Python3.7+RIDE+Robot Framework环境搭建过程中,安装完robotframework-httplibrary后,加载HttpLibrary.HTTP报错
Importing test library "HttpLibrary.HTTP" failed
经过网上查询分析,发现HttpLibrary是基于python2.0开发的,高版本的python中可能会存在一些兼容性问题,所以我们就围绕兼容问题进行处理。
Ride在应用过程中,遇到的兼容问题还是蛮多的,只能多多记录,以便后用。
pip list检查from robotframework-httplibrary的类包是否安装成功
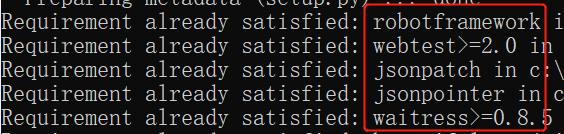
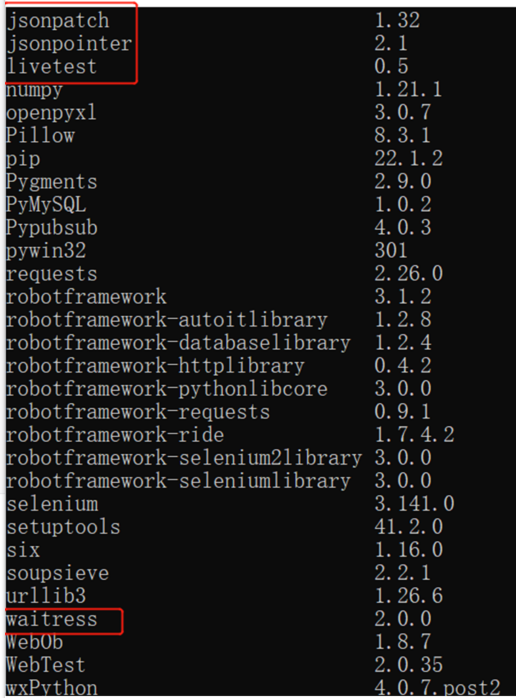
pip install livetesthttps://pypi.org/project/livetest/#files下载livetest-0.5.tar.gz,解压至本地进行修改
目录1: \livetest-0.5\livetest\__init__.py
修改1:import httplib修改为 import http.client as httplib
修改2:import urlparse修改为import urllib.parse
修改3:from Cookie import BaseCookie, CookieError修改为import http.cookiejar
修改4:except CookieError,e【Pyhotn3.x开始已不支持此种写法】修改为except CookieError as e
目录2:\livetest-0.5\setup.py
修改1:long_description=file('README.rst').read()修改为long_description=open('README.rst').read()
修改2:version=livetest.version修改为version='0.5'
修改3:author_email=livetest.author:修改为author_email='storborg@mit.edu'
目录3:\livetest-0.5\test\test_select.py
修改1:except ValueError, exc修改为except ValueErroras as exc
命令安装livetest
管理员身份进行CMD命令窗口,切换路径到\livetest-0.5目录下,执行 python setup.py install,安装成功。
目录4:python安装目录下\Lib\site-packages\HttpLibrary\__init__.py
修改1:from urlparse import urlparse修改为from urllib.parse import urlparse
修改2:except ValueError, e修改为except ValueError as e
最后,重启ride,HttpLibrary.HTTP加载正常。
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba