ChatGPT淘金热
当前,爆发了ChatGPT热潮,吸引众多科技企业陆续加入其中。这与当年美国西部加利福尼亚的淘金热何其相似。
历史总会惊人的相似,ChatGPT聊天机器人好比一座数字化时代的金矿。全世界科技淘金人蜂拥而至,从潮起到潮落,潮水退去之时,能生存下来的可能不是淘金人,而是卖铲子、卖牛仔裤等提供淘金基础工具的那批人。

站在ChatGPT的行业风口,除了超大模型的演进发展,还将诞生更多的小模型专注服务垂直领域,普惠千家万户,将是必然趋势之一。从大模型走向小模型,谁将是未来的大赢家?带着这个问题,我们不妨先来捋一捋ChatGPT背后的算力和经济账。
01
「似乎不止于此」
ChatGPT带动了服务器与GPU增长
事实上,在业内风生水起,ChatGPT带动了不只是互联网、IT、云计算等科技公司发展的新概念,而且可以看到当前聊天机器人也激发了服务器与GPU的市场增长,毕竟并行计算架构的GPU更适合大规模AI训练与推理。眼下国内可见的是,服务器领域的浪潮信息、中科曙光、新华三、长城等也从中受益。
似乎不止于此,一位云计算行业的专业人士分析指出,ChatGPT进而带动了Cloud Financial Management云财务管理的发展,也就是现在业内热聊的FinOps,这是“Finance”和“DevOps”的综合体,强调运维过程中的成本管理和资源优化。但FinOps要实现更智能的目的,也需要背后算力的强大支撑。
业内人士笑言,什么是人工智能?顾名思义,有多少人工就有多少智能。智能不是凭空诞生,需要凭借深度学习算法对大数据进行“千锤百炼”,而大型语言模型(Large Language Models,LLMs)训练的过程必须依靠强大算力的支撑。在看到ChatGPT被热炒的同时,已经入局的相关科技公司所耗费算力也在不断狂飙。
在清楚ChatGPT背后的算力和经济账之前,需要了解一下大型语言模型(LLMs)是什么?目前业界对大型语言模型(LLMs)有着明确的定义,凭借深度学习算法进行训练,通过大量语料库数据来学习文本的概率分布和语法结构,并自动生成大量与语料库类似的高质量新文本,持续的训练可以提高生成质量。目前大型语言模型(LLMs)已经可以实现如互动问答、文本识别、文本分类、文本生成、代码生成等应用。但是大型语言模型(LLMs)目前无法识别不真实的语料数据。从而在采用正确语料数据过程中,也激发了业界相关数据标准公司的发展。

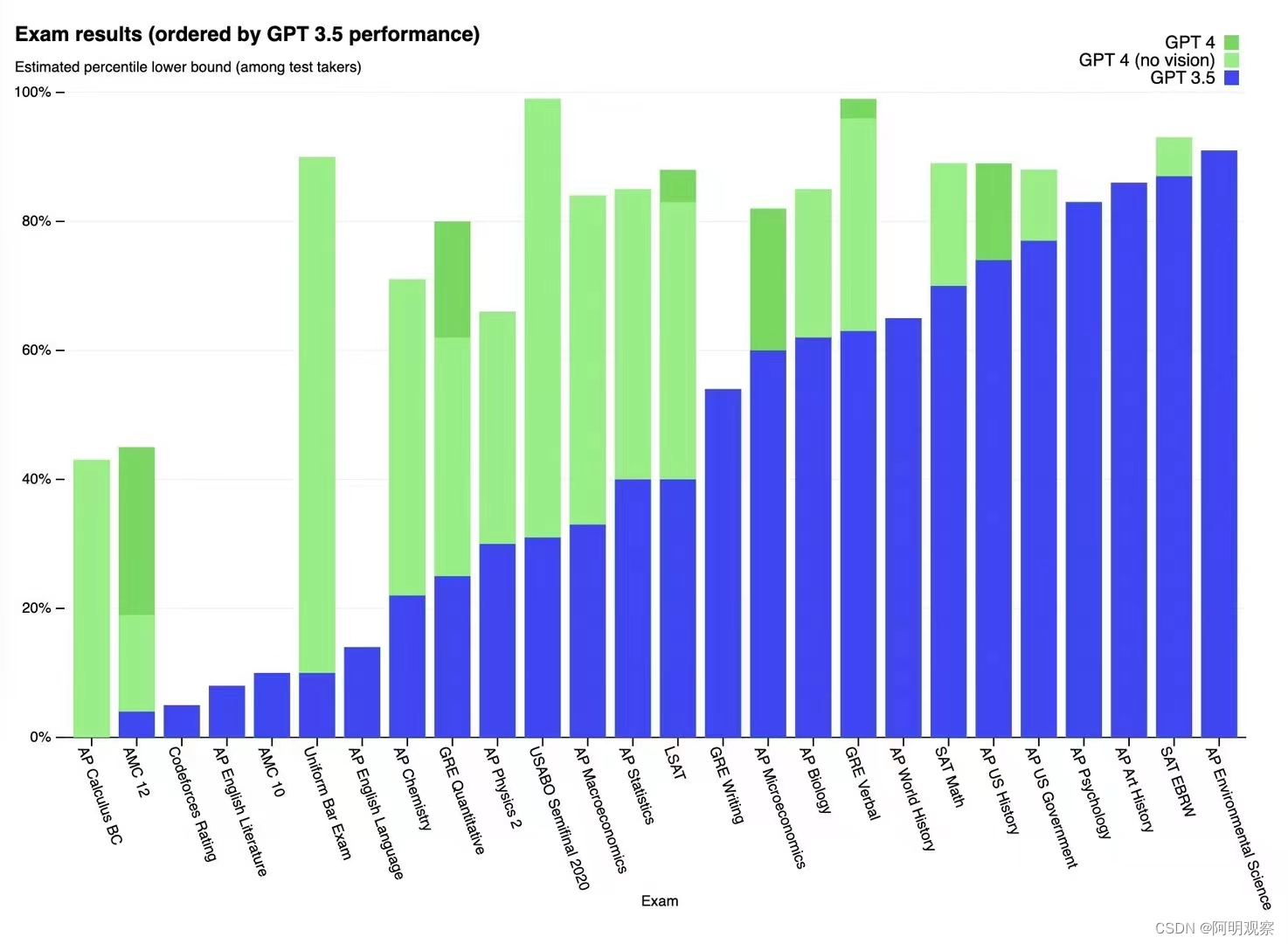
