本篇总结学习 C++ 时常用的几个网站,点击会跳转到相应网页。
链接(英文):https://en.cppreference.com/
链接(中文):https://zh.cppreference.com/
链接(英文):https://learn.microsoft.com/en-us/cpp/cpp/?view=msvc-170
链接(中文):https://learn.microsoft.com/zh-cn/cpp/cpp/?view=msvc-170
链接:http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines
GitHub链接:https://github.com/isocpp/CppCoreGuidelines
简述:两位 C++ 大佬 Bjarne Stroustrup 和 Herb Stutter 写的 C++ 编程指南。
链接:https://www.tutorialspoint.com/cplusplus/index.htm
简述:提供了一些 C++ 基础教程。

链接:https://rosettacode.org/wiki/Rosetta_Code
简述:用不同的编程语言编写经典算法,供大家对比不同语言的相同点和差异性。
链接:https://people.sc.fsu.edu/~jburkardt/cpp_src/cpp_src.html
简述:一些开源的 C++ 代码,涉及数值计算、数字信号处理、概率统计等多个方面。
简述:世界上最大的代码托管平台。
简述:国内最大的代码托管平台。
链接:https://doc.qt.io/qt-5/classes.html
简述:标准委员会官方站点,里面有许多 C++ 常见问题的解答,还有很多 C++ 编程手法上的奇技淫巧。
