文章目录
匿名管道只能用来进行进程间通信,让具有血缘关系的进程进行通信
让毫不相关的进程之间进行通信,就需要采用命名管道通信
因为该文件有文件名称的,而且必须要有,所以叫做命名管道
输入 man mkfifo 指令

制作一个 FIFOS ,表示命名管道

mkfifo fifo 制作一个管道 ,并命名为 fifo
文件类型以p开头,被称为管道文件
输入 man 3 mkfifo 指令

pathname代表路径,若不带路径只有文件名,默认在当前路径下
mode代表创建权限的模式 ,即创建文件的权限(666、664)
成功返回0,失败返回-1

将hello world 重定向到fifo管道中
但是好像并不会写入
fifo只代表一种符号,向符号写入消息并不会刷新到磁盘上,而是只会把hello world写到管道中
但是管道文件是内存文件,所以大小不会改变
通过赋值SSH渠道,创建终端2
在保证终端1的输出重定向 运行的情况下
cat默认从显示器中读取
在终端2中 使用输入重定向 将 fifo重定向到显示器中

最终在终端2中显示 hello world
而实际上 输出重定向和输入重定向 的启动都是进程,并且毫不相关
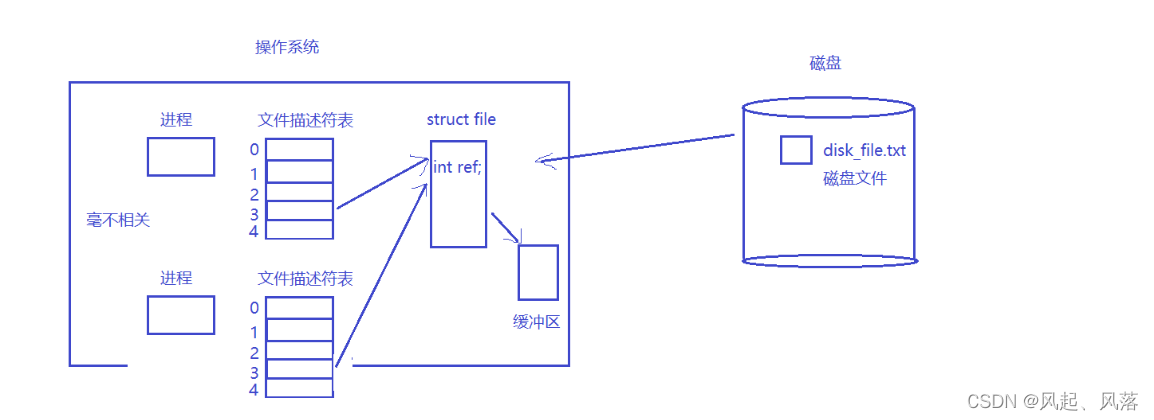
要打开对应的文件,就会在操作系统内创建struct file对象,struct file对象有自己的缓冲区
由于0 1 2 分别被占用,所以3指向struct file对象
若有一个毫不相关的进程,也打开磁盘中的文件,操作系统内部就不会再创建struct file对象,
会直接把struct file对象的地址填入新建立进程对应的下标里
在struct file对象中存在一个引用计数默认为1 ,当新创建一个进程时,引用计数就会变成2
此时两个进程指向同一份文件
目的是让两个进程之间进行通信,所以就不应该把数据刷到磁盘上,
应该把磁盘文件改为内存级的,不会进行刷盘,把它命名为管道文件
文件的唯一性,使用路径表示的
让不同的进程通过文件路径+文件名看到同一个文件,并打开,就是看到了同一个资源
在vscode中,分别创建server.cc文件和client.cc文件以及makefile
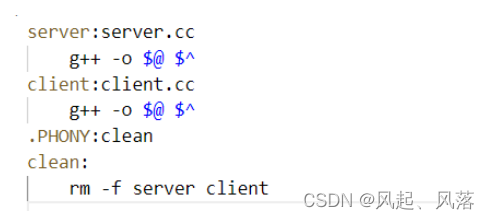
若这样创建makefile,只会执行server可执行程序
server是从上到下扫描遇到的第一个真正的目标文件
makefile从上到下扫描时,会默认执行第一组依赖关系和依赖方法
为了不让client和server成为目标文件
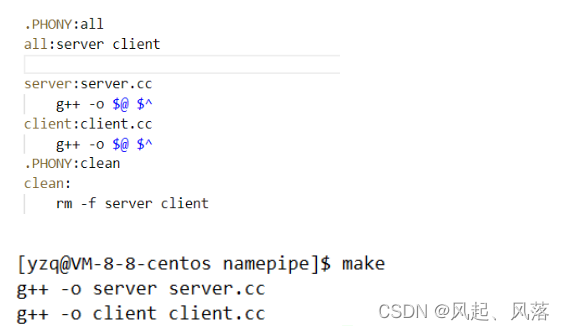
这样就可以一次生成两个可执行程序了
建立一个公共头文件 comm.hpp,在内部创建公共的路径以及mode
(以hpp结尾.cpp的实现代码混入.h头文件当中,定义与实现都包含在同一文件)
#pragma once
#include<iostream>
#include<string>
#define NUM 1024
using namespace std;
const string fifoname="./fifo";//管道名字为当前路径创建的fifo
mode_t mode=0666;//默认权限为0666
这样 server文件和client文件就会调用同一份文件路径了
创建server.cc文件,使用mkfifo函数创建管道文件


