串的模式匹配
思想: 将主串中所有长度为m的子串依次与模式串对比,直到找到一个完全匹配的子串或所有子串都不匹配为止。

具体代码展示:
1)串的初始化工作
#include<stdio.h>
#define MAXLEN 255 //预定义最大串长
typedef struct {
char ch[MAXLEN];//每一个分量存储一个字符
int length;//串的实际长度
}SString;
// 字符串下标从1开始记录,将ch[0]设置为‘\0’
SString createString() {
SString str;
str.ch[0] = '\0';
str.length = 0;
return str;
}
//赋值操作
void StrAssign(SString& S, char chars[])//生成串S
{
int i = 0;
while (chars[i] != '\0')
{
//第一个位置不用
S.ch[i+1] = chars[i];//将字符串常量的值赋值给S
i++;
}
S.length = i+1;
}
//打印串
void PrintString(SString S) {
if (S.length == 0) {
printf_s("当前串为空");
}
else {
for (int i = 1; i < S.length; i++) {
printf_s("%c", S.ch[i]);
}
printf_s("\n");
}
}
2)简单模式匹配算法实现
int Index(SString S, SString T) {
int i = 1, j = 1;
while (i <= S.length && j <= T.length) {
//相等则指针+1
if (S.ch[i] == T.ch[j]) {
i++;
j++;
}
else {
i = i - j + 2;//主串指针退回到当前指针的下一个位置
j = 1;//模式串指针退回到第一个位置
}
//放在这里判断是为了返回第一个匹配的子串位置,
//T的长度是实际长度+废弃的第一个位置长度,所以这里减一
//说明匹配完成,指向T的最后一个元素的下一个位置
if (j > T.length - 1) {
return i - T.length + 1;
}
}
return 0;
}
3)主函数调用
int main(){
SString S=createString(), T=createString();
char ch1[] = { "aaabaabcaabdabacaabc" };
char ch2[] = { "aabc" };
StrAssign(S, ch1);
StrAssign(T, ch2);
printf_s("S串元素为:");
PrintString(S);
printf_s("T串元素为:");
PrintString(T);
printf_s("----------------------------\n");
printf_s("简单模式匹配算法:\n");
printf_s("子串在主串位置为:%d", Index(S, T));
}
4)结果展示
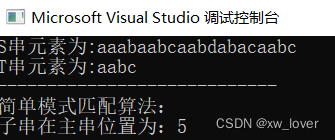
注意:子串匹配的是在主串中首次出现的,在所给例子中,子串出现了两次,但是记录的位置是第一次出现的位置。
简单模式匹配算法: 当子串的某一字符与主串对应的字符不匹配时,主串的指针会回溯到扫描第一个位置的下一个位置,子串的指针也会回溯到第一个位置,然后重新匹配。但是没必要去比较后面的某些位置,因为在主串中,匹配失败的那个字符肯定不是b,所以下一次指针位置应该为3,而不是2,如下图所示。
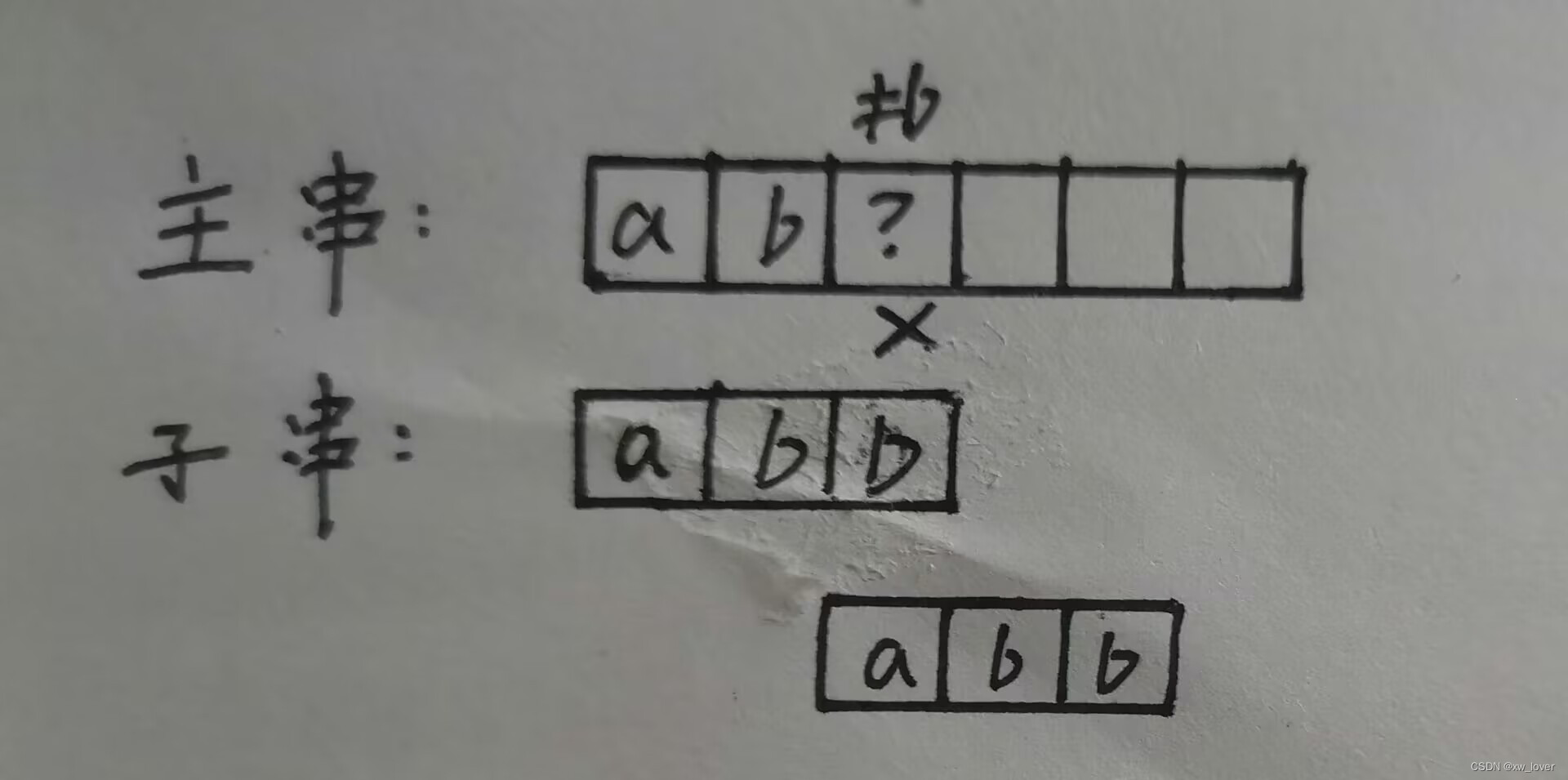
所以,也就引出了KMP算法,即将子串的指针位置组成一个next数组,这样就极大地减少比较的次数。next[i]的含义是在第i个字符与主串发生失配时,则跳到字串的next[i]位置重新与主串当前位置进行比较。
比如主串为:abacaabefc,子串为aab,则next数组为0,1,2。手算可以推出来的,并且要注意的是next[1]肯定等于0,为什么?因为当子串的第一个字符匹配失败时,那肯定转到第二个位置继续匹配。
具体代码展示:
1)next数组代码求解过程如下(不作过多讲解)