简述:全球最大的技术问答网站,很多问题往往在这里都能找到解决方案。

简述:知乎虽然不是一个专门做技术问答的社区,但某些编程技术问题在上面也是可以找到答案的。
简述:国内的开源技术社区,包含代码托管、问答、博客等多个模块内容。
GitHub链接:https://github.com/compiler-explorer/compiler-explorer/
简述:一个交互式的编译浏览网站,支持多种编程语言,可实时浏览编译后的汇编代码。
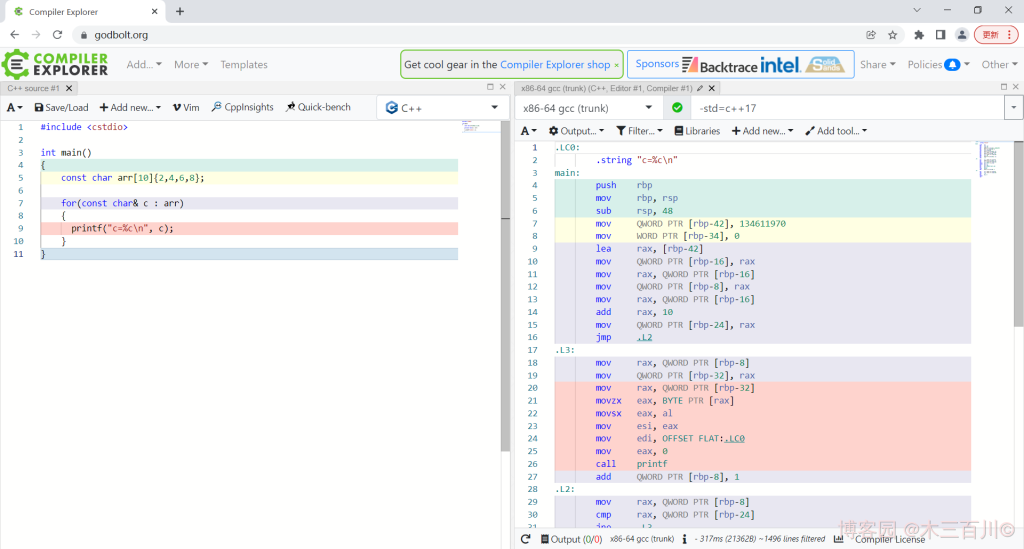
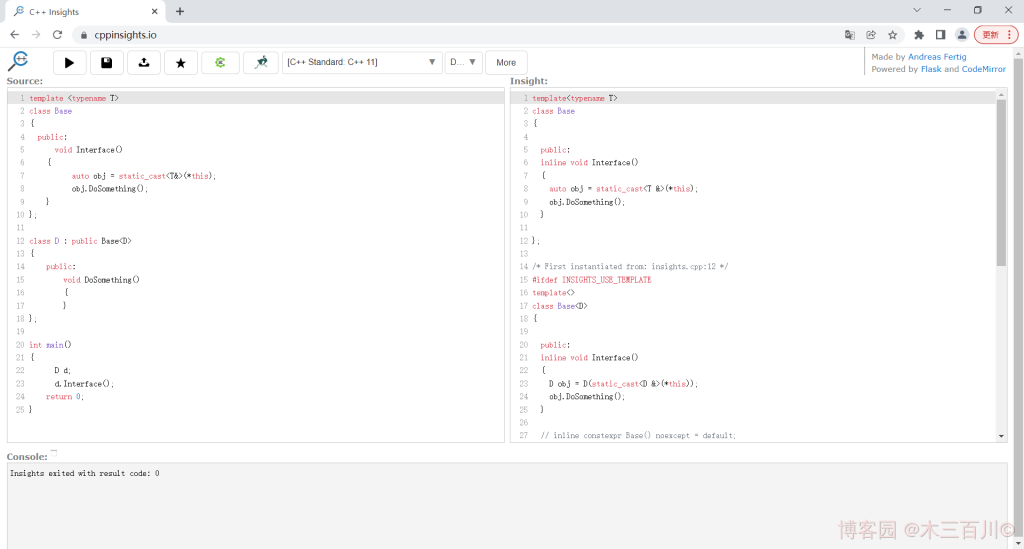
GitHub链接:https://github.com/andreasfertig/cppinsights
简述:用编译器的眼光看源代码,可以查看代码被编译展开后的具体情况,是个学习 C++ 模板时不错的辅助工具。
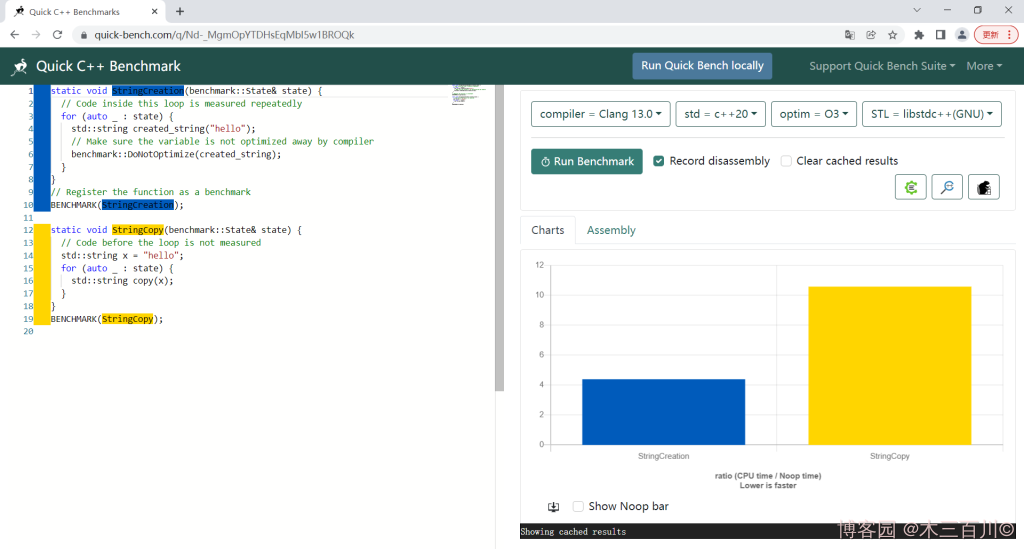
GitHub链接(前端):https://github.com/FredTingaud/quick-bench-front-end
GitHub链接(后端):https://github.com/FredTingaud/quick-bench-back-end
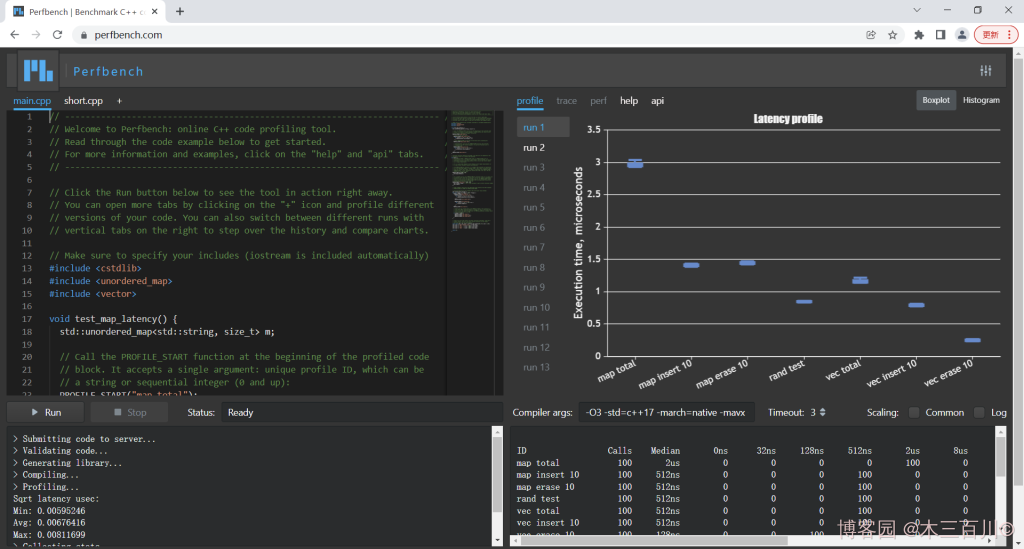
简述:一个在线的 C++ 性能测试工具,背后用的是 google benchmark 开源库。
GitHub链接(前端):https://github.com/FredTingaud/quick-bench-front-end
GitHub链接(后端):https://github.com/FredTingaud/quick-bench-back-end
