MyBatis执行流程:
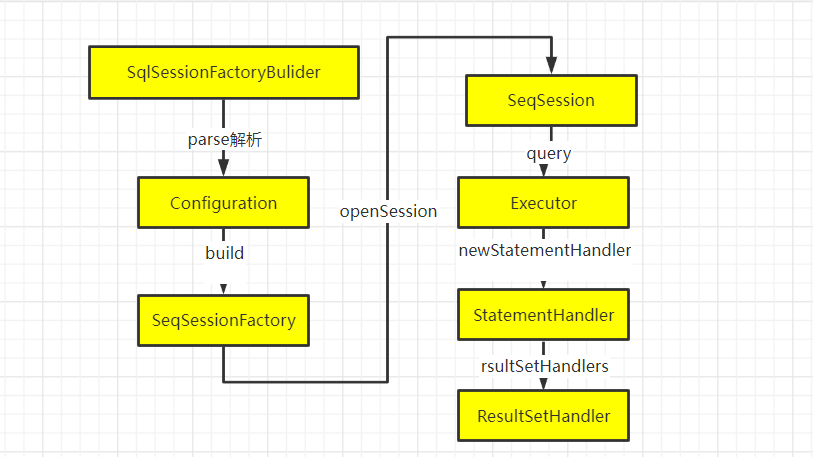
Executor 是 MyBatis 的核心接口之一,其中定义了数据库操作的基本方法。在实际应用中经常涉及的 SqISession 接口的功能,都是基于 Executor 接口实现的。
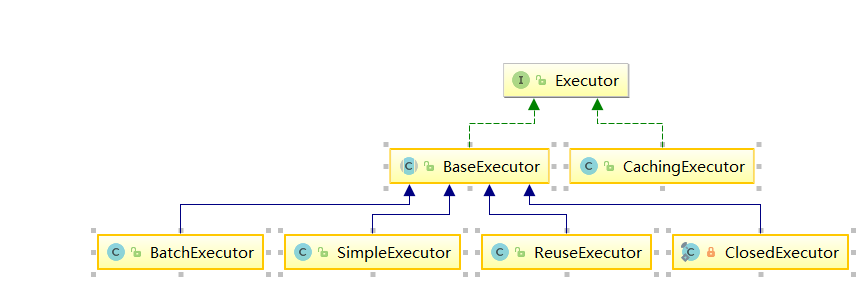
BaseExecutor 是一个实现了 Executor 接口的抽象类,它实现了 Executor 接口的大部分方法。BaseExecutor 中主要提供了缓存管理和事务管理的基本功能,继承 BaseExecutor 的子类只要实现四个基本方法来完成数据库的相关操作即可,这四个方法分别是:doUpdate()方法、doQuery()方法、doQueryCursor()方法、doFlushStatement()方法。
// 一级缓存,用于缓存该Executor对象查询结果集映射得到的结果对象
protected PerpetualCache localCache;
// 一级缓存,用于缓存输出类型的参数
protected PerpetualCache localOutputParameterCache;常见的应用系统中,数据库是比较珍贵的资源,很容易成为整个系统的瓶颈。在设计和维护系统时,会进行多方面的权衡,并且利用多种优化手段,减少对数据库的直接访问。
使用缓存是一种比较有效的优化手段,使用缓存可以减少应用系统与数据库的网络交互、减少数据库访问次数、降低数据库的负担、降低重复创建和销毁对象等一系列开销,从而提高整个系统的性能。
MyBatis 提供的缓存功能,分别为一级缓存和二级缓存。BaseExecutor 主要实现了一级缓存的相关内容。一级缓存是会话级缓存,在 MyBatis 中每创建一个 SqlSession 对象,就表示开启一次数据库会话。在一次会话中,应用程序可能会在短时间内(一个事务内),反复执行完全相同的查询语句,如果不对数据进行缓存,那么每一次查询都会执行一次数据库查询操作,而多次完全相同的、时间间隔较短的查询语句得到的结果集极有可能完全相同,这会造成数据库资源的浪费。
为了避免上述问题,MyBatis 会在 Executor 对象中建立一个简单的一级缓存,将每次查询的结果集缓存起来。在执行查询操作时,会先查询一级缓存,如果存在完全一样的查询情况,则直接从一级缓存中取出相应的结果对象并返回给用户,减少数据库访问次数,从而减小了数据库的压力。
一级缓存的生命周期与 SqlSession 相同,其实也就与 SqISession 中封装的 Executor 对象的生命周期相同。当调用 Executor 对象的 close()方法时(断开连接),该 Executor 对象对应的一级缓存就会被废弃掉。一级缓存中对象的存活时间受很多方面的影响,例如,在调用 Executor 的 update()方法时,也会先请空一级缓存。一级缓存默认是开启的,一般情况下,不需要用户进行特殊配置。
CachingExecutor 中为 Executor 对象增加了二级缓存相关功能,而 mybatis 的二级缓存在实际使用中往往利大于弊,被 redis 等产品所替代
二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession去操作数据库得到数据会存在二级缓存区域,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
二级缓存是多个SqlSession共享的,其作用域是mapper的同一个namespace,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。
