kubectl scale rc tomcat --replicas=103. 完成
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install检查安装结果$ aws --versionaws eks --region cn-northwest-1 update-kubeconfig --name my-zhy-eks官方配置方法链接:AWS_REGION=cn-northwest-1
AWS_DEFAULT_REGION=cn-northwest-1
CLUSTER_NAME=my-zhy-eks
eksctl create cluster --name=${CLUSTER_NAME} --version 1.15 --nodes=3 --node-type t3.medium --managed --alb-ingress-access --region=${AWS_REGION}eksctl create cluster --name=${CLUSTER_NAME} --version 1.15 --nodes=3 --node-type t3.medium --managed --alb-ingress-access --region=${AWS_REGION}
[ℹ] eksctl version 0.32.0
[ℹ] using region cn-northwest-1
[ℹ] setting availability zones to [cn-northwest-1b cn-northwest-1c cn-northwest-1a]
[ℹ] subnets for cn-northwest-1b - public:192.168.0.0/19 private:192.168.96.0/19
[ℹ] subnets for cn-northwest-1c - public:192.168.32.0/19 private:192.168.128.0/19
[ℹ] subnets for cn-northwest-1a - public:192.168.64.0/19 private:192.168.160.0/19
[ℹ] using Kubernetes version 1.15
[ℹ] creating EKS cluster "my-zhy-eks" in "cn-northwest-1" region with managed nodes
[ℹ] will create 2 separate CloudFormation stacks for cluster itself and the initial managed nodegroup
[ℹ] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=cn-northwest-1 --cluster=my-zhy-eks'
[ℹ] CloudWatch logging will not be enabled for cluster "my-zhy-eks" in "cn-northwest-1"
[ℹ] you can enable it with 'eksctl utils update-cluster-logging --enable-types={SPECIFY-YOUR-LOG-TYPES-HERE (e.g. all)} --region=cn-northwest-1 --cluster=my-zhy-eks'
[ℹ] Kubernetes API endpoint access will use default of {publicAccess=true, privateAccess=false} for cluster "my-zhy-eks" in "cn-northwest-1"
[ℹ] 2 sequential tasks: { create cluster control plane "my-zhy-eks", 2 sequential sub-tasks: { no tasks, create managed nodegroup "ng-e5146e45" } }
[ℹ] building cluster stack "eksctl-my-zhy-eks-cluster"
[ℹ] deploying stack "eksctl-my-zhy-eks-cluster"
[ℹ] building managed nodegroup stack "eksctl-my-zhy-eks-nodegroup-ng-e5146e45"
[ℹ] deploying stack "eksctl-my-zhy-eks-nodegroup-ng-e5146e45"
[ℹ] waiting for the control plane availability...
[✔] saved kubeconfig as "/root/.kube/config"
[ℹ] no tasks
[✔] all EKS cluster resources for "my-zhy-eks" have been created
[ℹ] nodegroup "ng-e5146e45" has 3 node(s)
[ℹ] node "ip-192-168-5-37.cn-northwest-1.compute.internal" is ready
[ℹ] node "ip-192-168-58-97.cn-northwest-1.compute.internal" is ready
[ℹ] node "ip-192-168-65-234.cn-northwest-1.compute.internal" is ready
[ℹ] waiting for at least 3 node(s) to become ready in "ng-e5146e45"
[ℹ] nodegroup "ng-e5146e45" has 3 node(s)
[ℹ] node "ip-192-168-5-37.cn-northwest-1.compute.internal" is ready
[ℹ] node "ip-192-168-58-97.cn-northwest-1.compute.internal" is ready
[ℹ] node "ip-192-168-65-234.cn-northwest-1.compute.internal" is ready
[ℹ] kubectl command should work with "/root/.kube/config", try 'kubectl get nodes'
[✔] EKS cluster "my-zhy-eks" in "cn-northwest-1" region is ready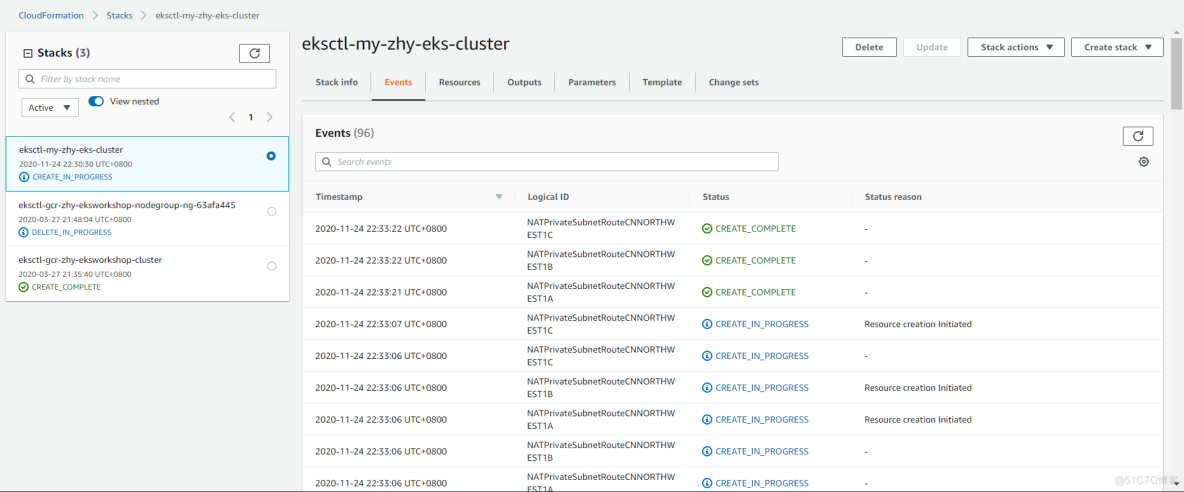

# kubectl get node
NAME STATUS ROLES AGE VERSION
ip-192-168-5-37.cn-northwest-1.compute.internal Ready <none> 11m v1.15.12-eks-31566f
ip-192-168-58-97.cn-northwest-1.compute.internal Ready <none> 11m v1.15.12-eks-31566f
ip-192-168-65-234.cn-northwest-1.compute.internal Ready <none> 11m v1.15.12-eks-31566fNODE_GROUP=$(eksctl get nodegroup --cluster ${CLUSTER_NAME} --region=${AWS_REGION} -o json | jq -r '.[].Name')
eksctl scale nodegroup --cluster=${CLUSTER_NAME} --nodes=10 --name=${NODE_GROUP} --region=${AWS_REGION}检查结果eksctl get nodegroup --cluster ${CLUSTER_NAME} --region=${AWS_REGION}
eksctl get cluster
NAME REGION
my-zhy-eks cn-northwest-14.3. Amazon ECR的使用 针对一个企业,很多image都是定制化的,而定制化的私有image管理,在AWS是如何操作的呢? Amazon ECR,让image的管理,变得更简单易用。下面通过httpd的image,定制化并生成私有httpdok的image之后,并上传到Amazon ECR,作为步骤演示:4.3.1. 首先创建一个Amazon ECR Repositories,选择并点击View push commands.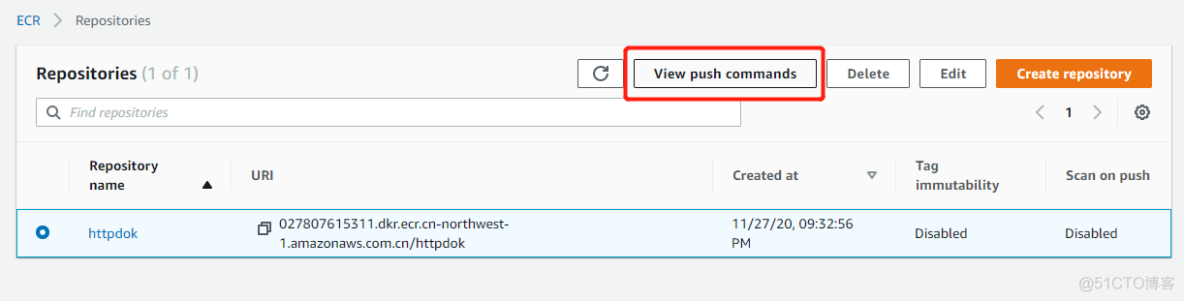 4.3.2. 根据”View puhs commands”步骤,将本地创建好的image,上传到Amazon ECR。
4.3.2. 根据”View puhs commands”步骤,将本地创建好的image,上传到Amazon ECR。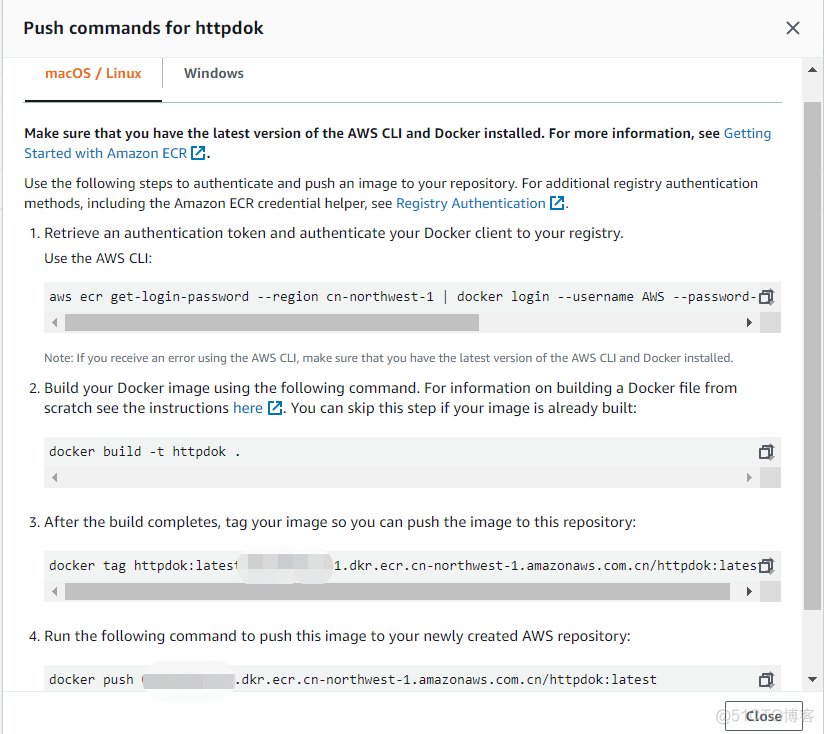 具体命令步骤:
具体命令步骤:# aws ecr get-login-password --region cn-northwest-1 | docker login --username AWS --password-stdin <account_id>.dkr.ecr.cn-northwest-1.amazonaws.com.cn查看本地镜像# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
httpdok v1 df353399ffe4 7 seconds ago 299MB为镜像打标签# docker tag httpdok:latest <account_id>.dkr.ecr.cn-northwest-1.amazonaws.com.cn/httpdok:latest在查看本地Docker的images,可以看到已经出现一个新的,有ECR连接串的image# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
<account_id>.dkr.ecr.cn-northwest-1.amazonaws.com.cn/httpdok latest 9028c4373343 4 minutes ago 299MB
httpdok latest 9028c4373343 4 minutes ago 299MB推送image到ECR上# docker push <account_id>.dkr.ecr.cn-northwest-1.amazonaws.com.cn/httpdok:latest
The push refers to repository [<account_id>.dkr.ecr.cn-northwest-1.amazonaws.com.cn/httpdok]回到aws控制台,已经可以看到上传的image 4.4. Amazon EKS实例演示下面开始部署容器到Amazon EKS中,通过Nginx来演示如何部署image到Amazon EKS,并轮询访问.4.4.1. 启动三个nginx pod 的 ReplicaSet准备yaml文件
4.4. Amazon EKS实例演示下面开始部署容器到Amazon EKS中,通过Nginx来演示如何部署image到Amazon EKS,并轮询访问.4.4.1. 启动三个nginx pod 的 ReplicaSet准备yaml文件cat <<EOF > nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