涉及LLMs的经典模型如BERT、GPT-3、Megatron-Turing NLG、GPT-4等。大型语言模型(LLMs)往往在大数据量的大规模数据集上进行训练,如GPT-3就有约1750亿个参数,在570千兆字节的文本上进行训练。而发展到OpenAI在2023年3月最新推出的GPT-4,标志着大型多模态AI开始崛起,业内之前有人预估GPT-4会拥有超过1万亿个参数。虽然OpenAI并未公布GPT-4的具体参数,但是据DeepMind研究发现,GPT-4将比GPT-3略大,达到计算最优所需的训练参数将有5万亿个。

实际上,十分惊人的大模型训练,对芯片的浮点计算能力要求超高。当前,ChatGPT采用的就是GPT-3大型语言模型(LLMs)进行训练,进行一次GPT-3训练需要总算力消耗约为3640PF-days,相当于每秒计算一千万亿次,需要算将近10年时间。这将意味着需要数亿美元投资数个大规模数据中心,每个数据中心算力达到500P,才能支撑得住。来自DeepMind的分析显示,为了最小化训练损失,训练GPT-4所需FLOP每秒浮点运算次数将是GPT-3的10-20倍。

从成本上来看,据Lambda Labs首席科学官Chuan li介绍,参数有1750亿个的GPT-3单次训练成本预计达到数百万美元。对照DeepMind的研究来看,单次训练GPT-4预估达到千万级美元的成本。
据SimilarWeb数据,2023年1月ChatGPT官网总访问量为6.16亿次;据《Fortune》杂志,每次用户与ChatGPT互动,产生的算力云服务成本约0.01美元。ChatGPT训练基于针对GPT-3.5模型进行,基本参数自然不会比GPT-3模型少。假设单位算力成本固定,ChatGPT单月运营所需算力估算约4874.4PFlop/s-day,单月运营对应成本将达到数百万美元。
需要指出的是,为了支撑GPT-3、GPT-3.5、GPT-4的大模型训练,OpenAI采用上万颗英伟达高端A100 GPU打造了一台特别的超级计算机,其基础设施成本就高达数亿美元。
像这样稍微算一算ChatGPT背后所需算力与经济账,巨头玩家“井喷式”投入令人无不惊讶。现在看来,ChatGPT基于大型语言模型(LLMs)训练和推理的前期发展,恐怕只能由少数几个全球科技巨头玩家所主导了。
然而,无论是针对ChatGPT进行怎样的训练,任何“淘金”入局者必然都有一个相同的刚需,希望支撑训练平台的GPU算力的效率更高成本更低,这关乎着任何一家入局者的前期投入与研究回报。
那么,谁来为ChatGPT“淘金”入局者提供更好的GPU加持工具呢?值得深思。
02
「从巨头玩家到垂直行业应用」
