推荐可以再下个Xshell用于操作终端。
Xshell免费版官网下载地址:https://www.xshell.com/zh/free-for-home-school/
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 。这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。
sudo useradd -m hadoop -s /bin/bash接着使用如下命令设置密码,如果提示密码过于简单可以无视,只要两次相同即可:
sudo passwd hadoop可为 hadoop 用户增加管理员权限,方便部署:
sudo adduser hadoop sudo然后切换到新建的hadoop用户下:
su hadoop更新 apt,在 Ubuntu 中使用 apt 来下载安装软件,如果没更新可能有一些软件安装不了。
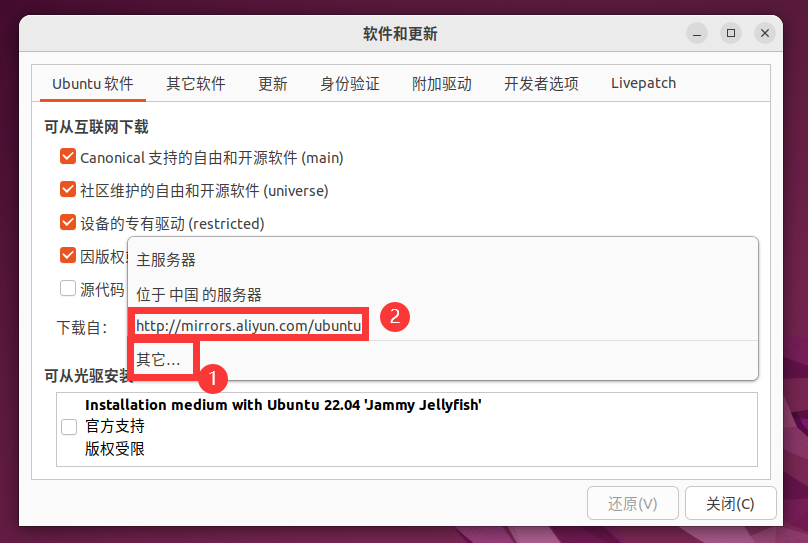
sudo apt-get update按照下图依次点击 ① ②:

选择“其他”然后选择阿里云镜像服务器。这等效于我们平时在 Windows 系统下安装 python 包时使用清华镜像站。
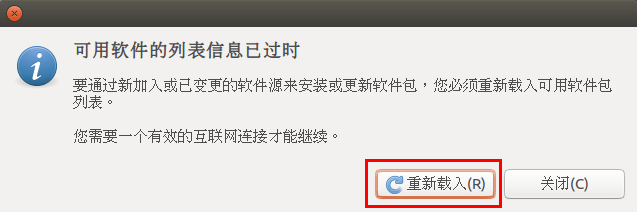
选择关闭后会提醒你信息过时
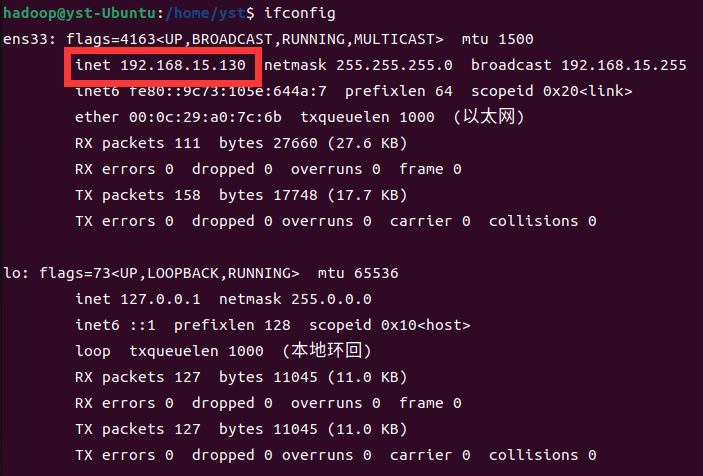
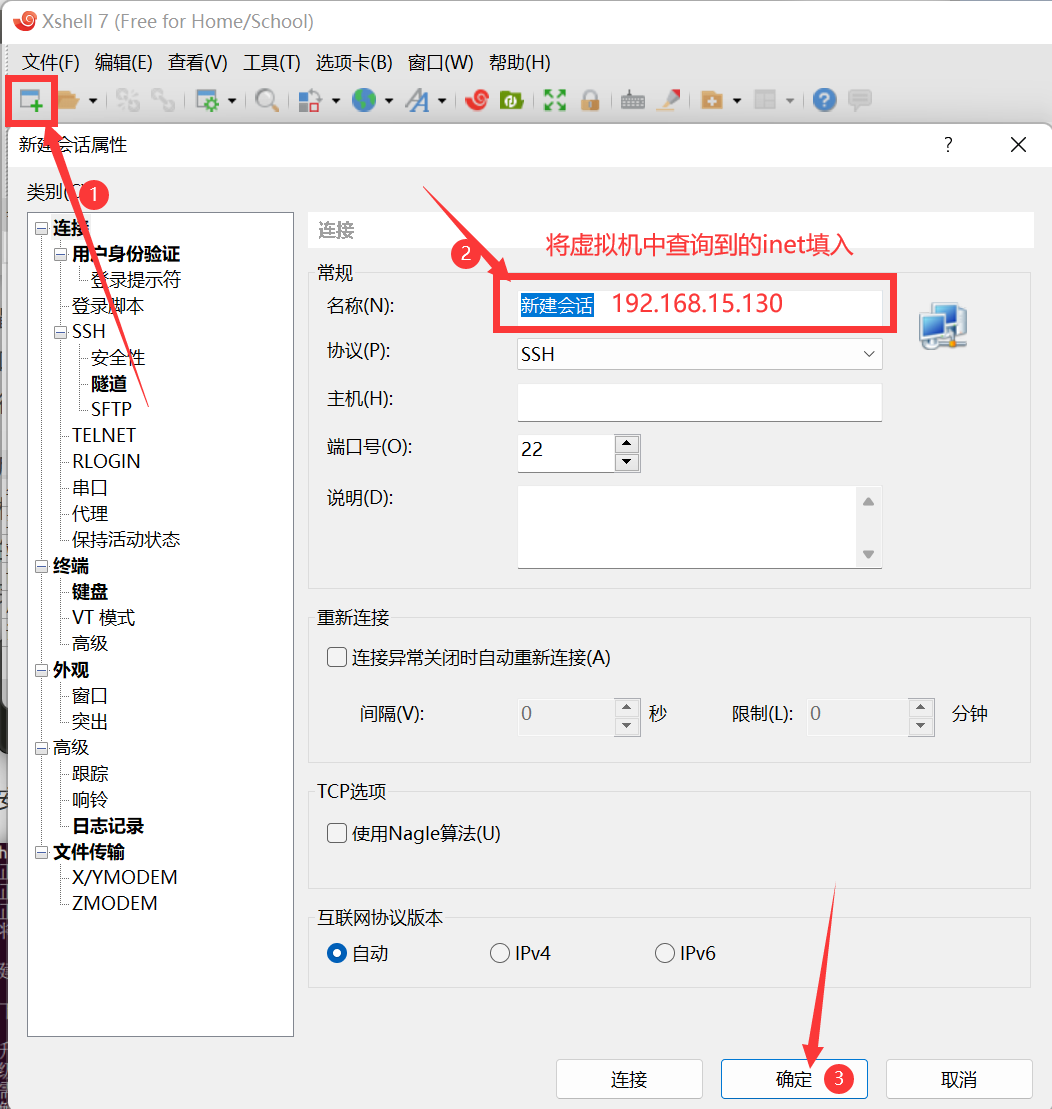
后续操作将不再需要图形化界面,故建议使用 xshell 软件,下面演示一下,如不需要可以直接跳转至Part2。

安装vim,提示时按y即可:
sudo apt-get install vim安装SSH,配置无密码登录:
sudo apt-get install openssh-serverSSH首次登陆提示),输入 yes 。然后按提示输入密码,利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
ssh localhost
exit
cd ~/.ssh/ # 若没有该目录,再执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权此时再用 ssh localhost 命令,无需输入密码就可以直接登录了。
我们需要先将 JDK1.8 (目前企业中主流的 java 版本仍然是 jdk1.8)下载到电脑。
然后将文件上传到 Ubuntu 中,这里我采用的是 rz 的上传方式,需要借用 xshell 工具。
cd ~
sudo mkdir Downloads # 创建 ~/Downloads 目录用来存放下载的文件
cd Downloads # 进入目标目录
rz # 上传文件到 Ubuntu 系统中解压 JDK 文件:
cd /usr/lib
sudo mkdir jvm # 创建/usr/lib/jvm目录用来存放JDK文件
cd ~ # 进入hadoop用户的主目录
cd Downloads
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm # 把JDK文件解压到 /usr/lib/jvm 目录下配置环境变量:
cd ~
vim ~/.bashrc在文件中输入以下内容后,按 Esc 键,输入“:wq”保存并退出
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc验证环境变量是否生效:
java -version如果能够在屏幕上返回如下信息,则说明安装成功:

首先,你需要下载一个 hadoop-3.3.4.tar.gz(这是一个官网链接),当然你也可以下载 3.1.3 的版本,这并没有很大的改变。
然后使用同样的方法将文件上传到 Ubuntu 中。
cd ~/Downloads # 进入目标目录
rz # 上传文件到 Ubuntu 系统中将 Hadoop 安装至 /usr/local/ 中:
sudo tar -zxvf ~/Downloads/hadoop-3.3.4.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.3.4/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限验证 hadoop 是否安装成功:
cd /usr/local/hadoop
bin/hadoop version如果能够在屏幕上返回如下信息,则说明安装成功:

Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改配置文件 core-site.xml
vim etc/hadoop/core-site.xml将原先的<configuration></configuration>改为下面的内容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>修改配置文件 hdfs-site.xml:
vim etc/hadoop/hdfs-site.xml将原先的<configuration></configuration>改为下面的内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
bin/hdfs namenode -format成功格式化返回样例(部分):
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.3.4如果在这一步时提示 Error: JAVA_HOME is not set and could not be found. 的错误,首先你要确定前面关于JDK的环境变量配置文件中没有出现问题。然后,到hadoop的安装目录修改配置文件“/usr/local/hadoop/etc/hadoop/hadoop-env.sh”,在里面找到“export JAVA_HOME=${JAVA_HOME}”这行,然后,把它修改成JAVA安装路径的具体地址,比如,“export JAVA_HOME=/usr/lib/jvm/default-java”,再次启动Hadoop。
接着开启 NameNode 和 DataNode 守护进程:
cd /usr/local/hadoop
sbin/start-all.sh #start-all.sh是个可执行文件,中间没有空格对于伪分布式可以用 start-dfs.sh 启动hadoop,等效于前面的 start-all.sh。
如果启动 Hadoop 时遇到输出非常多“ssh: Could not resolve hostname xxx”的异常情况,可通过设置 Hadoop 环境变量来解决。首先按键盘的 ctrl + c 中断启动,然后在 ~/.bashrc 中,增加如下两行内容(设置过程与 JAVA_HOME 变量一样,其中 HADOOP_HOME 为 Hadoop 的安装目录):
export HADOOP_HOME=/usr/local/hadoop
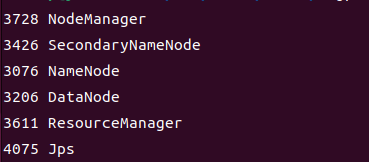
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: "NameNode"、"DataNode" 和 "SecondaryNameNode"(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-all.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤。由于我前面执行的命令为 start-all.sh,所以是下面这个样子。
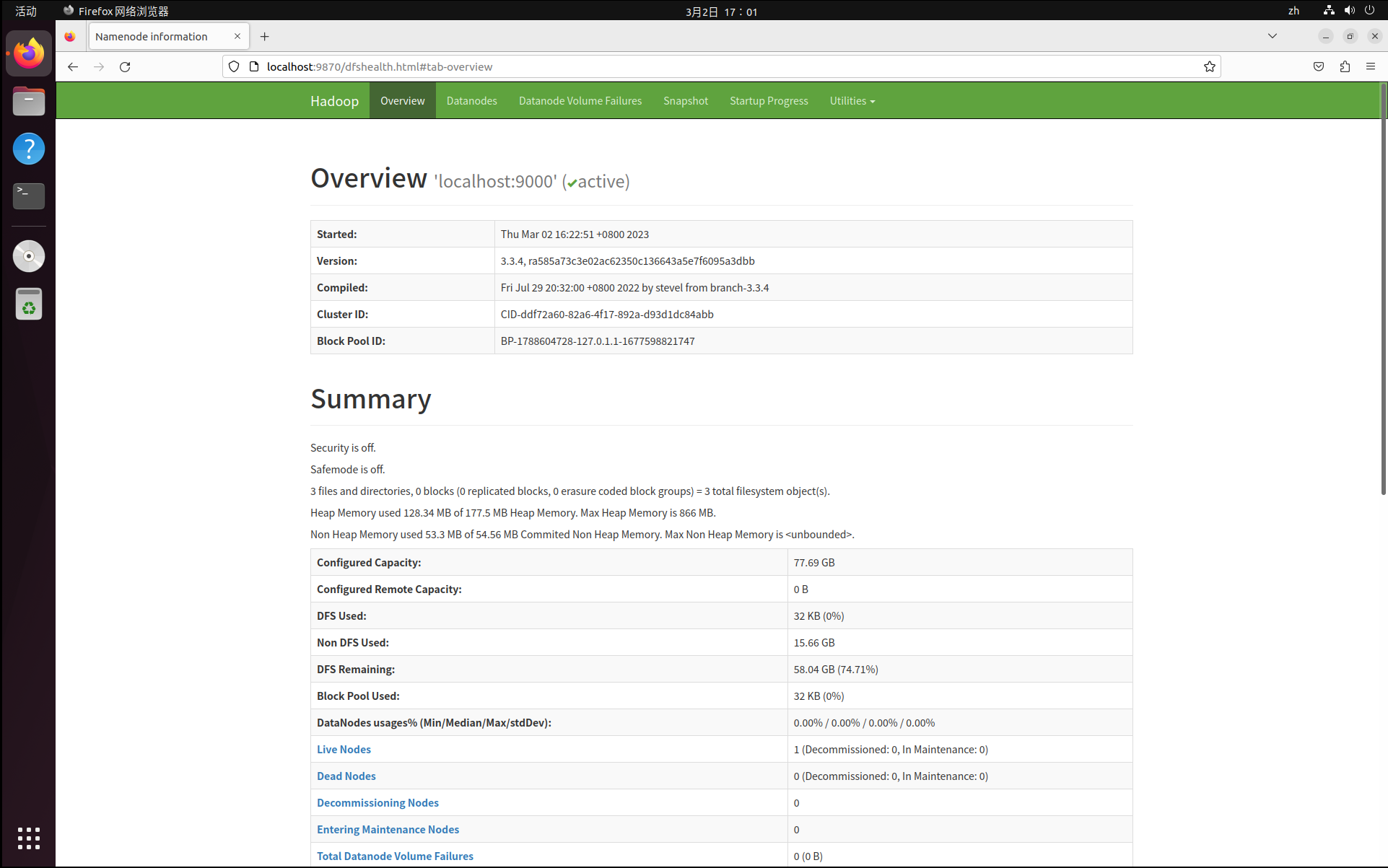
成功启动后,可以访问 Web 界面 http://localhost:9870 (由于hadoop版本不同,可能你需要访问的端口号是50070)以及 http://localhost:8088 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
伪分布式到此就搭建完成啦!
下面会再补充一些报错以及解决方案
(1)若是 DataNode 没有启动,可尝试如下的方法(注意这会删除 HDFS 中原有的所有数据,如果原有的数据很重要请不要这样做)
cd /usr/local/hadoop
sbin/stop-all.sh # 关闭
rm -r ./tmp # 删除 tmp 文件,注意这会删除 HDFS 中原有的所有数据
./bin/hdfs namenode -format # 重新格式化 NameNode
sbin/start-all.sh # 启动
(2)解决 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable警告问题
vim ~/.bashrc
# 添加以下内容
export JAVA_LIBRARY_PATH=/usr/local/hadoop/lib/native然后重新应用环境变量
source ~/.bashrc
(3)当遇到9870端口被占用的问题时,可以通过更改启动时的端口号来实现启动,记得先通过 sbin/stop-dfs.sh 关闭服务,然后更改前面的 core-site.xml 文件,往里面添加以下内容到<configuration></configuration>中间
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>localhost:50090</value>
</property>
(4)无法访问网站,这可能是Linux中的防火墙未关闭的问题:
sudo ufw status # 查看防火墙状态
sudo ufw disable # 关闭防火墙
啊,好累,这篇写了巨久
整理:BDT20040
我试过重新启动apache,缓存的页面仍然出现,所以一定有一个文件夹在某个地方。我没有“公共(public)/缓存”,那么我还应该查看哪些其他地方?是否有一个URL标志也可以触发此效果? 最佳答案 您需要触摸一个文件才能清除phusion,例如:touch/webapps/mycook/tmp/restart.txt参见docs 关于ruby-如何在Ubuntu中清除RubyPhusionPassenger的缓存?,我们在StackOverflow上找到一个类似的问题:
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我正在运行Ubuntu11.10并像这样安装Ruby1.9:$sudoapt-getinstallruby1.9rubygems一切都运行良好,但ri似乎有空文档。ri告诉我文档是空的,我必须安装它们。我执行此操作是因为我读到它会有所帮助:$rdoc--all--ri现在,当我尝试打开任何文档时:$riArrayNothingknownaboutArray我搜索的其他所有内容都是一样的。 最佳答案 这个呢?apt-getinstallri1.8编辑或者试试这个:(非rvm)geminstallrdocrdoc-datardoc-da