简述:在线测试 C++ 代码的编译开销,可配合 Quick C++ Benchmark 使用,它的 GitHub 地址和 Quick C++ Benchmark 一样。
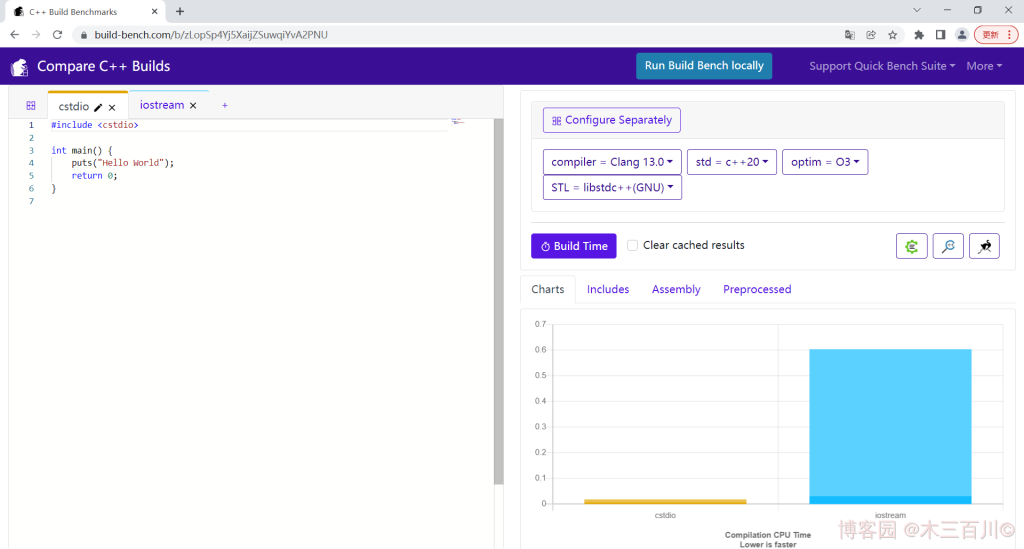
简述:一个在线的 C++ 性能测试工具,可用于比较不同算法的性能。
GitHub链接:https://github.com/GuiZi/wandbox
简述:一个在线编译器,支持多语言,还可以选择编译器版本,国内访问速度很慢。

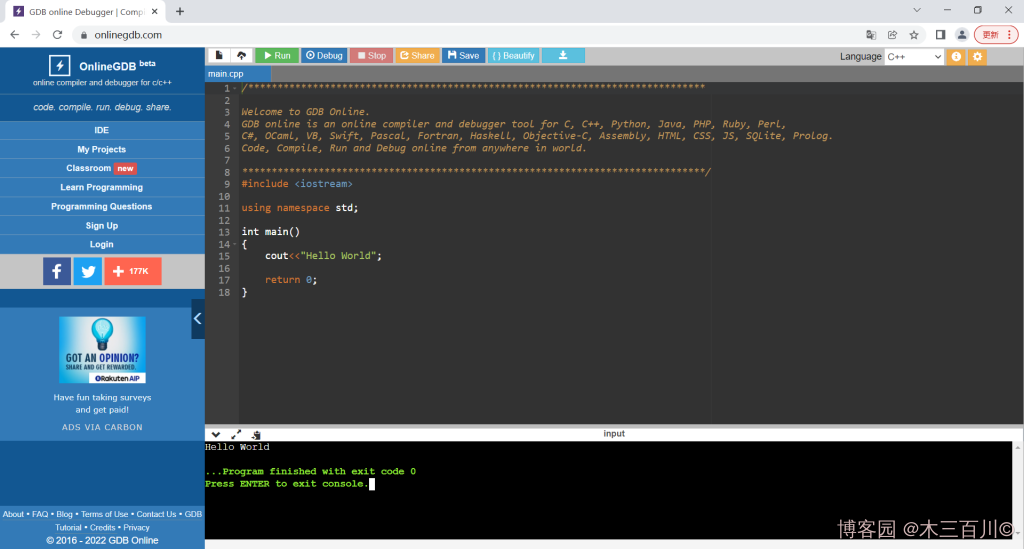
简述:一个在线编译器,支持多语言,支持在线调试。
简述:一个在线编译器,只支持 C++ 语言,可选不同的 C++ 标准及优化级别,若在最新网站中运行程序无响应,可到旧网站试试,原因未知。

链接:https://www.w3cschool.cn/webide
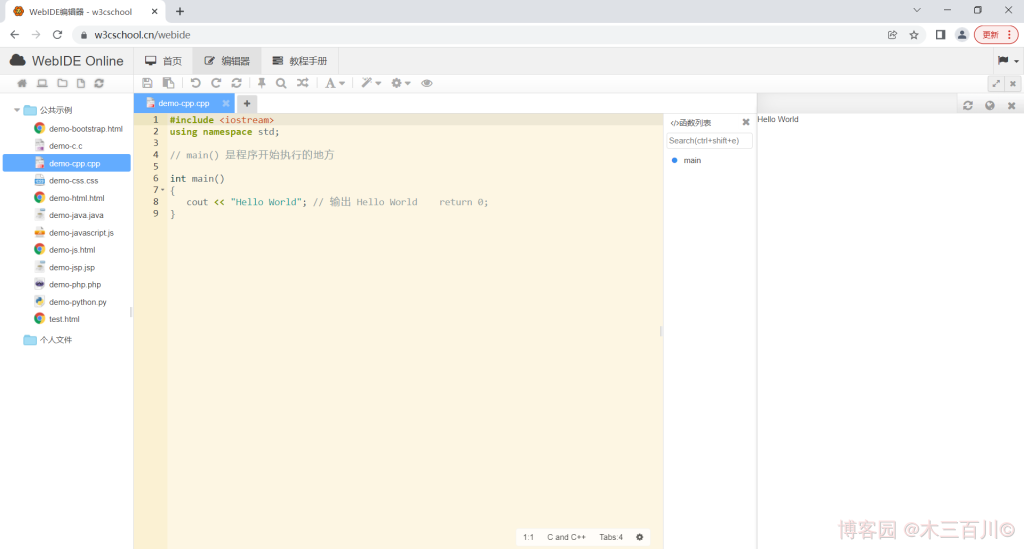
简述:一个在线编译器,支持多语言,只能单文件,不能选择编译器及优化级别,国产。
链接:https://c.runoob.com/compile/12/
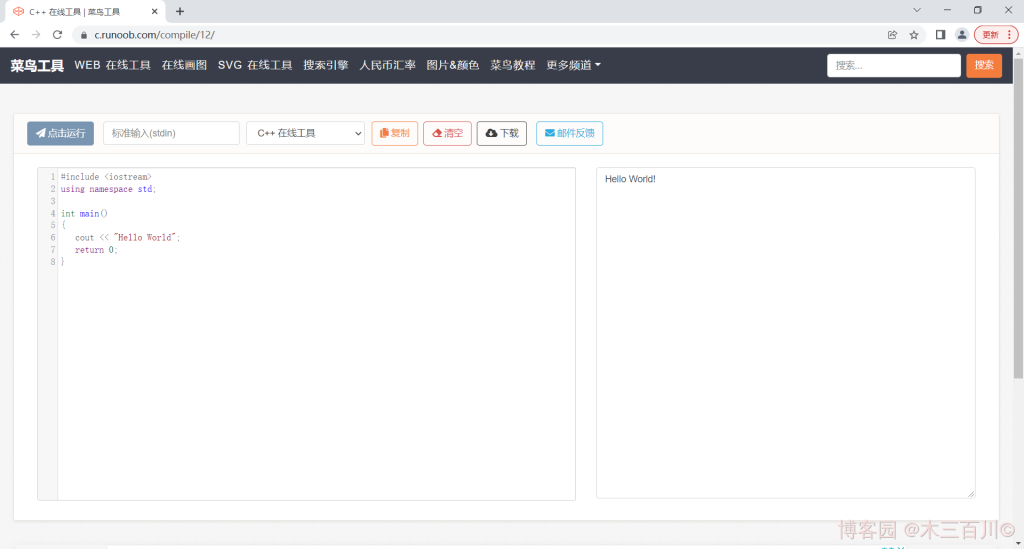
简述:一个在线编译器,支持多语言,只能单文件,不能选择编译器及优化级别,国产。
链接:https://www.tutorialspoint.com/codingground.htm
简述:一个在线编译器,支持多语言,不能选择编译器及优化级别。
链接:https://ide.geeksforgeeks.org/
简述:一个在线编译器,支持多语言,不能选择编译器及优化级别,广告很多。

链接:https://rextester.com/l/cpp_online_compiler_gcc
简述:一个在线编译器,支持多语言,能选择编译器,但不能选择优化级别。

简述:一个在线编译器,支持多语言,不能选择编译器及优化级别。

链接:https://www.jdoodle.com/online-compiler-c++/
简述:一个在线编译器,支持多语言,能选择编译器,但不能选择优化级别。

简述:一个在线编译器,支持多语言,不能选择编译器及优化级别。

国内有多个技术博客平台,但博客质量良莠不齐,需有一定的自我辨别能力,这些博客平台上的好文章也能答疑解惑。
链接:https://stroustrup.com/index.html
简述:C++ 之父 Bjarne Stroustrup 的主页。
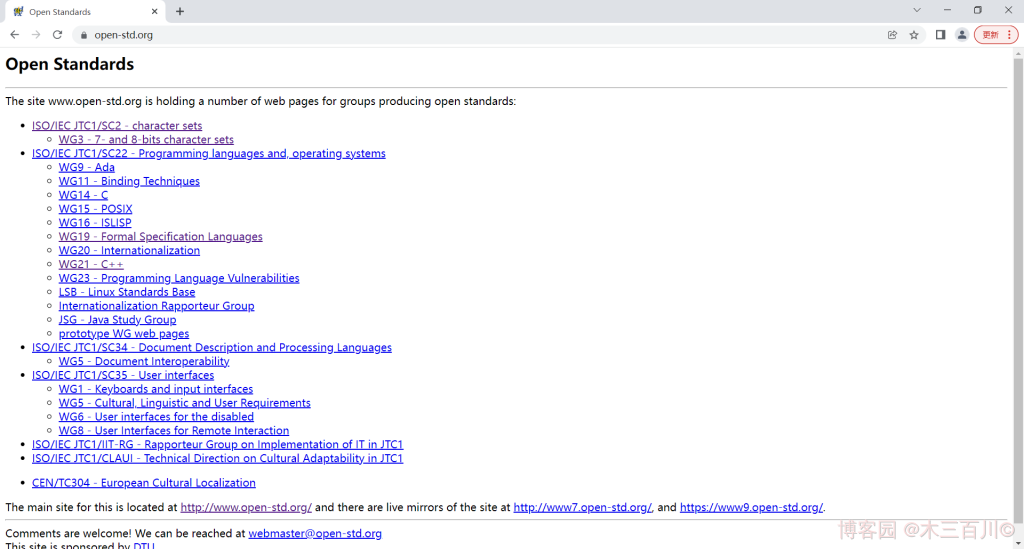
简述:公开由国际标准化组织 ISO 和国际电工委员会 IEC 组成的联合技术委员会 JTC1 发布的信息技术相关标准提案历史,内容涉及编码字符集、编程语言、操作系统、用户界面等。在其中可以找到 C++ 标准发展过程中的最新以及历史草案,最终确定下来的正式标准文件不是免费的,但这些历史草案与标准文件非常接近,可以满足大多数用途。
在Ruby中可以使用哪些替代方法来ping一个ip地址?标准库“ping”库的功能似乎非常有限。我对在这里滚动我自己的代码不感兴趣。有没有好的gem?我应该接受它并忍受它吗?(我在Linux上使用Ruby1.8.6编写代码) 最佳答案 net-ping值得一看。它允许TCPping(如标准rubyping),但也允许UDP、HTTP和ICMPping。ICMPping需要root权限,但其他则不需要。 关于ruby-Pingruby网站?,我们在StackOverflow上找到一个类
我需要从站点抓取数据,但它需要我先登录。我一直在使用hpricot成功地抓取其他网站,但我是使用mechanize的新手,我真的对如何使用它感到困惑。我看到这个例子经常被引用:require'rubygems'require'mechanize'a=Mechanize.newa.get('http://rubyforge.org/')do|page|#Clicktheloginlinklogin_page=a.click(page.link_with(:text=>/LogIn/))#Submittheloginformmy_page=login_page.form_with(:act
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
安全产品安全网关类防火墙Firewall防火墙防火墙主要用于边界安全防护的权限控制和安全域的划分。防火墙•信息安全的防护系统,依照特定的规则,允许或是限制传输的数据通过。防火墙是一个由软件和硬件设备组合而成,在内外网之间、专网与公网之间的界面上构成的保护屏障。下一代防火墙•下一代防火墙,NextGenerationFirewall,简称NGFirewall,是一款可以全面应对应用层威胁的高性能防火墙,提供网络层应用层一体化安全防护。生产厂家•联想网御、CheckPoint、深信服、网康、天融信、华为、H3C等防火墙部署部署于内、外网编辑额,用于权限访问控制和安全域划分。UTM统一威胁管理(Un
如何使用rubyonrails获取网络上某处其他网站的页面数据? 最佳答案 您可以使用httparty只是获取数据示例代码(来自example):requireFile.join(dir,'httparty')require'pp'classGoogleincludeHTTPartyformat:htmlend#google.comredirectstowww.google.comsothisislivetestforredirectionppGoogle.get('http://google.com')puts'','*'*7
我正在使用RubyonRailsv3.0.9,我想检索我设置了链接的每个网站的favicon.ico图像。也就是说,如果在我的应用程序中我设置了http://www.facebook.com/URL,我想检索Facebook的图标并在我的网页中使用\插入它。当然,我也想为所有其他网站这样做。如何以“自动”方式从网站检索favicon.ico图标(“自动”是指在网站中搜索图标并获取它的链接-我认为不是,因为并非所有网站都有一个名为“favicon.ico”的图标。我想以“自动”方式识别它)?P.S.:我想做的是像Facebook在您的Facebook页面中添加链接\URL时所做的那样:它
我正在尝试从googleAPI下载client_secret.json。我正在执行https://developers.google.com/gmail/api/quickstart/ruby中列出的步骤.使用此向导在GoogleDevelopersConsole中创建或选择项目并自动启用API。在左侧边栏中,选择同意屏幕。选择电子邮件地址并输入产品名称(如果尚未设置),然后单击“保存”按钮。在左侧边栏中,选择凭据并点击创建新客户端ID。选择应用程序类型已安装应用程序,已安装应用程序类型为其他,然后单击“创建客户端ID”按钮。点击新客户端ID下的下载JSON按钮。将此文件移动到您的工作
🎉精彩专栏推荐💭文末获取联系✍️作者简介:一个热爱把逻辑思维转变为代码的技术博主💂作者主页:【主页——🚀获取更多优质源码】🎓web前端期末大作业:【📚毕设项目精品实战案例(1000套)】🧡程序员有趣的告白方式:【💌HTML七夕情人节表白网页制作(110套)】🌎超炫酷的Echarts大屏可视化源码:【🔰Echarts大屏展示大数据平台可视化(150套)】🔖HTML+CSS+JS实例代码:【🗂️5000套HTML+CSS+JS实例代码(炫酷代码)继续更新中…】🎁免费且实用的WEB前端学习指南:【📂web前端零基础到高级学习视频教程120G干货分享】🥇关于作者:💬历任研发工程师,技术组长,教学总监;
2022年10月21日星期五【数据指标】加密货币总市值:$0.95万亿BTC市值占比:38.51%恐慌贪婪指数:23极度恐慌 【今日快讯】1、【政讯】1.1.1、美联储布拉德:市场预期美联储11月会加息75个基点1.1.2、美联储哈克:将维持加息一段时间1.2、美国10年期国债收益率触及4.197%,为2008年6月以来最高1.3、法国数字转型部长:政府将专注于DeFi和Web31.4、巴西ATM机将于11月3日起支持USDT1.5、美众议院副议长将于11月初加入a16zCrypto担任政府事务主管1.6、香港数字资产托管机构FirstDigitalTrust首席执行官:香港仍是安全
我注意到当我使用Mechanize获取没有响应的站点时,它只是继续等待。我该如何克服这个问题? 最佳答案 有几种方法可以处理它。Open-Uri和Net::HTTP有传递超时值的方法,然后告诉底层网络堆栈您愿意等待多长时间。例如,Mechanize允许您在初始化实例时获取其设置,例如:mech=Mechanize.new{|agent|agent.open_timeout=5agent.read_timeout=5}所有这些都在new的文档中,但您必须查看源代码才能了解您可以获得哪些实例变量。或者你可以使用Ruby的timeout模