Mybatis默认没有开启二级缓存需要在setting全局参数中配置开启二级缓存。
如果缓存中有数据就不用从数据库中获取,大大提高系统性能。
StatementHandler 接口是 MyBatis 的核心接口之一,它完成了 MyBatis 中最核心的工作,也是 Executor 接口实现的基础。
StatementHandler 接口中的功能很多,例如创建 Statement 对象,为 SQL 语句绑定实参,执行 select、insert、update、delete 等多种类型的 SQL 语句,批量执行 SQL 语句,将结果集映射成结果对象。
public enum StatementType {
STATEMENT, PREPARED, CALLABLE
}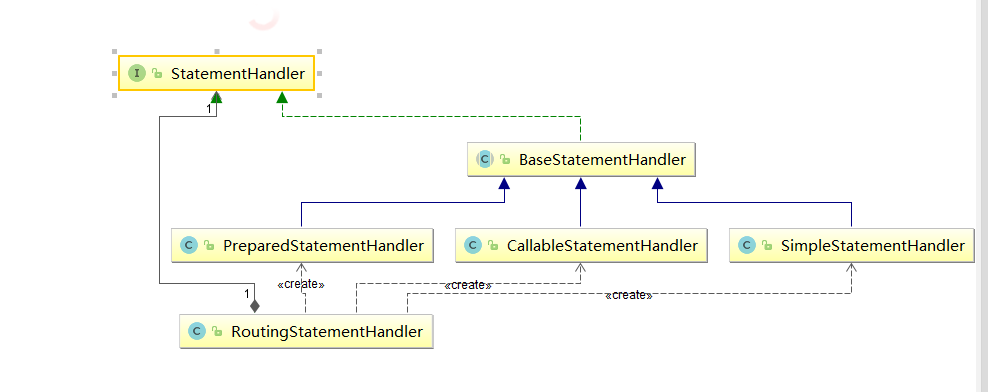
RoutingStatementHandler 使用了策略模式,RoutingStatementHandler 是策略类,而 SimpleStatementHandler、PreparedStatementHandler、CallableStatementHandler 则是实现了具体算法的实现类,RoutingStatementHandler 对象会根据 MappedStatement 对象的 StatementType 属性值选择使用相应的策略去执行。
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// RoutingStatementHandler的作用就是根据ms的配置,生成一个相对应的StatementHandler对象
// 并设置到持有的delegate属性中,本对象的所有方法都是通过调用delegate的相应方法实现的
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}BaseStaementHandler看它以 Base 开头,就可以猜到 它是一个实现了 StatementHandler 接口的抽象类,这个类只提供了一些参数绑定相关的方法,并没有实现操作数据库的方法。
BaseStatementHandler 主要实现了 StatementHandler 接口中的 prepare()方法,BaseStatementHandler 依赖两个重要的组件,ParameterHandler 和 ResultSetHandler。
DefaultParameterHandler默认实现我们要执行的 SQL 语句中可能包含占位符"?",而每个"?"都对应了 BoundSql 中 parameterMappings 集合中的一个元素,在该 ParameterMapping 对象中记录了对应的参数名称以及该参数的相关属性。ParameterHandler 接口定义了一个非常重要的方法 setParameters(),该方法主要负责调用 PreparedStatement 的 set*()系列方法,为 SQL 语句绑定实参。MyBatis 只为 ParameterHandler 接口提供了唯一一个实现类 DefaultParameterHandler。
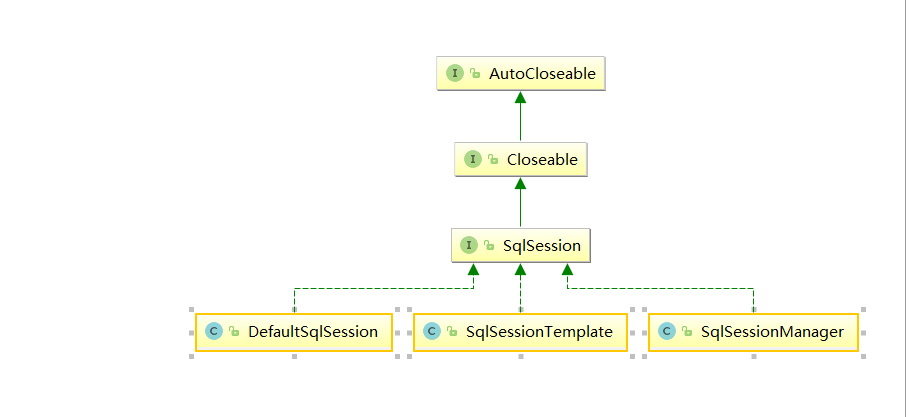
DefaultSqlSession 是单独使用 MyBatis 进行开发时,最常用的 SqISession 接口实现。其实现了 SqISession 接口中定义的方法,及各方法的重载。select()系列方法、selectOne()系列方法、selectList()系列方法、selectMap()系列方法之间的调用,殊途同归,它们最终都会调用 Executor 的 query()方法。