未来模型变小才能更有机会
但是,面向垂直行业“淘金”,这样的ChatGPT主流玩家应该不是目前在ChatGPT上投入巨资的微软、谷歌等科技大佬,毕竟他们热衷的还是搜索引擎等大应用的大模型训练。当然,国内也有百度、腾讯、阿里、字节跳动、京东、360、科大讯飞等知名科技企业相继参与了进来,但这些科技公司更多聚焦在自身现有业务体系上做ChatGPT加持,开始热心ChatGPT垂直行业布局的还是比较少。
可见,专注ChatGPT垂直行业发展的主角,应当还是那些拥有强大集成能力的软件开发商。
“下一步,一旦ChatGPT聚焦在垂直行业领域发展,走向千行百业应用,必然会趋使模型变小。”趋动科技(VirtAI Tech)CEO王鲲与业内不少专家持有同样的观点。
更进一步分析来看,ChatGPT的“行业化”才可能更好地实现商业化。或许有人也会有疑问:ChatGPT走向垂直行业领域,为什么会趋使大模型小型化?从大模型到小模型,其中有四大影响,对ChatGPT行业普及十分有利。
一是,降低训练门槛,降低高算力高投入,让更多公司可以参与进来。如前文所述,对于GPT-3、GPT-3.5、GPT-4等大模型训练,必须有着超乎常态的强大算力支撑,以及巨大的成本投入,这对于垂直行业企业想要借助ChatGPT聊天机器人技术做应用创新带来很大的挑战。唯有降低门槛,才有可能实现后续的ChatGPT行业化的普及。
二是,聚焦专业领域,利于提高数据集质量,加速ChatGPT训练品质。在数据标注正确的前提下,高质量数据集决定聊天机器人品质,数据集越大ChatGPT训练的准确度越高。据OpenAI表示,最新发布的新一代多模态模型GPT-4比GPT-3.5参数更多、数据集更大,在安全性和精确性上实现巨大的提升,在受限制请求做出回应的可能性上,低82%;在编造内容的可能性上,低60%。
像微软与谷歌等科技巨头,想要做需要全行业聊天机器人,必然就得立足超大规模、覆盖所有领域的数据集进行训练,为了能保障数据的质量,又必须通过清洗与标准来强化数据的真实性、准确性、完整性与时效性。为此,做好数据标注也成为实现更好训练结果的关键一环,据美国《时代周刊》资料显示,针对ChatGPT,OpenAI与外包公司合作雇佣了大量人员做数据标注服务。即便已经拥有了大规模的数据集,但要满足细分行业的更多需求,ChatGPT目前可以实现的效果还是鞭长莫及。
一旦推动ChatGPT进入垂直化细分行业如医疗、银行、证券、交通等,聚焦某个垂直行业的数据集相对全行业全社会而言要小得多。小而精,小而专。行业越是聚焦,越是利于提高数据集质量,实现ChatGPT训练品质的飞跃提升。
