mybatis的核心配置文件(mybatis-config.xml),它的作用如配置jdbc连接信息,注册mapper等,我们需要对这个配置文件有详细的了解。
配置文档的顶层结构如下:

属性可以在外部进行配置,并可以进行动态替换(使用${})。既可以在典型的 Java 属性文件中配置这些属性,也可以在 properties 元素的子元素中设置。
(1)直接在properties元素的子元素中配置
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://127.0.0.1:3306/mybatis?
useSSL=true&useUnicode=true&characterEncoding=UTF-8"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
(2)在外部配置,进行动态替换
jdbc.properties 属性文件:
.properties 属性文件需要统一放在 resource 目录/类加载路径
# The key value is arbitrary
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://127.0.0.1:3306/mybatis?useSSL=true&useUnicode=true&characterEncoding=UTF-8
jdbc.user=root
jdbc.pwd=123456
mybatis 配置文件:
要先引入 .properties 文件
<configuration>
<!--引入外部的jdbc.properties-->
<properties resource="jdbc.properties"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.user}"/>
<property name="password" value="${jdbc.pwd}"/>
</dataSource>
</configuration>
<typeAliases>
<!--如果一个包下有很多的类,可以直接使用包的方式引入,这样包下的所有类名都可以直接使用-->
<package name="com.li.entity"/>
</typeAliases>
environments 元素定义了如何配置环境。
注意一些关键点:
默认环境和环境 ID 顾名思义。 环境可以随意命名,但务必保证默认的环境 ID 要匹配其中一个环境 ID。
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">
<property name="..." value="..."/>
</transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
现在就要来定义 SQL 映射语句了。 首先,我们需要告诉 MyBatis 到哪里去找到这些语句。你可以使用相对于类路径的资源引用,或完全限定资源定位符(包括 file:/// 形式的 URL),或类名和包名等。
(1)使用相对于类路基的资源引用
<!-- 使用相对于类路径的资源引用 -->
<mappers>
<mapper resource="org/mybatis/builder/AuthorMapper.xml"/>
<mapper resource="org/mybatis/builder/BlogMapper.xml"/>
<mapper resource="org/mybatis/builder/PostMapper.xml"/>
</mappers>
(2)使用完全限定资源定位符(URL),不推荐使用
<!-- 使用完全限定资源定位符(URL) -->
<mappers>
<mapper url="file:///var/mappers/AuthorMapper.xml"/>
<mapper url="file:///var/mappers/BlogMapper.xml"/>
<mapper url="file:///var/mappers/PostMapper.xml"/>
</mappers>
(3)使用映射器接口实现类的完全限定类名
<!-- 使用映射器接口实现类的完全限定类名 -->
<mappers>
<mapper class="org.mybatis.builder.AuthorMapper"/>
<mapper class="org.mybatis.builder.BlogMapper"/>
<mapper class="org.mybatis.builder.PostMapper"/>
</mappers>
(4)将包内的映射器接口全部注册为映射器
<!-- 将包内的映射器接口全部注册为映射器
1.当一个包下有很多的xxMapper.xml文件和基于注解实现的接口时,为了方便,可以用包方式进行引用
2.将下面的所有xml文件和注解接口都进行注册-->
<mappers>
<package name="org.mybatis.builder"/>
</mappers>
Mybatis 的真正强大之处在于它的语句映射(在XxxMapper.xml中配置),如果拿它和具有相同功能的 JDBC代码进行对比,你会发现立即省掉了将近 95% 的代码。MyBatis 致力于减少使用成本,让用户能更专注于SQL 代码。
SQL映射文件常用的顶级元素(按照应被定义的顺序列出):
cache - 该命名空间的缓存配置
cache-ref - 引用其他命名空间的缓存配置
resultMap - 描述如何从数据库的结果集 中加载对象,是最复杂也是最强大的元素
parameterType - 将会传入这条语句的参数的类全限定名或别名
sql - 可被其他语句引用的可重用语句块
insert - 映射插入语句
update - 映射更新语句
delete - 映射删除语句
select - 映射查询语句
insert,delete,update,select 这些在之前讲过,分别对应增删查改的方法和SQL语句的映射
如果获取到刚刚添加的Monster对象的id主键(获取自增长)也讲过了
<insert id="addMonster" parameterType="Monster" useGeneratedKeys="true" keyProperty="id">
INSERT INTO `monster`
(`age`,`birthday`,`email`,`gender`,`name`,`salary`)
VALUES (#{age},#{birthday},#{email},#{gender},#{name},#{salary})
</insert>
#{}的方式来获取入参的多个值(注意#{}内部的名称对应的是POJO对象的属性名,和表字段无关)${}的方式来接收传入的参数应用案例
(1)MonsterMapper.java 接口
package com.li.mapper;
import com.li.entity.Monster;
import java.util.List;
/**
* @author 李
* @version 1.0
*/
public interface MonsterMapper {
//通过id或者名字查询
public List<Monster> findMonsterByNameOrId(Monster monster);
//查询名字中含有‘精’的妖怪
public List<Monster> findMonsterByName(String name);
}
(2)映射文件MonsterMapper.xml 实现接口方法
<mapper namespace="com.li.mapper.MonsterMapper">
<!--这里 #{}的值是从传入的参数的属性中获取的,`id`表示表的字段名,
这里的parameterType可以直接使用类名,是因为在mybatis的配置文件中配置了别名-->
<select id="findMonsterByNameOrId" parameterType="Monster" resultType="Monster">
SELECT * FROM `monster` WHERE `id` = #{id} OR `name` = #{name}
</select>
<!--当传入的参数类型为String时,使用${}的方式来接收参数-->
<select id="findMonsterByName" parameterType="String" resultType="Monster">
SELECT * FROM `monster` WHERE `name` LIKE '%${name}%'
</select>
</mapper>
(3)测试
package com.li.mapper;
import com.li.entity.Monster;
import com.li.util.MybatisUtils;
import org.apache.ibatis.session.SqlSession;
import org.junit.Before;
import org.junit.Test;
import java.util.List;
/**
* @author 李
* @version 1.0
*/
public class MonsterMapperTest {
//属性
private SqlSession sqlSession;
private MonsterMapper monsterMapper;
//初始化
@Before
public void init() {
sqlSession = MybatisUtils.getSqlSession();
monsterMapper = sqlSession.getMapper(MonsterMapper.class);
System.out.println("monsterMapper=" + monsterMapper.getClass());
}
@Test
public void findMonsterByNameOrId() {
Monster monster = new Monster();
monster.setId(1);
monster.setName("狐狸精");
List<Monster> monsters =
monsterMapper.findMonsterByNameOrId(monster);
for (Monster m : monsters) {
System.out.println("m=" + m);
}
if (sqlSession != null) {
sqlSession.close();
}
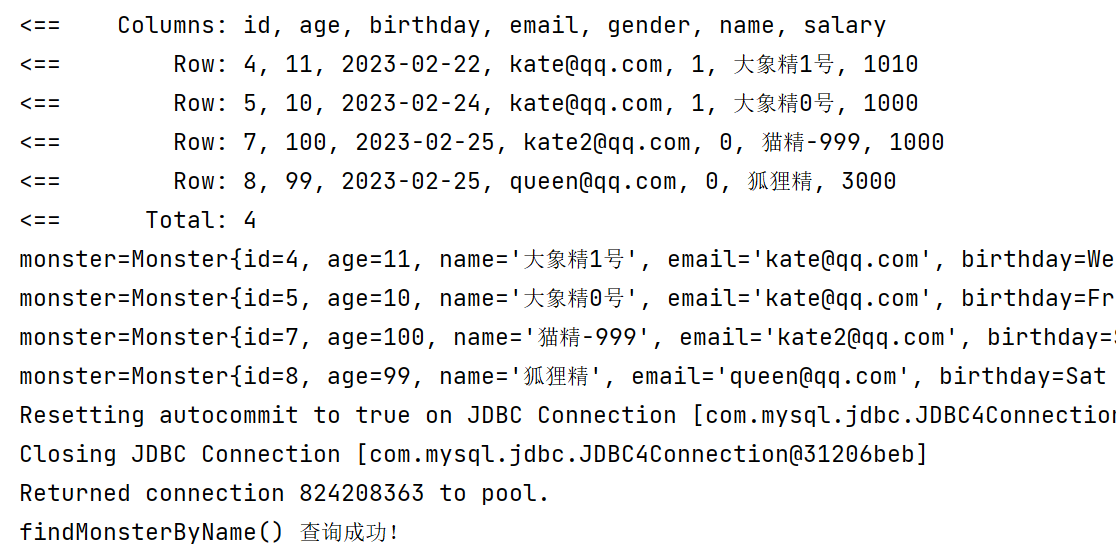
System.out.println("findMonsterByNameOrId() 查询成功!");
}
@Test
public void findMonsterByName() {
List<Monster> monsters = monsterMapper.findMonsterByName("精");
for (Monster monster : monsters) {
System.out.println("monster=" + monster);
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("findMonsterByName() 查询成功!");
}
}

HashMap传入参数更加灵活,比如可以灵活地增加查询的属性,而不受POJO/Entity 类型本身属性的限制(因为POJO/Entity 类型的属性数量有限而且#{}中的名称必须为属性名)
例子-演示如何遍历一个List<Map<String,Object>> 的数据类型
(1)修改MonsterMapper.java,增加方法接口
//声明一个方法,传入参数是HashMap,查询 id>10 并且 salary>40 的所有妖怪
public List<Monster> findMonsterByIdAndSalary(Map<String, Object> map);
(2)修改MonsterMapper.xml映射文件,实现该方法
<!--声明一个方法,传入参数是HashMap,查询 id>5 并且 salary>40 的所有妖怪
这里使用 #{id}和 #{salary} 来获取入参 map的值时,意味着你的map需要有key为id和salary的键值对
事实上,map的 key 只要和 #{}中的 key一样即可,和表字段无关-->
<select id="findMonsterByIdAndSalary" parameterType="map" resultType="Monster">
SELECT * FROM `monster` WHERE `id`>#{id} AND `salary` > #{salary}
</select>
(3)测试
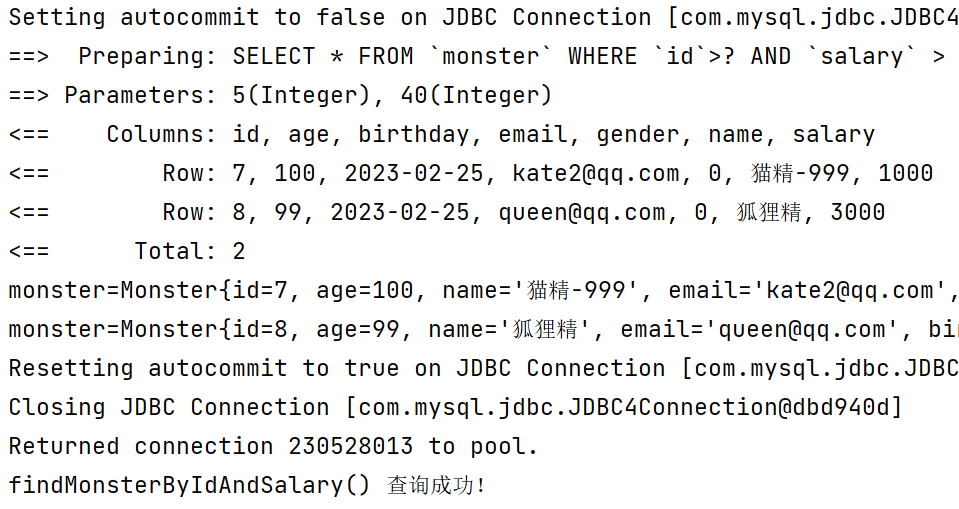
@Test
public void findMonsterByIdAndSalary() {
Map<String, Object> map = new HashMap<>();
map.put("id", 5);//这里设置的key只要和#{key}的key值一样即可,和表字段无关
map.put("salary", 40);
List<Monster> monsters = monsterMapper.findMonsterByIdAndSalary(map);
for (Monster monster : monsters) {
System.out.println("monster=" + monster);
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("findMonsterByIdAndSalary() 查询成功!");
}
(1)修改MonsterMapper.java,增加方法接口
//传入和返回的类型都是Map
public List<Map<String, Object>> findMonsterByIdAndSalary2(Map<String, Object> map);
(2)修改MonsterMapper.xml映射文件,实现该方法
<!--查询 id>5 并且 salary>40 的所有妖怪,要求传入和返回的参数都是Map类型-->
<select id="findMonsterByIdAndSalary2" parameterType="map" resultType="map">
SELECT * FROM `monster` WHERE `id`>#{id} AND `salary` > #{salary}
</select>
(3)测试
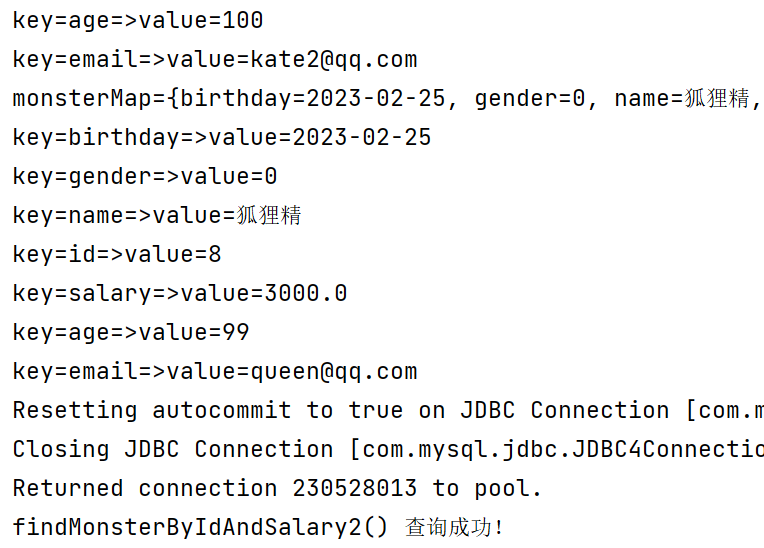
@Test
public void findMonsterByIdAndSalary2() {
Map<String, Object> map = new HashMap<>();
map.put("id", 5);
map.put("salary", 40);
List<Map<String, Object>> monstersList = monsterMapper.findMonsterByIdAndSalary2(map);
//取出返回的结果-以map的形式
for (Map<String, Object> monsterMap : monstersList) {
System.out.println("monsterMap=" + monsterMap);
//遍历monsterMap,取出属性和对应的值
for (Map.Entry<String, Object> entry : monsterMap.entrySet()) {
System.out.println("key=" + entry.getKey() + "=>value=" + entry.getValue());
}
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("findMonsterByIdAndSalary2() 查询成功!");
}
当实体类属性和表的字段名字不一样时,我们可以通过resultMap进行映射,从而屏蔽实体类属性名和表的字段不一致可能出现的问题。
例子
(1)表user
-- 创建user表
CREATE TABLE `user`(
`user_id` INT NOT NULL AUTO_INCREMENT,
`user_email` VARCHAR(255) DEFAULT '',
`user_name` VARCHAR(255) DEFAULT '',
PRIMARY KEY(`user_id`)
)CHARSET=utf8
(2)创建实体类和表映射,这里故意设置和表字段不一样的属性名
package com.li.entity;
/**
* @author 李
* @version 1.0
*/
public class User {
private Integer userId;
private String userName;
private String userEmail;
public Integer getUserId() {
return userId;
}
public void setUserId(Integer userId) {
this.userId = userId;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getUserEmail() {
return userEmail;
}
public void setUserEmail(String userEmail) {
this.userEmail = userEmail;
}
@Override
public String toString() {
return "User{" +
"userId=" + userId +
", userName='" + userName + '\'' +
", userEmail='" + userEmail + '\'' +
'}';
}
}
(3)创建接口 UserMapper.java
package com.li.mapper;
import com.li.entity.User;
import java.util.List;
/**
* @author 李
* @version 1.0
*/
public interface UserMapper {
//添加
public void addUser(User user);
//查询所有的User
public List<User> findAllUsers();
}
(4)创建映射文件 UserMapper.xm
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace指定该xml文件和哪个接口对应-->
<mapper namespace="com.li.mapper.UserMapper">
<!--完成添加用户的任务,注意这里的user属性和表的字段名不一致
这里的parameterType可以直接使用类名,是因为在mybatis的配置文件中配置了别名-->
<insert id="addUser" parameterType="User">
INSERT INTO `user`(`user_email`,`user_name`)
VALUE(#{userEmail},#{userName});
</insert>
<!--因为表字段的名称和实体类型的名称不一致
1.如果对象属性名和表字段不一样是,那么返回的数据就保存不进去,就会是对象的属性就是默认值
2.要解决这个问题,可以使用resultMap来解决这个问题
3.定义一个resultMap,它的id由你指定id,通过id可以引用这个resultMap
4.type 为返回的数据类型(可以使用别名)
5.column为表的字段,property为对象的属性名-->
<resultMap id="findAllUserMap" type="User">
<!--指定映射关系-->
<result column="user_email" property="userEmail"/>
<result column="user_name" property="userName"/>
</resultMap>
<select id="findAllUsers" resultMap="findAllUserMap">
SELECT * FROM `user`
</select>
</mapper>
(5)测试
package com.li.mapper;
import com.li.entity.User;
import com.li.util.MybatisUtils;
import org.apache.ibatis.session.SqlSession;
import org.junit.Before;
import org.junit.Test;
import java.util.List;
/**
* @author 李
* @version 1.0
*/
public class UserMapperTest {
//属性
private SqlSession sqlSession;
private UserMapper userMapper;
//初始化
@Before
public void init() {
sqlSession = MybatisUtils.getSqlSession();
userMapper = sqlSession.getMapper(UserMapper.class);
}
@Test
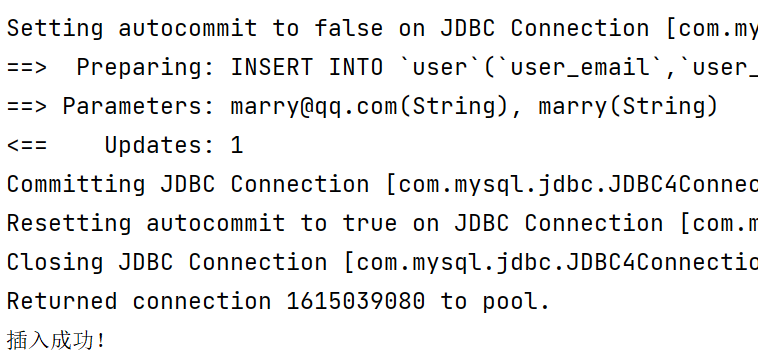
public void addUser(){
User user = new User();
user.setUserName("marry");
user.setUserEmail("marry@qq.com");
userMapper.addUser(user);
if (sqlSession != null) {
//需要手动提交事务,因为mybatis事务默认为false
sqlSession.commit();
sqlSession.close();
}
System.out.println("插入成功!");
}
@Test
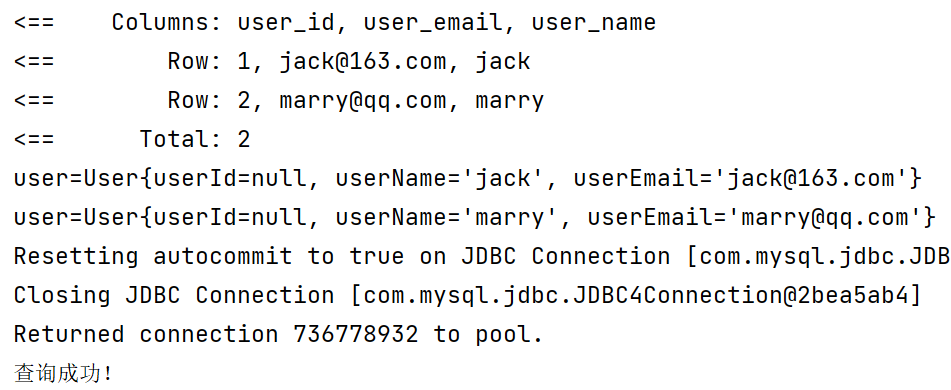
public void findAllUsers(){
List<User> allUsers = userMapper.findAllUsers();
for (User user : allUsers) {
System.out.println("user="+user);
}
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("查询成功!");
}
}
resultMap注意事项和细节
除了使用resultMap,也可以使用字段别名解决表字段和对象属性不一致的问题,但是它的复用性不好,因此不推荐使用字段别名

如果是MyBatis-Plus处理就比较简单,可以使用@TableField来解决实体字段名和表字段名不一致的问题,还可以使用@TableName来解决实体类名和表名不一致的问题。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只