此时运行可执行程序,即可生成fifo管道文件

权限变为664 ,可是在comm.hpp中设置的权限为666
mode最终是要与umask进行操作的
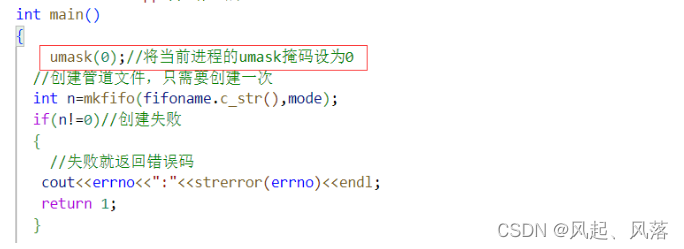
手动将掩码置为0后,即可解决权限被修改的问题
手动删除fifo后,再次运行
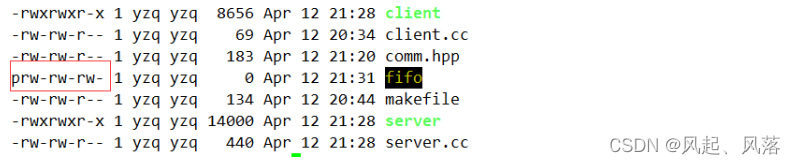
此时权限还是666,没有被修改

将文件描述符内容打印到buffer中
分为三种情况
若返回>0,则读取成功,而系统并不知道buffer是一个字符串,而我们自己知道,所以要在结尾加上\0
若返回==0,说明读到文件结尾,当写端关闭时,读端才会读到文件结尾
若返回<0,说明读取失败,则返回错误码
//服务端
#include<iostream>
using namespace std;
#include<sys/stat.h>
#include<sys/types.h>
#include<cerrno>
#include<cstring>
#include<fcntl.h>
#include<unistd.h>
#include"comm.hpp"//公共路径
int main()
{
umask(0);//将当前进程的umask掩码设为0
//创建管道文件,只需要创建一次
int n=mkfifo(fifoname.c_str(),mode);
if(n!=0)//创建失败
{
//失败就返回错误码
cout<<errno<<":"<<strerror(errno)<<endl;
return 1;
}
cout<<"create fifo success"<<endl;
//2.让服务端直接开启管道文件
int rfd=open(fifoname.c_str(),O_RDONLY);
//第二个参数代表读
//以读方式打开文件
if(rfd<0)//创建失败
{
//失败就返回错误码
cout<<errno<<":"<<strerror(errno)<<endl;
return 2;
}
cout<<"open fifo success,begin"<<endl;
// 3.正常通信
char buffer[NUM];
while(true)
{
buffer[0]=0;
//rfd作为文件描述符(0/1/2)
ssize_t n=read(rfd,buffer,sizeof(buffer)-1);//将rfd的内容读到buffer中
if(n>0)//读取成功
{
buffer[n]='\0';
cout<<"client#"<<buffer<<endl;
}
else if(n==0)//读到文件结尾为0
{
//写端关闭
cout<< "cilent quit,me too"<<endl;
break;
}
else //读取失败
{
cout<<errno<<":"<<strerror(errno)<<endl;
break;
}
}
//关闭不要的fd
close(rfd);
unlink(fifoname.c_str());//删除文件fifo
return 0;
}
由于在服务端创建了管道文件,所以在客户端不用创建管道文件