三是,更容易将ChatGPT与垂直行业需求结合,发挥出行业应用价值。植根不同行业的应用需求,构建比较独立、逻辑清晰、数据准确的行业语料数据库,促进ChatGPT训练获得更好结果。更准确的ChatGPT训练,也会更快融入到垂直行业。垂直行业小模型、专业领域数据集缩小了企业的训练范围与强度,降低整体训练成本,从而带动ChatGPT走向to B企业级化。到那时才是ChatGPT的商业化发展阶段,从而带来百家争鸣的产业ChatGPT。
四是,促进ChatGPT云化,打造云端ChatGPT模型与工具集,公有云广泛的创新通路将加速ChatGPT普及。比如亚马逊云科技正在携手相关技术公司Hugging Face打造类似ChatGPT模型的Bloom,同时也与Stability AI合作构建类似OpenAI旗下Dall-E的图像工具,这些模型与工具都将会基于公有云发布。
当然,针对OpenAI公司有着数亿美元投资的微软,在其Azure公有云服务平台上率先推出了OpenAI服务,随后又将ChatGPT技术扩展到Power Platform上,助力开发者实现低代码或无代码开发。诸如此类,后续将会有更多公有云厂商将ChatGPT与公有云结合,或者有更多类似ChatGPT的软件开发商与公有云合作,加速聊天机器人相关技术云化的进程,也将进一步扩展ChatGPT的普及度。这样不仅可以影响C端个人用户,也可以影响B端企业用户,并为ChatGPT应用优化带来敏捷的有效途径。
诚然,从少数巨头玩家到更多的垂直行业,未来ChatGPT相关模型变小才符合行业发展的客观规律。不过,在王鲲看来,任何产业的成长都会经历从make it work到make it perform再到make it cheap三个发展阶段。当前ChatGPT正处于“make it perform”的可用阶段,后续必然会走向好用、用得起的阶段,这样才能让ChatGPT真正融入到垂直行业,走入“寻常百姓家”。
之所以要强调“从可用到好用再到用得起”的发展规律,因为只有真正实现了ChatGPT的“make it cheap”阶段,建立符合行业应用需求的专业聊天机器人,大家用得起后才会出现大规模普及,实现聊天机器人的真正商业化,从热衷于“调戏”ChatGPT到落地行业应用的商业化,彰显其前所未有的行业价值,让更多有志于走在ChatGPT淘金路上的企业获得成功。
03
「软件定义AI算力」
GPU池化将ChatGPT送入千行百业
既然模型的大小与否,从根本上影响到了ChatGPT训练所需的算力与成本,那么要将ChatGPT送入千行百业,就必须针对GPU算力与成本下足功夫。