上述重载方法最终都是通过调用 Executor 的 query(MappedStatement, Object, RowBounds,ResultHandler)方法实现数据库查询操作的,但各自对结果对象进行了相应的调整,例如:selectOne()方法是从结果对象集合中获取了第一个元素返回;selectMap()方法会将 List 类型的结果集 转换成 Map 类型集合返回;select()方法是将结果集交由用户指定的 ResultHandler 对象处理,且没有返回值;selectList()方法则是直接返回结果对象集合。 DefaultSqlSession 的 insert()方法、update()方法、delete()方法也有多个重载,它们最后都是通过调用 DefaultSqlSession 的 update(String, Object)方法实现的,该重载首先会将 dirty 字段置为 true,然后再通过 Executor 的 update()方法完成数据库修改操作。 DefaultSqlSession 的 commit()方法、rollback()方法以及 close()方法都会调用 Executor 中相应的方法,其中就会涉及清空缓存的操作,之后就会将 dirty 字段设置为 false。 上述的 dirty 字段主要在
isCommitOrRollbackRequired()方法中,与 autoCommit 字段以及用户传入的 force 参数共同决定是否提交/回滚事务。该方法的返回值将作为 Executor 的 commit()方法和 rollback()方法的参数。
SqlSessionFactory 负责创建 SqlSession 对象,其中包含了多个 openSession()方法的重载,可以通过其参数指定事务的隔离级别、底层使用 Executor 的类型、以及是否自动提交事务等方面的配置。
DefaultSqlSessionFactory 是 SqlSessionFactory 接口的默认实现,主要提供了两种创建 DefaultSqlSession 对象的方式,一种方式是通过数据源获取数据库连接,并创建 Executor 对象以及 DefaultSqlSession 对象;另一种方式是用户提供数据库连接对象,DefaultSqlSessionFactory 根据该数据库连接对象获取 autoCommit 属性,创建 Executor 对象以及 DefaultSqlSession 对象。
SqlSessionManager 同时实现了 SqlSession 接口和 SqlSessionFactory 接口,所以同时提供了 SqlSessionFactory 创建 SqlSession 对象,以及 SqlSession 操纵数据库的功能。
SqlSessionManager 与 DefaultSqlSessionFactory 的主要不同点 SqlSessionManager 提供了两种模式,第一种模式与 DefaultSqlSessionFactory 的行为相同,同一线程每次通过 SqlSessionManager 对象访问数据库时,都会创建新的 SqlSession 对象完成数据库操作。第二种模式是 SqlSessionManager 通过 localSqlSession 这 ThreadLocal 变量,记录与当前线程绑定的 SqlSession 对象,供当前线程循环使用,从而避免在同一线程多次创建 SqlSession 对象带来的性能损失。
DataSourceFactory数据工厂
/**
* 数据源工厂
* @author Clinton Begin
*/
public interface DataSourceFactory {
/**
* 设置 dataSource 属性
* @param props
*/
void setProperties(Properties props);
/**
* 获取 dataSource
* @return {@link DataSource}
*/
DataSource getDataSource();
}
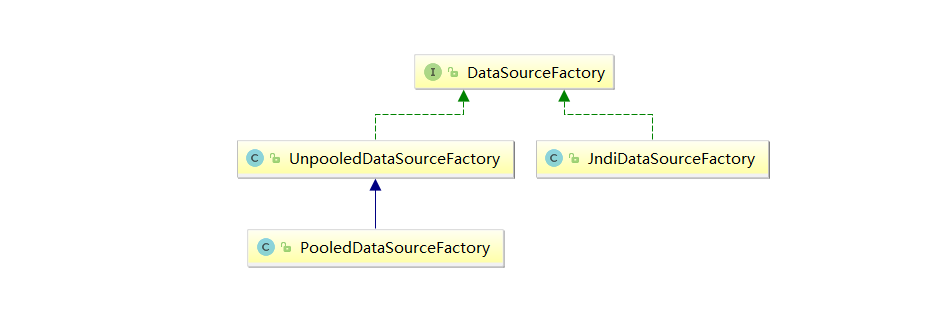
PooledDataSource 管理的数据库连接对象 是由其持有的 UnpooledDataSource 对象 创建的,并由 PoolState 管理所有连接的状态。 PooledDataSource 的 getConnection()方法 会首先调用 popConnection()方法 获取 PooledConnection 对象,然后通过 PooledConnection 的 getProxyConnection()方法 获取数据库连接的代理对象。popConnection()方法 是 PooledDataSource 的核心逻
MapperMethod 中封装了 Mapper 接口 中对应方法的信息,和对应 sql 语句 的信息,是连接 Mapper 接口 及映射配置文件中定义的 sql 语句 的桥梁。
MapperMethod 中持有两个非常重要的属性,这两个属性对应的类 都是 MapperMethod 中的静态内部类。另外,MapperMethod 在被实例化时就对这两个属性进行了初始化
MapperMethod 中的核心方法 execute() 就主要用到了这两个类
public static class SqlCommand {
// sql语句的id
private final String name;
// sql语句的类型,SqlCommandType 是枚举类型,持有常用的 增、删、改、查等操作类型
private final SqlCommandType type;
}

数据源environments解析
//XMLConfigBuilder
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">
<property name="..." value="..."/>
</transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>mybatis如何加载配置mapper的?
XMLStatmentBuilder
4种 ,优先级最高的package》resource》url>class
<!-- Using classpath relative resources -->
<mappers>
<mapper resource="org/mybatis/builder/AuthorMapper.xml"/>
<mapper resource="org/mybatis/builder/BlogMapper.xml"/>
<mapper resource="org/mybatis/builder/PostMapper.xml"/>
</mappers>
<!-- Using url fully qualified paths -->
<mappers>
<mapper url="file:///var/mappers/AuthorMapper.xml"/>
<mapper url="file:///var/mappers/BlogMapper.xml"/>
<mapper url="file:///var/mappers/PostMapper.xml"/>
</mappers>
<!-- Using mapper interface classes -->
<mappers>
<mapper class="org.mybatis.builder.AuthorMapper"/>