直接打开文件即可,以写方式打开文件
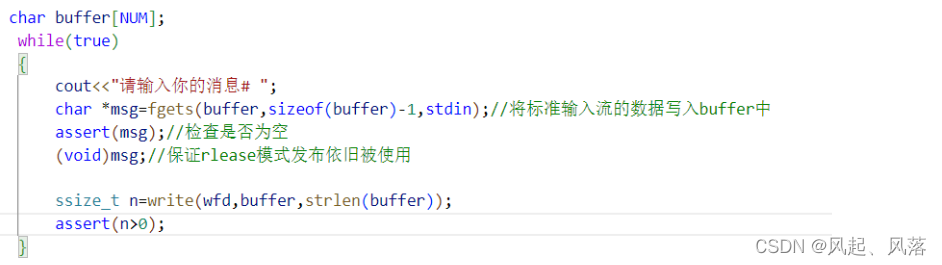
为了避免输入的单词有空格存在
输入 man fgets 指令
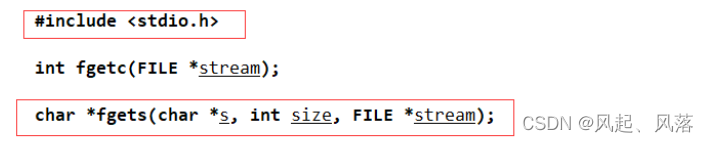
从指定的流中获取字符串,并规定字符串的大小
因为有两个可执行程序存在,所以需要两个终端
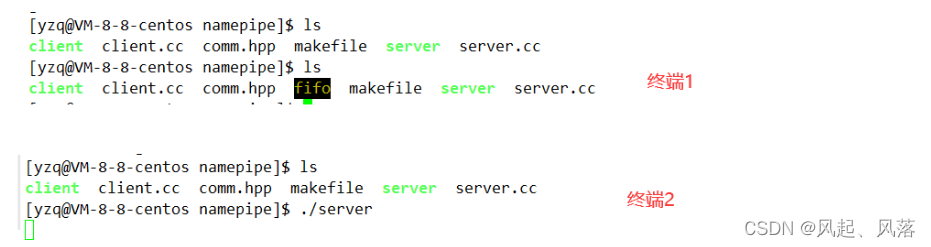
当终端2没有运行server时,没有管道文件存在,而终端1运行server后,终端1中出现管道文件

当终端1运行client时,输入对应的信息,终端2中会自动显示出来
client端可以将信息发送给server端
//客户端
#include<iostream>
using namespace std;
#include<sys/stat.h>
#include<sys/types.h>
#include<cerrno>
#include<cstring>
#include<fcntl.h>
#include<unistd.h>
#include<cstdio>
#include<cassert>
#include"comm.hpp"//公共路径
using namespace std;
int main()
{
//不需要创建管道文件,打开文件即可
int wfd=open(fifoname.c_str(),O_WRONLY);//以写的方式打开文件
if(wfd<0)//说明打开失败
{
cout<<errno<<":"<<strerror(errno)<<endl;
return 0;
}
//进行常规通信
char buffer[NUM];
while(true)
{
cout<<"请输入你的消息# ";
char *msg=fgets(buffer,sizeof(buffer)-1,stdin);//将标准输入流的数据写入buffer中
assert(msg);//检查是否为空
(void)msg;//保证rlease模式发布依旧被使用
//fgets会读取回车 即\n
buffer[strlen(buffer)-1]=0;//12345\n 把\n位置覆盖为\0
ssize_t n=write(wfd,buffer,strlen(buffer));
assert(n>=0);
}
close(wfd);//关闭文件描述符
return 0;
}
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
当我在我的Rails应用程序根目录中运行rakedoc:app时,API文档是使用/doc/README_FOR_APP作为主页生成的。我想向该文件添加.rdoc扩展名,以便它在GitHub上正确呈现。更好的是,我想将它移动到应用程序根目录(/README.rdoc)。有没有办法通过修改包含的rake/rdoctask任务在我的Rakefile中执行此操作?是否有某个地方可以查找可以修改的主页文件的名称?还是我必须编写一个新的Rake任务?额外的问题:Rails应用程序的两个单独文件/README和/doc/README_FOR_APP背后的逻辑是什么?为什么不只有一个?
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba
我正在尝试使用以下代码通过将ffmpeg实用程序作为子进程运行并获取其输出并解析它来确定视频分辨率:IO.popen'ffmpeg-i'+path_to_filedo|ffmpegIO|#myparsegoeshereend...但是ffmpeg输出仍然连接到标准输出并且ffmepgIO.readlines是空的。ffmpeg实用程序是否需要一些特殊处理?或者还有其他方法可以获得ffmpeg输出吗?我在WinXP和FedoraLinux下测试了这段代码-结果是一样的。 最佳答案 要跟进mouviciel的评论,您需要使用类似pope
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
我想从rubyrake脚本运行一个可执行文件,比如foo.exe我希望将foo.exe的STDOUT和STDERR输出直接写入我正在运行rake任务的控制台.当进程完成时,我想将退出代码捕获到一个变量中。我如何实现这一目标?我一直在玩backticks、process.spawn、system但我无法获得我想要的所有行为,只有部分更新:我在Windows上,在标准命令提示符下,而不是cygwin 最佳答案 system获取您想要的STDOUT行为。它还返回true作为零退出代码,这可能很有用。$?填充了有关最后一次system调
A/ctohttp://wiki.nginx.org/CoreModule#usermaster进程曾经以root用户运行,是否可以以不同的用户运行nginxmaster进程? 最佳答案 只需以非root身份运行init脚本(即/etc/init.d/nginxstart),就可以用不同的用户运行nginxmaster进程。如果这真的是你想要做的,你将需要确保日志和pid目录(通常是/var/log/nginx&/var/run/nginx.pid)对该用户是可写的,并且您所有的listen调用都是针对大于1024的端口(因为绑定(