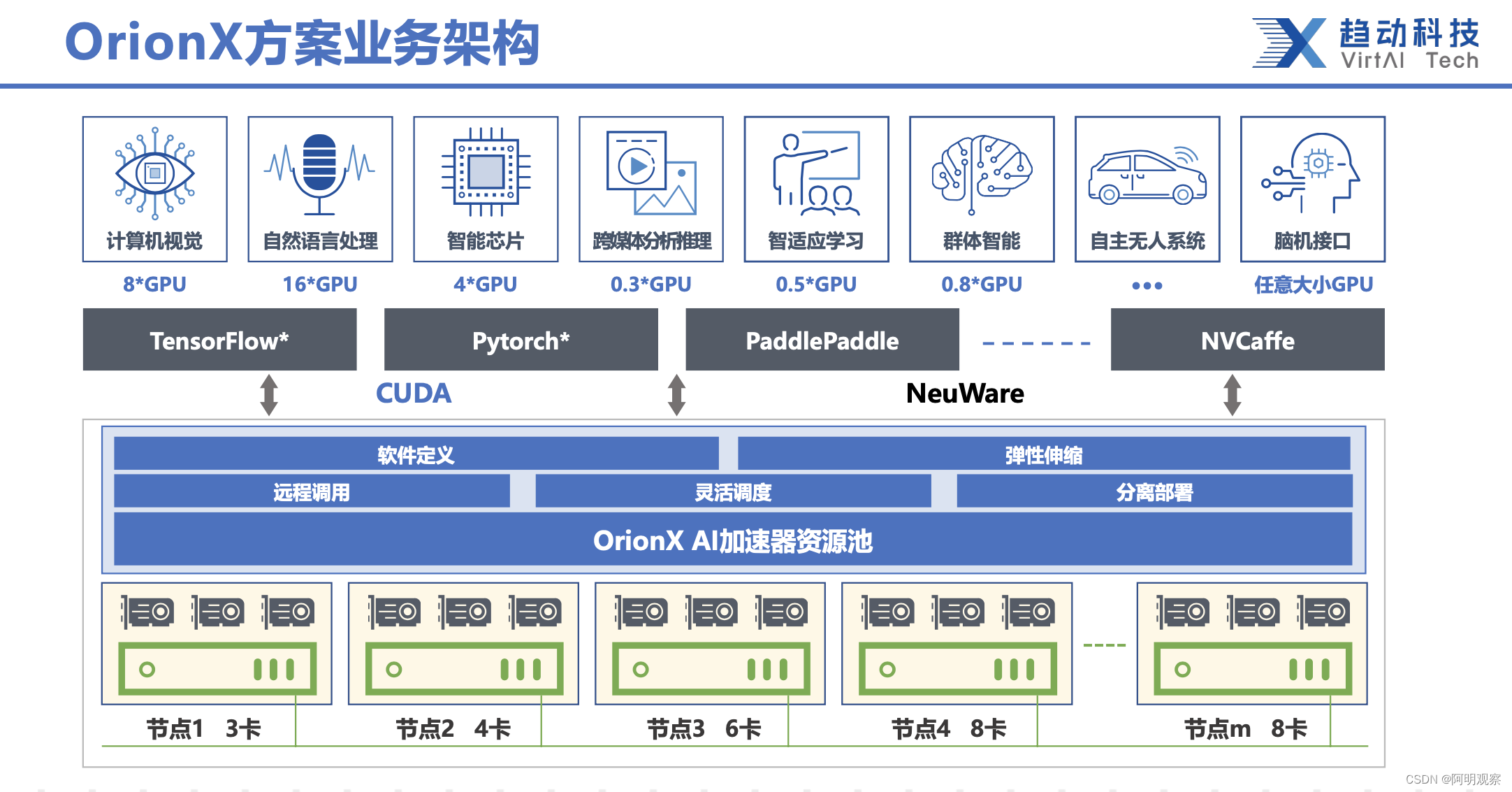
在ChatGPT狂飙之前,成立于2019年的趋动科技(VirtAI Tech)就已经为业界带来了“GPU资源池化”独创技术,并且在银行、证券、能源、教育等多个垂直行业得到了大规模落地与成功应用,为用户“降本增效”的需求实现了更高的GPU利用率与更低的应用成本。
或许这就好比一把科技铁铲,将成为推动更多ChatGPT入局者进入千行百业“淘金”的有力工具。
相关数据显示,在算力方面,全球GPU用户的平均利用率低于15%,据亚马逊云科技在AWS re:Invent 上公布的数据显示,其GPU产品平均利用率仅为10~30%。国内有不少用户的利用率甚至不足10%,对这些用户而言,一颗售价1万美元的芯片可能其中9000美元就白白浪费了。
面向ChatGPT训练需要底层AI服务器的强大支撑,效率越高性能越好就越能让ChatGPT训练获得高价值的结果,其中的关键就是要将GPU能力发挥到极致。在支撑ChatGPT在垂直行业做模型训练方面,行业领域的用户需要构建更高效的服务器与GPU算力平台。对于任何一个行业用户而言,一旦上马ChatGPT模型训练,算力需求必然凸现,降低成本提高算力的效率将是必然之选。
纵观GPU的发展,在GPU资源利用的演进路线上,可以分为简单虚拟化、任意虚拟化、远程调用和资源池化四个阶段。提到GPU池化,往往有人容易想到传统的GPU虚拟化技术,或者叫GPU切片技术。但是,需要注意的是,传统的GPU虚拟化技术基于硬件思维,只能对本地物理机上的GPU进行虚拟切割。而GPU资源池化技术基于整个数据中心范围,不仅可以支持本地GPU虚拟化,而且打破单机资源调度的物理边界,让用户透明使用任意物理机上、任意数量、任意品牌厂商的GPU资源。作为AI算力资源池化解决方案的创新供应商,趋动科技的OrionX完全支持裸机、虚拟机、容器以及K8S等多种环境的完整的资源池化。
全球云观察分析指出,只有站在整个数据中心的高度,解决GPU利用率低、成本高、分配与管理难等问题,才能从真正意义上支撑ChatGPT面向垂直行业各种规模的数据集训练。
针对用户的不同采购需求,采取了两种灵活的商业模式,一是采取私有部署,类似VMware的软件授权销售方式,二是类似Flink基于公有云的服务方式。
