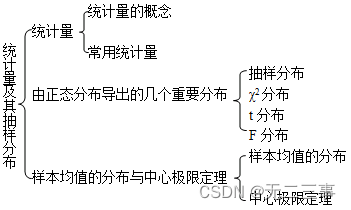
一、知识框架
二、练习题
调节一个装瓶机使其对每个瓶子的灌装量均值为μ盎司,通过观察这台装瓶机对每个瓶子的灌装量服从标准差σ=1.0盎司的正态分布。随机抽取这台机器灌装的9个瓶子组成一个样本,并测定每个瓶子的灌装量。试确定样本均值偏离总体均值不超过0.3盎司的概率。解:设每个瓶子的灌装量为X,X为样本均值,样本容量为n。由于总体X服从正态分布,样本均值X也服从正态分布,且均值相同,标准差为

所以
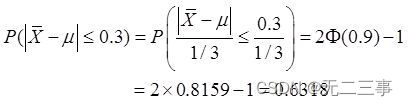
三、简述题
1什么是统计量?为什么要引进统计量?统计量中为什么不含任何未知参数?
答:(1)统计量的定义:设X1,X2,…,Xn是从总体X中抽取的容量为n的一个样本,如果由此样本构造一个函数T(X1,X2,…,Xn),不依赖于任何未知参数,则称函数T(X1,X2,…,Xn)是一个统计量。
(2)引进统计量的原因:在实际应用中,当从某总体中抽取一个样本后,并不能直接用它去对总体的有关性质和特征进行推断,这是因为样本虽然是从总体中获取的代表,含有总体性质的信息,但仍较分散。为了使统计推断成为可能,首先必须把我们所关心的分散在样本中的信息集中起来,针对不同的研究目的,构造不同的样本函数。
(3)统计量中不含未知参数的原因:统计量是样本的一个函数。由样本构造具体的统计量,实际上是对样本所含的总体信息按某种要求进行加工处理,把分散在样本中的信息集中到统计量的取值上,不同的统计推断问题要求构造不同的统计量,所以统计量不包含未知参数。2判断下列样本函数中哪些是统计量?哪些不是统计量?
T1=(X1+X2+…+X10)/10
T2=min(X1,X2,…,X10)
T3=X10-μ
T4=(X10-μ)/σ
答:统计量中不能含有未知参数,故T1、T2是统计量,T3、T4不是统计量。
3简述χ2分布、t分布、F分布及正态分布之间的关系。
答:(1)χ2分布与正态分布之间的关系:随机变量X1,X2,…Xn相互独立,且都服从标准正态分布,则它们的平方和服从自由度为n的χ2分布。
(2)χ2分布、t分布与正态分布之间的关系:随机变量X服从标准正态分布,Y服从自由度为n的χ2分布,且X与Y独立,那么服从自由度为n的t分布。
(3)χ2分布与F分布之间的关系:随机变量Y和Z分别服从自由度为m和n的χ2分布并且相互独立,那么服从第一自由度为m,第二自由度为n的F分布。
4什么是抽样分布?
答:抽样分布的概念:在总体X的分布类型已知时,若对任一自然数n,都能导出统计量T=T(X1,X2,…,Xn)的分布的数学表达式,这种分布称为精确的抽样分布。精确的抽样分布大多是在正态总体下得到的。在正态总体条件下,主要有χ2分布、t分布、F分布,常称之为统计三大分布。
5简述中心极限定理的意义。
答:中心极限定理的意义体现在:
(1)它提出大量的独立随机变量之和具有近似于正态的分布,它不仅提供了计算独立随机变量之和的近似概率的简单方法,而且有助于解释为什么有很多自然群体的经验频率呈现出钟形(即正态)曲线这一事实
(2)中心极限定理这个结论使正态分布在数理统计中具有很重要的地位,也使正态分布有了广泛的应用。
我编写了一个Sinatra应用程序(网站),我想收集网站代码的代码覆盖率信息。我是Ruby的新手,但Google告诉我rcov是一个很好的代码覆盖工具。不幸的是,我在网上可以找到的所有信息只显示了如何获取有关测试用例的代码覆盖率信息-我想要有关我的站点本身的代码覆盖率信息。我想要分析的特定站点文件位于“sdk”和“sdk/vendor”目录中,因此我通常使用“rubysite.rb”运行我的站点的地方我改为尝试以下操作:rcov-Isdk-Isdk/vendorsite.rb它显示了Sinatra启动文本,但随后立即退出,而不是像我的Sinatra应用程序通常那样等待网络请求。有人能告
我有一个Rails应用程序,用户可以在其中设置他们的域并在其中发布内容。我需要收集公共(public)流量统计信息,例如网页浏览量等。此功能的一个很好的例子是我作为客户可以看到的flickr使用统计信息。问题是收集使用信息的最佳方式是什么。应该通过解析日志文件来完成还是应该在运行时收集并存储在数据库中?是否有任何工具或Rails插件已经提供了此功能?此解决方案应该可以很好地扩展,即使每月有数千个域和数百万次网页浏览。 最佳答案 GoogleAnalytics可能是您最好的选择... 关于
我正在构建一个需要计算数据集统计信息的网络应用程序。我需要计算数组的百分位数、平均值、众数和其他统计函数。通常在Python中,我只会使用scipy、numpy或nltk,它们有一个巨大的stat数组函数库。我可以利用任何rubygem或库来执行此操作吗?在没有任何现有库的情况下,是否有一种简单的方法可以在Python中进行数据处理,同时将我的应用程序保留在Ruby/Rails中? 最佳答案 如果你真的需要一个完整的统计库,看看statsample.否则你可能会发现descriptive_statistics成为一个不错的、轻量