//求next数组
//next[1]为0,next[2]为1
void get_next(SString T, int next[]) {
int i = 1, j = 0;
next[1] = 0;
while (i < T.length) {
if (j == 0 || T.ch[i] == T.ch[j]) {
i++;
j++;
next[i] = j;
}
else {
j = next[j];
}
}
}
2)KMP算法实现
int Index_KMP(SString S, SString T, int next[]) {
int i = 1, j = 1;
while (i <= S.length&&j <= T.length) {
if (j == 0 || S.ch[i] == T.ch[j]) {
i++;
j++;
}
else {
j = next[j];//确定模式串的指针位置
}
//匹配成功
if (j > T.length-1) {
return i - T.length+1;
}
}
return 0;
}
3)主函数调用
int main(){
SString S=createString(), T=createString();
char ch1[] = { "abacaabefc" };
char ch2[] = { "aab" };
StrAssign(S, ch1);
StrAssign(T, ch2);
printf_s("S串元素为:");
PrintString(S);
printf_s("T串元素为:");
PrintString(T);
printf_s("----------------------------\n");
printf_s("简单模式匹配算法:\n");
printf_s("子串在主串位置为:%d", Index(S, T));
printf_s("\n----------------------------\n");
printf_s("KMP算法:\n");
int next[10] = { -1 };//第一个值弃用
get_next(T, next);
printf_s("next数组元素为:");
for (int i = 1; i < T.length;i++) {
printf_s("%d ", next[i]);
}
printf_s("\n子串在主串位置为:%d", Index_KMP(S, T,next));
}
4)运行结果

KMP算法问题: 当子串’aaaab’与’aaabaaaab’匹配时,当i=4,j=4时,子串与主串匹配失败,用之前的next数组还需要和S4和P3、S4和P2、S4和P1比较,显然没有意义。问题就出在Pj=Pnext[j]上,因为当Pj≠Sj时,下次匹配的必然是Pnext[j]和Sj比较,如果Pj=Pnext[j],相当于重复匹配相同字符,那怎么办,可以继续递归,将next[j]修改为next[next[j]]直至两者不相等为止。
具体代码实现:
1)next数组优化
//求next数组优化,匹配失败的那个位置的字符肯定不是当前匹配子串的字符
void get_nextval(SString T, int nextval[]) {
int i = 1, j = 0;
nextval[1] = 0;
while (i < T.length) {
if (j == 0 || T.ch[i] == T.ch[j]) {
i++;
j++;
if (T.ch[i] != T.ch[j]) {
nextval[i] = j;
}
else {
nextval[i] = nextval[j];
}
}
else {
j = nextval[j];
}
}
}
2)主函数调用
int main(){
SString S=createString(), T=createString();
char ch1[] = { "aaabaaaab" };
char ch2[] = { "aaaab" };
StrAssign(S, ch1);
StrAssign(T, ch2);
printf_s("S串元素为:");
PrintString(S);
printf_s("T串元素为:");
PrintString(T);
printf_s("----------------------------\n");
printf_s("简单模式匹配算法:\n");
printf_s("子串在主串位置为:%d", Index(S, T));
printf_s("\n----------------------------\n");
printf_s("KMP算法:\n");
int next[10] = { -1 };//第一个值弃用
get_next(T, next);
printf_s("next数组元素为:");
for (int i = 1; i < T.length;i++) {
printf_s("%d ", next[i]);
}
printf_s("\n子串在主串位置为:%d", Index_KMP(S, T,next));
printf_s("\n----------------------------\n");
get_nextval(T, next);
printf_s("nextval数组元素为:");
for (int i = 1; i < T.length; i++) {
printf_s("%d ", next[i]);
}
printf_s("\n子串在主串位置为:%d\n", Index_KMP(S, T, next));
return 0;
}
3)运行结果

我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
如何匹配未被反斜杠转义的平衡定界符对(其本身未被反斜杠转义)(无需考虑嵌套)?例如对于反引号,我试过了,但是转义的反引号没有像转义那样工作。regex=/(?!$1:"how\\"#expected"how\\`are"上面的正则表达式不考虑由反斜杠转义并位于反引号前面的反斜杠,但我愿意考虑。StackOverflow如何做到这一点?这样做的目的并不复杂。我有文档文本,其中包括内联代码的反引号,就像StackOverflow一样,我想在HTML文件中显示它,内联代码用一些spanMaterial装饰。不会有嵌套,但转义反引号或转义反斜杠可能出现在任何地方。
我有一个驼峰式字符串,例如:JustAString。我想按照以下规则形成长度为4的字符串:抓取所有大写字母;如果超过4个大写字母,只保留前4个;如果少于4个大写字母,则将最后大写字母后的字母大写并添加字母,直到长度变为4。以下是可能发生的3种情况:ThisIsMyString将产生TIMS(大写字母);ThisIsOneVeryLongString将产生TIOV(前4个大写字母);MyString将生成MSTR(大写字母+tr大写)。我设法用这个片段解决了前两种情况:str.scan(/[A-Z]/).first(4).join但是,我不太确定如何最好地修改上面的代码片段以处理最后一种
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我真的为这个而疯狂。我一直在搜索答案并尝试我找到的所有内容,包括相关问题和stackoverflow上的答案,但仍然无法正常工作。我正在使用嵌套资源,但无法使表单正常工作。我总是遇到错误,例如没有路线匹配[PUT]"/galleries/1/photos"表格在这里:/galleries/1/photos/1/edit路线.rbresources:galleriesdoresources:photosendresources:galleriesresources:photos照片Controller.rbdefnew@gallery=Gallery.find(params[:galle
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
我已经在mountainlion上成功安装了rbenv和rubybuild。运行rbenvinstall1.9.3-p392结束于:校验和不匹配:ruby-1.9.3-p392.tar.gz(文件已损坏)预期f689a7b61379f83cbbed3c7077d83859,得到1cfc2ff433dbe80f8ff1a9dba2fd5636它正在下载的文件看起来没问题,如果我使用curl手动下载文件,我会得到同样不正确的校验和。有没有人遇到过这个?他们是如何解决的? 最佳答案 tl:博士;使用浏览器从http://ftp.rub