对于第一种私有部署的商业模式,趋动科技聚焦软件定义AI算力,凭借GPU池化的创新,支撑ChatGPT的行业模型训练降本增效,将ChatGPT送入千行百业成为更大可能。为此,趋动科技在GPU软件领域的创新目的非常明确,打造GPU届的“VMware”,走的是标准化的商业软件道路。趋动科技赋能客户构建一个弹性、动态、灵活、高效的软件定义GPU算力资源池,根据用户具体的硬件与软件需求,将所有GPU的静态分配转换成动态分配,灵活支持用户实现GPU利用率最大化,提高利用率3-5倍,助力垂直行业的ChatGPT训练实现降本增效。
对于第二种类似Flink基于公有云的服务方式,趋动科技打造的趋动云是趋动科技利用其在算力资源池和开发训练平台领域的深厚积累,面向企业、科研和个人AI开发者构建的开发和推理训练服务。通过连接全球算力,趋动云可以为用户提供低成本、高按需保障、无厂商锁定的AI算力;通过为AI算法开发全流程提供优化服务,并构建全球开发者和项目资源分享社区,趋动云可以帮助AI开发者快速实现最佳实践。相关测试表明,采用同样模型训练,达到相同精度,目前采用算力池化的趋动云,比公有云成本低60%。
到目前为止,趋动云上线5个月左右,已经获得近万名注册用户,活跃用户数千人,活跃用户大部分来自全球高校AI相关专业老师与学生、有AI算法团队的中小企业和个人开发爱好者。目前前期主要构件AI开发者生态,培养GPU池化模式的未来用户基础。趋动云面向AI开发者实行“拎包入住”方式,并且开放大量数据集与源代码集,也已经上线众多模型,做了大量适合AI开发者的“刚需配套”,并且数据集在未来将进一步得到扩展。
此外,业内也有人说过,AI的尽头就是算力,就是GPU。从摩尔定律在计算芯片领域依然维持,很大原因是因为GPU迅速崛起,弥补了CPU发展的趋缓。目前GPU的晶体管数量增长已超过CPU,CPU晶体管开始落后于摩尔定律。这是一个数据智能的时代,也将是擅长浮点运算的GPU大放异彩的时代。
长风破浪会有时,直挂云帆济沧海。对于有用户实践、有技术积累、有行业理想的趋动科技而言,面对难得一遇的大好机会,大力支持ChatGPT等人工智能技术实现更多行业应用,加强发展GPU领域的相关技术创新,抓住前所未有的发展机遇,继续打磨ChatGPT垂直行业“淘金”的有力工具,进一步丰富AI算力资源池化解决方案,必将在中国行业数字化发展之路上赢得属于自己的未来。
机不可失,时不再来。站在ChatGPT的行业风口,趋动科技正迎风而上。
(by Aming)
- END-
你
怎
么
看
?
欢迎文末评论补充!
【全球云储观察 | 阿明观察 |科技明说】专注科技公司分析,用数据说话,带你看懂科技。本文和作者回复仅代表个人观点,不构成任何投资建议。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit