单链表是多个节点通过指针串联起来的线性结构,每个节点分为两部分,一个是数据域,一个为指针域,头节点的数据域为空,最后一个节点的指针域胃为空,链表的前一个节点的指针域,存放的是下一个节点的地址。
头节点的作用:为了方便操作整个链表,它并不保存具有实际意义的数据。

(1) 构建节点
计算机中没有现成的节点,我们需要自己创建它。任意的节点都包含了两部分:左边部分data存储数据,右边部分next存储指针,就是下一个节点的地址。

data中可以存放任意数据,包括int,float,double等,可以存放单个数据,也尅存放多个数据。
例子
构建一个学生节点,存放学生的name和age
struct node
{
int age;
string name;
}
链表的节点除了数据域,还有指针域next,其中next存放下个节点的地址,下个节点的类型为struct node ,因此指针next 的数据类型为struct node *.
struct node
{
int age; //data域
string name; //data域
struct node * next; //存放下个节点的地址
}
节点名称struct node名字太长了,可以用typedef定义一个新的名字。
typedef struct node
{
int age;
string name;
struct node* next;
} student;
(2) 生成头结点
头节点如何生成呢?在c++中,通过new来生成的,因为new可以动态分配堆内的内存,自己可以指定大小。创建头节点head如下。
student* head=new student;
new student表示在堆上开辟一块大小为sizeof(student)的内存空间,然后把地址赋值给head变量。
(3) 生成普通节点
假设生成2个普通节点p1,p2按照生成head节点的方法,生成子节点也可以用类似的方法。
student* p1=new student; //开辟一块sizeof(student)的内存,并将地址赋给p1
student* p2=new student; //开辟一块sizeof(student)的内存,并将地址赋给p2
但如果生成n=1000个节点,就需要借助for循环来生成节点。
for (int i=0;i<n;i++)
{
student* p =new student;
p->next=NULL;
}
(4) 向节点写入数据
当前只是给每个节点分配了内存,但每个节点内没有数据。通过cin的方式给每个节点写入数据。
for (int i=0;i<n;i++)
{
student* p =new student;
p->next=NULL;
cin>>p->name>>p->age;
}
(5) 构建节点关系
现在构建了节点,也给每个节点分配了数据。但各个节点还是独立的,并没有关系,并没有上个节点的next存放了下个节点的地址。上个节点next存放了下个节点的关系,就可以从当前节点找到下个节点,所以我们说各个节点是连着的,这样才能称为一个链表。
怎么构建节点关系呢?
这个关系就是:上个节点的next指针存放下个节点的地址。假设上个节点我们称为pre,下个节点为p ,根据构建节点关系,就有:
pre->next =p
这样就可以把两个节点的关系构建出来了。
假设有三个节点p1~p3,p2的它的pre是p1,p3的pre是p2,也就是说随着节点的移动,他们的上一个节点pre是动态变化的,因此每次需要更新pre的值,对于下个节点的pre就是当前节点。
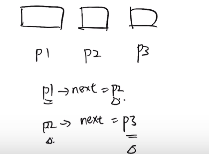
//构建节点关系
pre->next = p;
//pre 跳到下一个节点位置
pre = p;
#include<iostream>
using namespace std;
//1.构造节点
typedef struct node
{
int age;
string name;
struct node* next; // 当前类型的指针,存放下一个节点的地址
}student;
//创建一个长度为n的链表
student* createlist(int n)
{
//2.生成头节点
student* head = new student;
student* pre = head; //最开始的pre指向head头节点
for (int i = 0; i < n; i++)
{
//3.生成普通节点
student* p = new student;
//4.输入数据
cout << "请输入第" << i + 1 << "个数据" << endl;
p->next = NULL;
cin >> p->name >> p->age;
//5.构建节点关系
pre->next = p;
//pre 跳到下一个节点位置
pre = p;
}
return head;
}
void printlist(student* head,int n)
{
student* p = head->next;//第一次p 指向p1 第二次p指向p2 ...
for (int i = 0; i<n; i++)
{
cout << p->name << p->age << endl;;
p = p->next; //移到下一个节点
}
}
int main()
{
int n = 3;
student* head = createlist(n);
printlist(head, n);
system("pause");
return 0;
}
//求链表的长度
int length(student* head) {
int len = 0;
student* p = head;
while (p->next != NULL) { //从第0个结点(头结点)开始,故这里判断条件为 p->next!=NULL
p = p->next;
len++;
}
return len;
}
获取链表第i个数据的算法思路:
head节点,确定是哪个链表,然后查找对应的第i个元素。void findelement(),两个参数head和i作为形参,头节点head的类型为student*,因此函数为void findelement(student* head,int i)算法的 步骤:
p指向链表的第一个节点,初始化j从1开始int j=1 //表示节点j=1的时候,p的地址和p1是一样的
student* p =head->next; //head->next指向的是第一个节点
j<i时,遍历链表,让p的指针向后移动,不断指向下一个节点,j累加1通过循环,让p分别指向p1,p2,..p_i的地址,通过p=p->next实现指向下个节点,当j=i时,输出找到节点p_i对应的数据。
while (j<i) //通过while循环遍历链表
{
p=p->next; //每循环一次p指向链表的下一个节点
j++;
}
if(j==i) //当j=i时,输出找到节点p_i对应的数据
{
cout << p->name<<p->age<<endl;
}
student* findelement(student* head, int i)
{
if (i < 1) {
return NULL;
}
if (i == 0) {
return head;
}
// j=1,p=p1;j=2,p=p2...
int j = 1;
student* p = head->next; //p1
while (j < i && p!=NULL)
{
p = p->next;
j++;
}
//cout<<"---查找节点的数据为---" <<endl;
//cout <<p->name <<p->age;
return p;
}
另外链表也可以按值查找
//按值查找
//找到数据域==e 的结点 平均时间复杂度O(n)
student* LocateElem(studet* head, int value) {
student* p = head->next;
//从第一个结点(不是第0的头结点)开始,查找数据域为e的结点
while (p != NULL && p->data != value) {
p = p->next;
}
return p;
}
假设在节点p,s之间插入节点q.
原来的节点关系为:
p->next=s
p,s之间插入节点q就变为:
//注意顺序不用弄乱了
p->next=q;
q->next=s;

插入的是哪个链表,可以通过获得该链表的head确定
void insertnode(student* head,int i)student* q=new student; //创建一个空的节点,分配内存空间
cin >> q->name>>q->age;
在第i个节点插入,首先需要找到第i个节点,通过findelement方法找到第i个节点
void insertNode(student* head,int i)
{
if (i < 1)
{
cout << "您所插入的位置不存在" << endl;
exit(0);
}
//往链表L的第i个节点后面插入:链表L通过head节点确认
//查找第i个节点
student* p=findelement(head,i);
//创建要插入的节点
student* q=new student;
cout <<"请输入要插入的节点数据:name age" <<endl;
cin>>q->name>>q->age;
// s=p->next
// 插入节点q后 q->next=s 相当于q->next=p->next
q->next=p->next;
p->next=q;
}
把链表L的第i个节点删除 如何实现呢
void deleteNode(student * head,int i)p1,p2,p3 ,删除节点p2,可通过如下实现:
p1,p2,p3的关系是:
p1->next=p2
p2->next=p3
删除节点p2,可表示为如下:
p1->next=p3
因此要删除第i个节点,就需要把该节点前一个节点i-1找到, 通过函数findelement(head,i-1)找到节点p1
p2表示为: student* p2=p1->next ,删除节点p2的话就是将p1->next由指向p2,变为p1->next指向p2->next。虽然p2在链表中不参与了,但p2还存在,因此需要通过delete p2 从内存中删除。代码如下:student* p2=p1->next
p1->next=p2->next
delete p2 //彻底删除
void deleteNode(student* head,int i)
{
//删除第i个节点 需要先找到第i-1个节点
student* p1=findelement(head,i-1);
student* p2=p1->next;
student* p3=p2->next;
//链表中删除p2
p1->next=p3;
delete p2;
cout<<"删除成功!"<<endl;
}
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
我对最新版本的Rails有疑问。我创建了一个新应用程序(railsnewMyProject),但我没有脚本/生成,只有脚本/rails,当我输入ruby./script/railsgeneratepluginmy_plugin"Couldnotfindgeneratorplugin.".你知道如何生成插件模板吗?没有这个命令可以创建插件吗?PS:我正在使用Rails3.2.1和ruby1.8.7[universal-darwin11.0] 最佳答案 随着Rails3.2.0的发布,插件生成器已经被移除。查看变更日志here.现在
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or