EOF执行以下命令,进行部署kubectl apply -f nginx-deployment.yaml检查创建状态kubectl get pods -o widecat <<EOF > loadbalancer.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: LoadBalancer
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
EOF执行以下命令,进行部署kubectl create -f loadbalancer.yamlkubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-service LoadBalancer 10.100.212.244 ae8e75d7e149044eb905b6bbff796e7e-629951941.cn-northwest-1.elb.amazonaws.com.cn 80:31248/TCP 7m53scurl -silent ae8e75d7e149044eb905b6bbff796e7e-629951941.cn-northwest-1.elb.amazonaws.com.cn | grep title
<title>Welcome to nginx!</title>kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-574b87c764-92jbs 1/1 Running 0 10h
nginx-deployment-574b87c764-hmz9t 1/1 Running 0 10h
nginx-deployment-574b87c764-nqpmc 1/1 Running 0 10hkubectl exec -it nginx-deployment-574b87c764-92jbs -- /usr/sbin/nginx -t
kubectl exec -it nginx-deployment-574b87c764-92jbs -- cat /etc/nginx/nginx.conf
kubectl exec -it nginx-deployment-574b87c764-92jbs -- ls /usr/share/nginx/html
kubectl exec -it nginx-deployment-574b87c764-92jbs -- cat /usr/share/nginx/html/index.html
kubectl exec -it nginx-deployment-574b87c764-92jbs -- cp/usr/share/nginx/html/index.html /usr/share/nginx/html/index.html.bk注释:kubectl exce的格式如下:kubectl exec -it <podName> -c <containerName> -n <namespace> -- shell comandkubectl cp name.html nginx-deployment-574b87c764-nqpmc:usr/share/nginx/html/index.html注释: pod和本地之间传输文件命令格式kubectl cp -n NAMESPACE_name POD_name:Pod_FILE_name Local_FILE_name本地上传文件到Podkubectl cp Local_FILE_name -n NAMESPACE_name POD_name:Pod_FILE_name最终查询输出结果,多次查询,可以看到load balance会将连接随机分配到不同Pod节点curl -silent ae8e75d7e149044eb905b6bbff796e7e-629951941.cn-northwest-1.elb.amazonaws.com.cn | grep Node输出结果如下: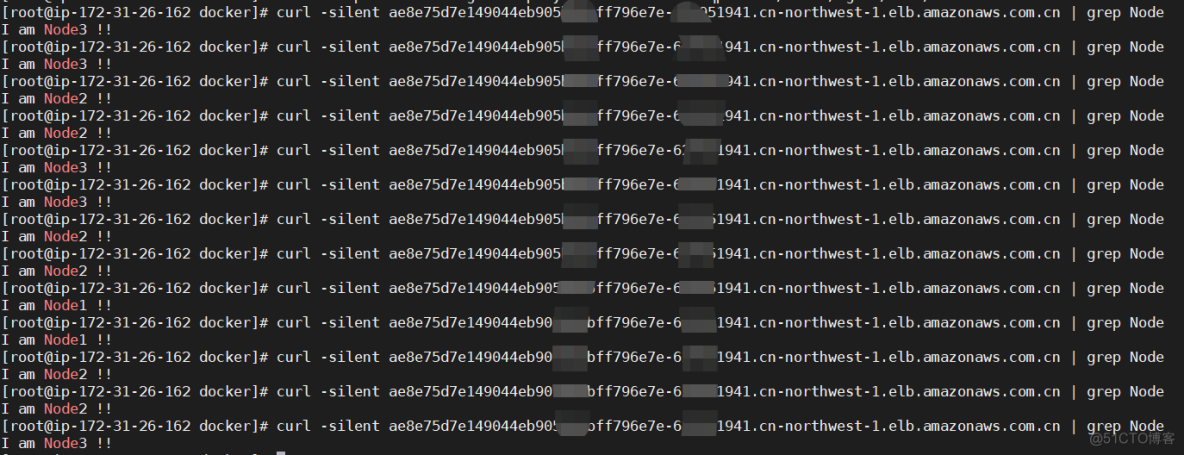 5. 总结
5. 总结 参考文档:
参考文档:很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
参见下面的示例,我想最好使用第二种方法,但第一种也可以。哪种方法最好,使用另一种的后果是什么?classTestdefstartp"started"endtest=Test.newtest.startendclassTest2defstartp"started"endendtest2=Test2.newtest2.start 最佳答案 我肯定会说第二种变体更有意义。第一个不会导致错误,但对象实例化完全过时且毫无意义。外部变量在类的范围内不可见:var="string"classAvar=A.newendputsvar#=>strin
如果我构建了一个应用程序来访问来自Gmail、Twitter和Facebook的一些数据,并且我希望用户只需输入一次他们的身份验证信息,并且在几天或几周后重置,那会怎样是在Ruby中动态执行此操作的最佳方法吗?我看到很多人只是拥有他们客户/用户凭证的配置文件,如下所示:gmail_account:username:myClientpassword:myClientsPassword这看起来a)非常不安全,b)如果我想为成千上万的用户存储此类信息,它就无法工作。推荐的方法是什么?我希望能够在这些服务之上构建一个界面,因此每次用户进行交易时都必须输入凭据是不可行的。
我正在使用Devise在Rails应用程序中,并希望通过API公开一些模型数据,但应该像应用程序一样限制对API的访问。$curlhttp://myapp.com/api/v1/sales/7.json{"error":"Youneedtosigninorsignupbeforecontinuing."}很明显。在这种情况下是否有访问API的最佳实践?我更喜欢一步验证+获取数据,但这只是为了让客户的工作更轻松。他们将使用JQuery在客户端提取数据。感谢您提供任何信息!凡妮莎 最佳答案 我建议您按照以下帖子中的选项2:使用APIke
我正在开发一个Rails2.3.1网站。在整个网站中,我需要一个用于在各种页面(主页、创建帖子页面、帖子列表页面、评论列表页面等)上创建帖子的表单——只要说这个表单需要在由各种Controller)。这些页面中的每一个都显示在相应的Controller/操作中检索到的各种其他信息。例如,主页列出了最新的10篇文章、从数据库中提取的内容等。因此,我已将帖子创建表单移动到它自己的部分中,并将该部分包含在所有必要的页面中。请注意,部分POST中的表单到/questions(路由到PostsController::create——这是默认的Rails行为)。我遇到的问题是当Posts表单没有正
我正在按照我一直在研究的研讨会实现“服务对象”,我正在构建一个redditAPI应用程序。我需要对象返回一些东西,所以我不能只执行初始化程序中的所有内容。我有这两个选择:选项1:类需要实例化classSubListFromUserdefuser_subscribed_subs(client)@client=client@subreddits=sort_subs_by_name(user_subs_from_reddit)endprivatedefsort_subs_by_name(subreddits)subreddits.sort_by{|sr|sr[:name].downcase}
🎉精彩专栏推荐💭文末获取联系✍️作者简介:一个热爱把逻辑思维转变为代码的技术博主💂作者主页:【主页——🚀获取更多优质源码】🎓web前端期末大作业:【📚毕设项目精品实战案例(1000套)】🧡程序员有趣的告白方式:【💌HTML七夕情人节表白网页制作(110套)】🌎超炫酷的Echarts大屏可视化源码:【🔰Echarts大屏展示大数据平台可视化(150套)】🔖HTML+CSS+JS实例代码:【🗂️5000套HTML+CSS+JS实例代码(炫酷代码)继续更新中…】🎁免费且实用的WEB前端学习指南:【📂web前端零基础到高级学习视频教程120G干货分享】🥇关于作者:💬历任研发工程师,技术组长,教学总监;