这可能是也可能不是灰色地带主题,尽管我的意图肯定不是,所以我的意图不是激起关于逆向工程主题的道德辩论。我是1型糖尿病患者,目前正在接受泵治疗。我是OmniPod用户,这是一个一次性胶囊,可以粘在我的身上并分配胰岛素3天。它由个人糖尿病管理器[PDM](见下文)控制,该管理器控制进餐期间分配的胰岛素量、血糖读数,并且包含一个用于计算碳水化合物的食物指数。(来源:myomnipod.com)新的PDM有一个用于下载数据的USB端口。该软件对Windows用户免费(名为CoPilot的软件包),但不支持Mac。将PDM插入我的Mac后,它像任何其他USB设备一样安装,并为我提供了一个可读卷,
目录一.逻辑控制+方法1.java输入2.循环输入3.switch4.循环结构 5.三种输出6.java生成随机数7.java方法二.习题+方法21.返回二进制中1的个数2.获取一个二进制序列中的偶数位和奇数位,分别输出二进制序列3.JAVA比较字符串是否相同4.牛客网ACM书写格式5.方法的重载一.逻辑控制+方法1.java输入注意大小写!下面代码会出现什么问题??2.循环输入Ctrl+D结束循环输入3.switch面试问题:不能做switch()参数的类型有哪些?longfloatdoubleboolean(其他的都可以)4.循环结构 continue该程序运行的结果是什么??5.三种输出
有哪些Rubygem可以执行数据处理? 最佳答案 我知道有3种从Ruby访问R的方法:RinRubyRSRuby通过Rserve-Ruby-Client预约RinRuby最慢,RSRuby最快,Rserve在性能上更接近RSRuby。然而,RSRuby是非常特定于平台的,您需要使用sharelib选项编译R。Rserve-Ruby-Client在这方面更容易,因为Rserve提供了一个TCP套接字服务器,您可以将命令发送到R解释器。AFAIK不幸的是,对于初学者来说,所有3个文档都没有很好的记录。Rserve-Ruby-Client
假设我有一个带有标题和正文的博客模型。如何显示正文中的字数和标题中的字符数?我希望输出是这样的标题:洛伦正文:LoremLoremLorem这篇文章的字数是3。 最佳答案 "LoremLoremLorem".scan(/\w+/).size=>3更新:如果你需要将rock-and-roll作为一个词来匹配,你可以这样做"LoremLoremLoremrock-and-roll".scan(/[\w-]+/).size=>4 关于ruby-Rails中的字数统计?,我们在StackOver
我试过rakestats但这似乎非常不准确。也许它忽略了几个目录? 最佳答案 我使用免费的Perl脚本cloc。示例用法:phrogz$cloc.180textfiles.180uniquefiles.77filesignored.http://cloc.sourceforge.netv1.56T=1.0s(104.0files/s,19619.0lines/s)-------------------------------------------------------------------------------Languag
我正在创建一个小型计时器Vue组件。用户需要能够启动和停止该计时器。到目前为止,这是我的组件:{{time}}exportdefault{props:['order'],data(){return{time:this.order.time_to_complete,isRunning:false,}},methods:{toggleTimer(){varinterval=setInterval(this.incrementTime,1000);if(this.isRunning){//debuggerclearInterval(interval);console.log('timerst
我正在尝试获取统计数据的一部分,但出于某种原因我遇到了错误,我确实喜欢文档所说的。这是我要发送的内容:https://www.googleapis.com/youtube/v3/search?key=AIzaSyBsobUXzJvjjuHZsMiv7SZAkzVcSgc8F2c&maxResults=5&part=id,snippet,statistics&q=test没有统计部分,这是可行的。{"error":{"errors":[{"domain":"youtube.part","reason":"unknownPart","message":"statistics","locat