205986, 0.0), ))
region = p.Set(cells=cells, name='Set-3')
p = mdb.models['Model-1'].parts['Part-1']
p.SectionAssignment(region=region, sectionName='Section-1', offset=0.0,
offsetType=MIDDLE_SURFACE, offsetField='',
thicknessAssignment=FROM_SECTION)findAt()内为十根纤维所对应的坐标位置,该方法适用于明确知晓结构几何分布的情况。
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我正在从erb文件切换到HAML。我将hamlgem添加到我的系统中。我创建了app/views/layouts/application.html.haml文件。我应该只删除application.html.erb文件吗?此外,仍然有/public/index.html文件被呈现为默认页面。我想创建自己的默认index.html.haml页面。我应该把它放在哪里以及如何使系统呈现该文件而不是默认索引文件?谢谢! 最佳答案 是的,您可以删除任何已转换为HAML的View的ERB版本。至于你的另一个问题,删除public/index/h