<mapper class="org.mybatis.builder.BlogMapper"/>
<mapper class="org.mybatis.builder.PostMapper"/>
</mappers>
<!-- Register all interfaces in a package as mappers -->
<mappers>
<package name="org.mybatis.builder"/>
</mappers>MyBatias执行器有三种
pubLic enum ExecutorType{
//简单的,复用的,批量的
SIMPLE,REUSE,BATCH
}spring启动时候需要是由一个bean.xml配置
ApplicationContext ctx = new ClassPathXmlApplicationContext("bean.xml");bean.xml配置例如:
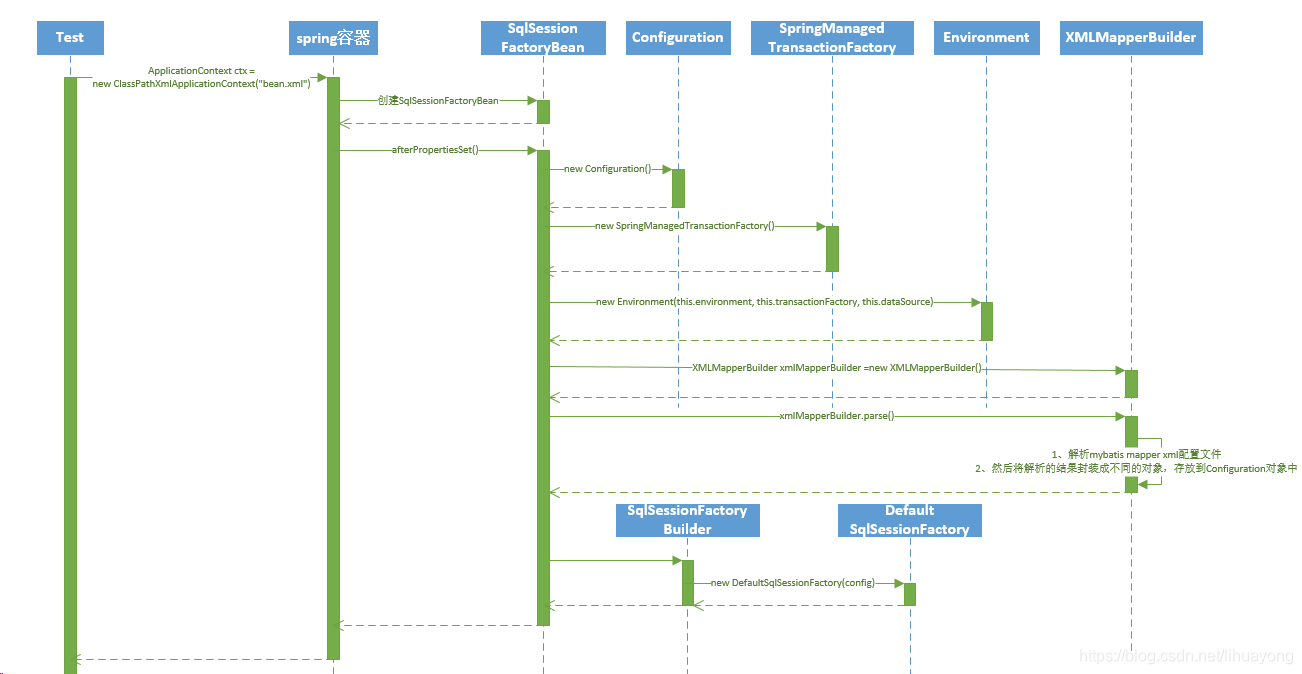
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<!-- 加载数据源 -->
<property name="dataSource" ref="dataSource"/>
<property name="mapperLocations" value="classpath*:mappers/*Mapper.xml"/>
</bean>
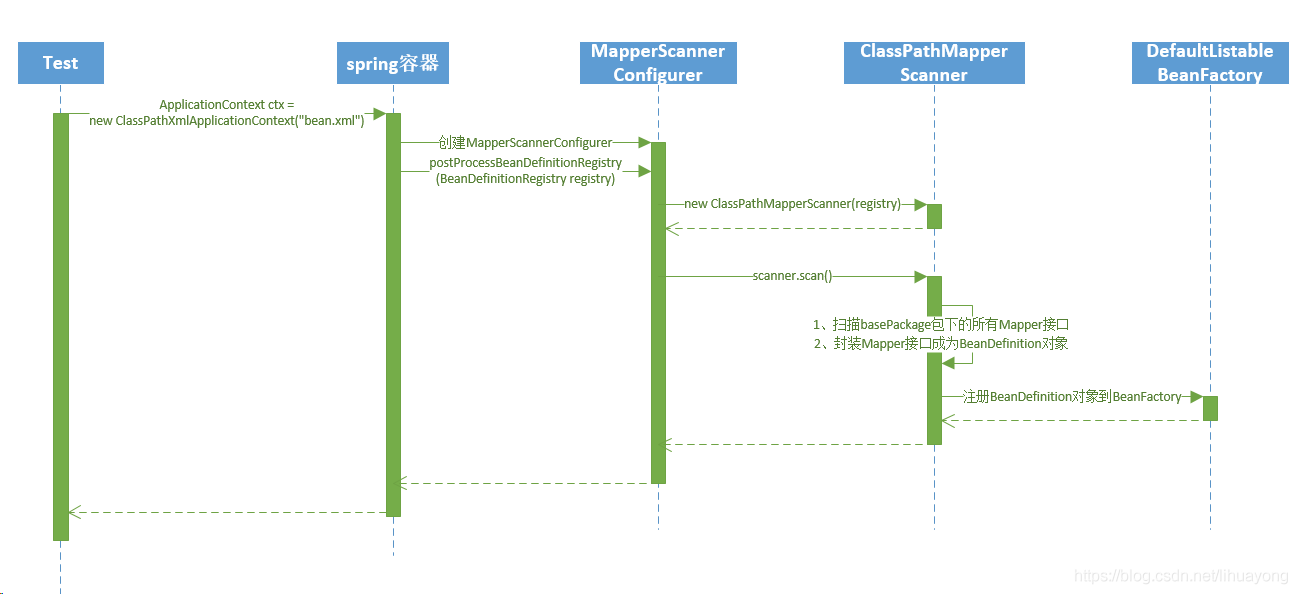
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<!-- 指定扫描的包,如果存在多个包使用(逗号,)分割 -->
<property name="basePackage" value="com.test.bean"/>
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>
</bean>这个类主要的方法就是
postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry)方法

public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
if (this.processPropertyPlaceHolders) {
processPropertyPlaceHolders();
}
//ClassPathMapperScanner扫描器,这个扫描器继承了spring的ClassPathBeanDefinitionScanner。
/**
第一扫描basePackage包下面所有的class类
第二将所有的class类封装成为spring的ScannedGenericBeanDefinition sbd对象
第三过滤sbd对象,只接受接口类
第四完成sbd对象属性的设置,比如设置sqlSessionFactory、BeanClass等,这个sqlSessionFactory是本文接下来要解析的SqlSessionFactoryBean
第五将过滤出来的sbd对象通过这个BeanDefinitionRegistry registry注册器注册到DefaultListableBeanFactory中,这个registry就是方法postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry)中的参数。
*/
ClassPathMapperScanner scanner = new ClassPathMapperScanner(registry);
scanner.setAddToConfig(this.addToConfig);
scanner.setAnnotationClass(this.annotationClass);
scanner.setMarkerInterface(this.markerInterface);
scanner.setSqlSessionFactory(this.sqlSessionFactory);
scanner.setSqlSessionTemplate(this.sqlSessionTemplate);
scanner.setSqlSessionFactoryBeanName(this.sqlSessionFactoryBeanName);
scanner.setSqlSessionTemplateBeanName(this.sqlSessionTemplateBeanName);
scanner.setResourceLoader(this.applicationContext);
scanner.setBeanNameGenerator(this.nameGenerator);
scanner.registerFilters();
scanner.scan(StringUtils.tokenizeToStringArray(this.basePackage, ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS));
}以上就是实例化MapperScannerConfigurer类的主要工作,总结起来就是扫描basePackage包下所有的mapper接口类,并将mapper接口类封装成为BeanDefinition对象,注册到spring的BeanFactory容器中。以下时序图不代表实际过程。
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315
我使用的第一个解析器生成器是Parse::RecDescent,它的指南/教程很棒,但它最有用的功能是它的调试工具,特别是tracing功能(通过将$RD_TRACE设置为1来激活)。我正在寻找可以帮助您调试其规则的解析器生成器。问题是,它必须用python或ruby编写,并且具有详细模式/跟踪模式或非常有用的调试技术。有人知道这样的解析器生成器吗?编辑:当我说调试时,我并不是指调试python或ruby。我指的是调试解析器生成器,查看它在每一步都在做什么,查看它正在读取的每个字符,它试图匹配的规则。希望你明白这一点。赏金编辑:要赢得赏金,请展示一个解析器生成器框架,并说明它的
我有这样的HTML代码:Label1Value1Label2Value2...我的代码不起作用。doc.css("first").eachdo|item|label=item.css("dt")value=item.css("dd")end显示所有首先标记,然后标记标签,我需要“标签:值” 最佳答案 首先,您的HTML应该有和中的元素:Label1Value1Label2Value2...但这不会改变您解析它的方式。你想找到s并遍历它们,然后在每个你可以使用next_element得到;像这样:doc=Nokogiri::HTML(
我想禁用HTTP参数的自动XML解析。但我发现命令仅适用于Rails2.x,它们都不适用于3.0:config.action_controller.param_parsers.deleteMime::XML(application.rb)ActionController::Base.param_parsers.deleteMime::XMLRails3.0中的等价物是什么? 最佳答案 根据CVE-2013-0156的最新安全公告你可以将它用于Rails3.0。3.1和3.2ActionDispatch::ParamsParser::