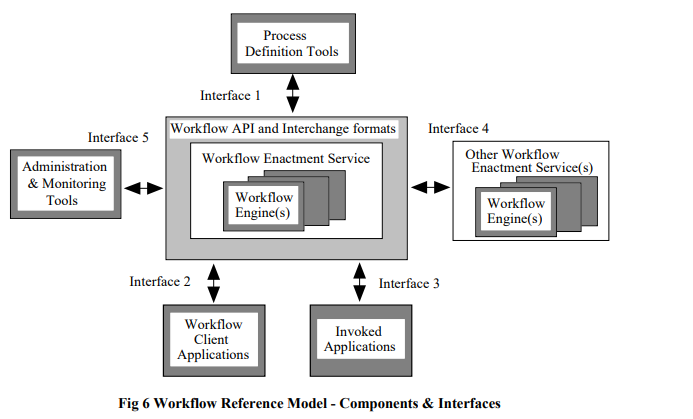

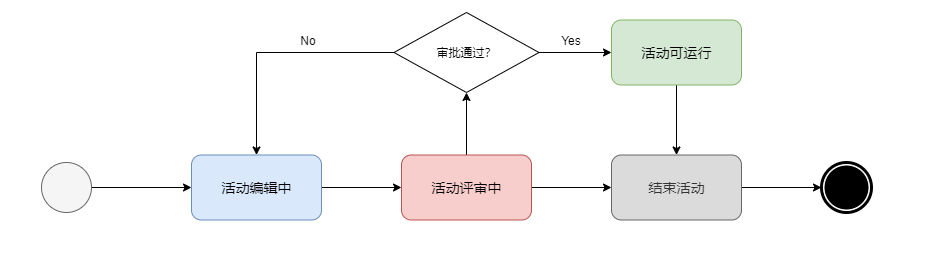
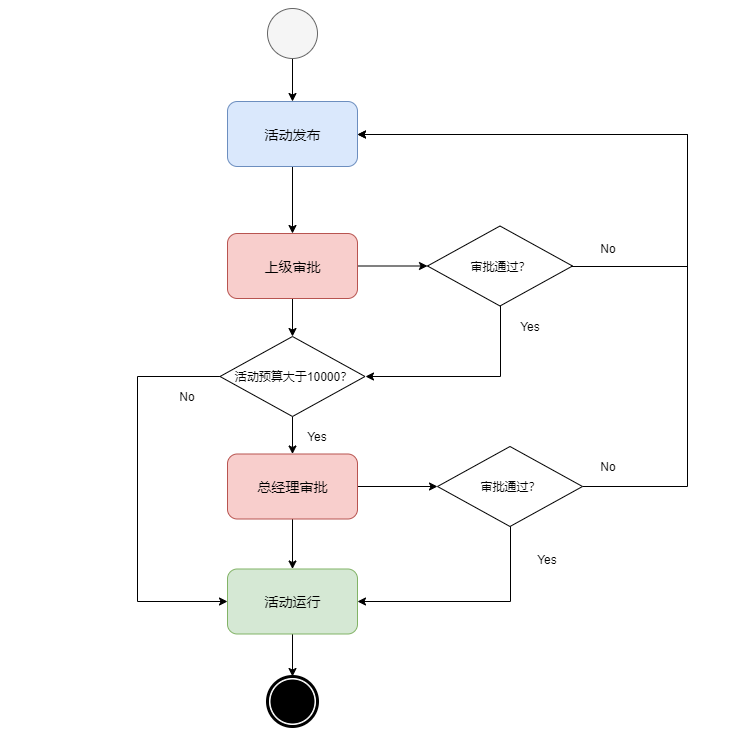
 可以看到不同类型的工作流不是完全割裂的,状态机工作流中也可以结合着条件和规则进行操作节点转换的过程。在软件开发中,一般会考虑结合状态机和规则驱动的工作流。
可以看到不同类型的工作流不是完全割裂的,状态机工作流中也可以结合着条件和规则进行操作节点转换的过程。在软件开发中,一般会考虑结合状态机和规则驱动的工作流。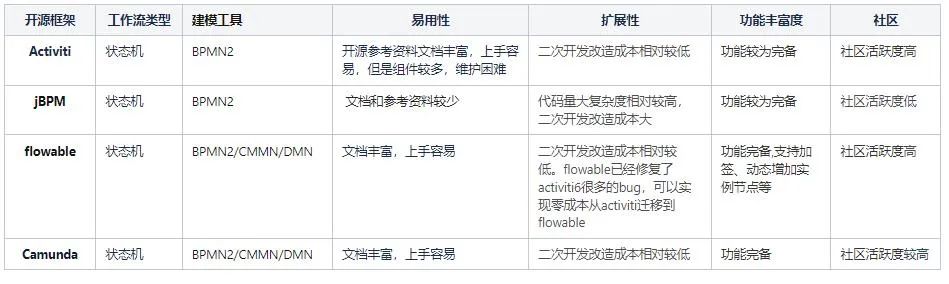
public interface FlowEngine {
/**
* 根据流程定义key,参数列表启动流程实例
*
*/
FlowInstance startInstance(String processDefKey, Map<String, Object> args);
/**
* 根据流程定义主键ID,参数列表执行流程任务(推动流程自动流转)
* 统一事务控制
*/
void execInstance(Long instanceId, Map<String, Object> args) throws FlowAuthorityException;
/**
* 获取流程定义process服务
*
*/
ProcessService process();
/**
* 获取流程实例服务
*
*/
InstanceService instance();
/**
* 获取任务节点服务
*
*/
TaskService task();
}public interface ProcessService {
/**
* 创建流程定义模板
*
*/
void create(String definition);
/**
* 发布流程定义模板
*
*/
void deploy(String fileName);
/**
* 获取流程key对应的流程定义
*/
FlowProcess getProcessByDefKey(String processDefKey);
}public interface InstanceService {
/**
* 创建流程实例
*
*/
FlowInstance createInstance(FlowProcess process, Map<String, Object> args);
/**
* 执行流程实例
*
* @param instanceId 流程实例id
*/
void exec(Long instanceId);
/**
* 根据id获取流程实例
*
* @param instanceId
* @return
*/
FlowInstance getById(Long instanceId);
}public interface TaskService {
/**
* 根据任务模型、执行对象创建新的任务
*
*/
FlowTask createTask(TaskModel taskModel, Execution execution);
/**
* 完成任务
*
*/
FlowTask complete(Long taskId, Map<String, Object> args);
/**
* 获取流程实例中正在进行的任务
*
*/
FlowTask getActiveTask(Long instanceId);
/**
* 获取流程实例上一个已完成的任务
*
*/
FlowHistTask getLastDoneTask(Long instanceId);
}总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer