kafka 消费者对象 - KafkaConsumer是非线程安全的。与KafkaProducer不同,KafkaProducer是线程安全的,因为开发者可以在多个线程中放心地使用同一个KafkaProducer实例。
但是对于消费者而言,由于它是非线程安全的,因此用户无法直接在多个线程中直接共享同一个KafkaConsumer实例。对应kafka 多线程消费给出两种解决方案:
每个线程维护一个KafkaConsumer,每个KafkaConsumer消费一个topic分区
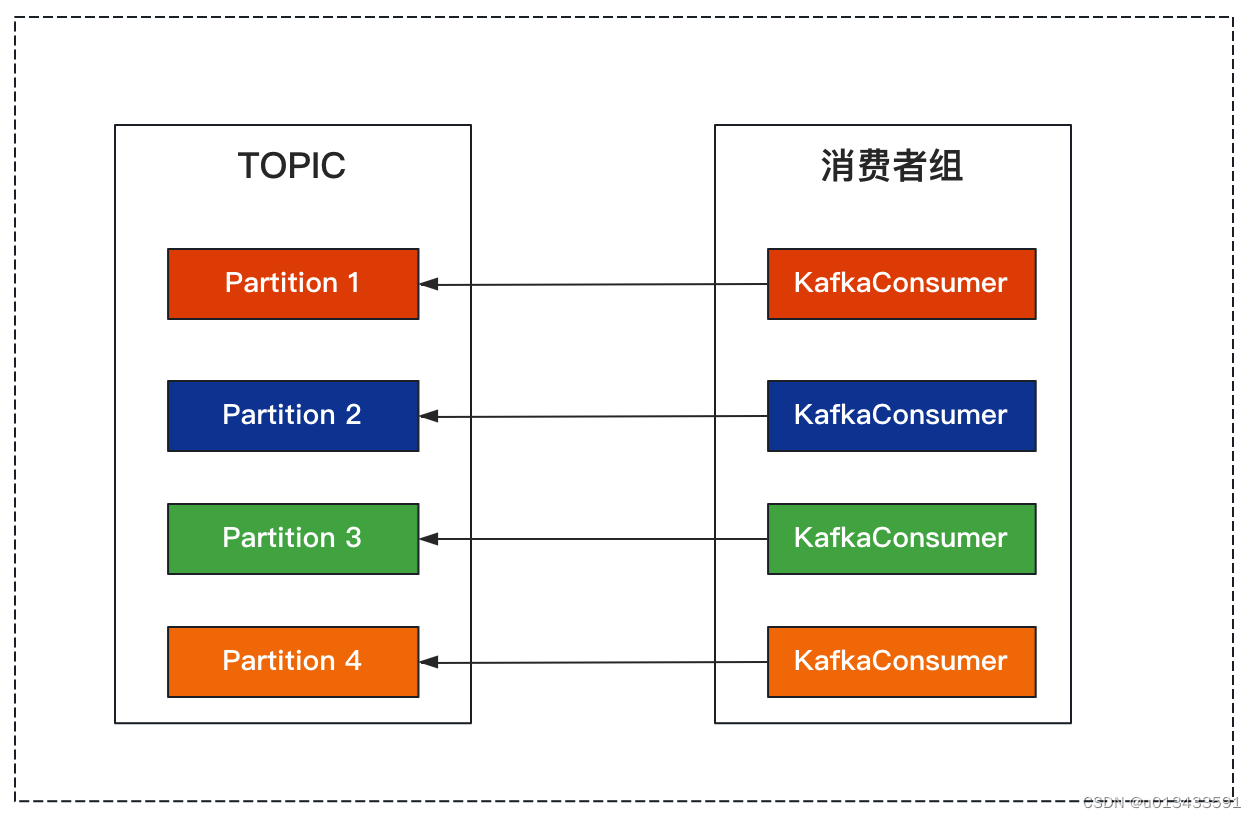
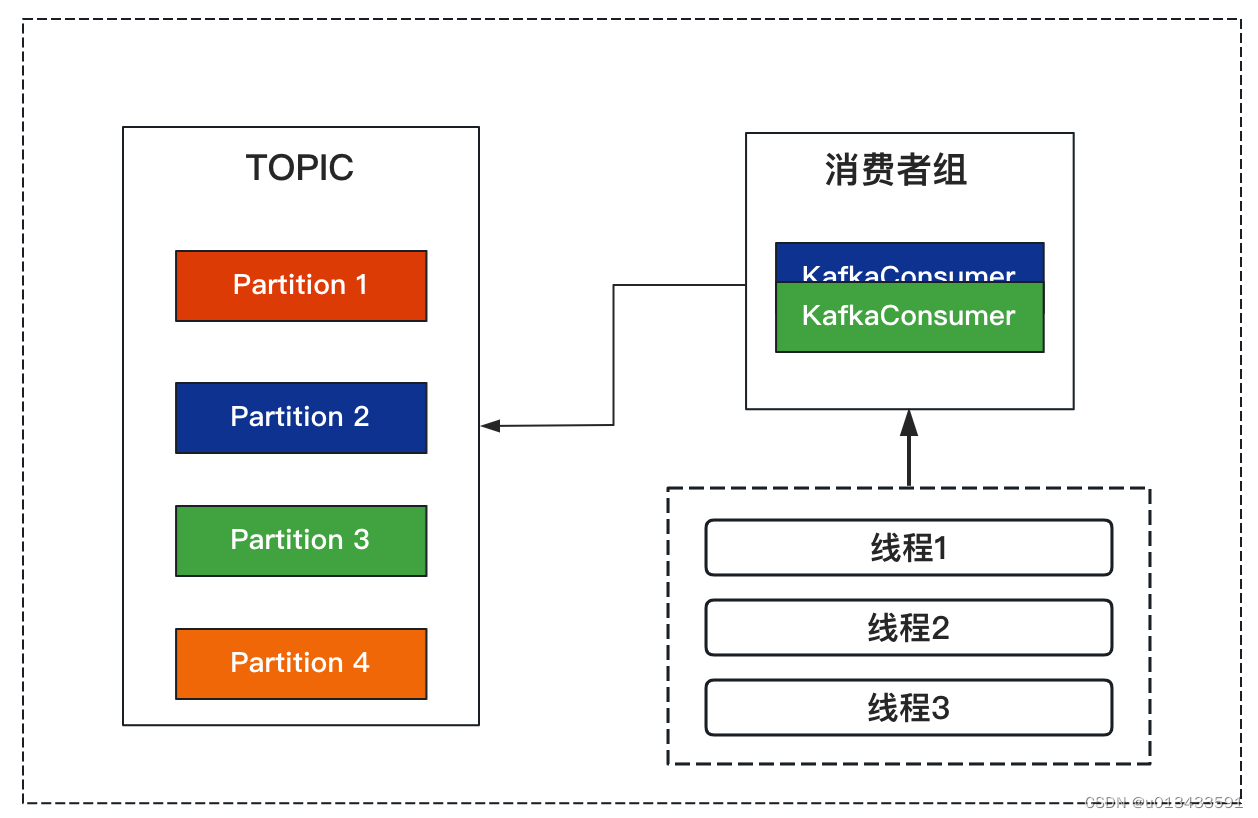
单个KafkaConsumer实例统一拉取数据,交给多个worker线程进行处理
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class MultiThreadConsumer {
public static void main(String[] args) {
String brokers = "localhost:9092";
String topic = "topic_t40";
String groupId = "app_q";
int consumers = 2;
for(int i = 0;i < consumers;i++){
final ConsumerRunnable consumer = new ConsumerRunnable(brokers, groupId, topic, "thread" + i);
new Thread(consumer).start();
}
}
static class ConsumerRunnable implements Runnable{
private final KafkaConsumer<String,String> consumer;
private volatile boolean isRunning = true;
private String threadName ;
public ConsumerRunnable(String brokers,String groupId,String topic,String threadName) {
Properties props = new Properties();
props.put("bootstrap.servers", brokers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
this.threadName = threadName;
}
@Override
public void run() {
try {
while (isRunning) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
records.forEach(record -> {
System.out.println(this.threadName + " : Message received " + record.value() + ", partition " + record.partition());
});
}
}finally {
consumer.close();
}
}
}
}
程序代码
public class WorkerConsumer {
private static ExecutorService executor = Executors.newFixedThreadPool(100);
public static void main(String[] args){
String topicName = "topic_t40";
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "app_w");
props.put("client.id", "client_02");
props.put("enable.auto.commit", true);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topicName));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
if(!records.isEmpty()){
executor.execute(new MessageHandler(records));
}
}
}finally {
consumer.close();
}
}
static class MessageHandler implements Runnable{
private ConsumerRecords<String, String> records;
public MessageHandler(ConsumerRecords<String, String> records) {
this.records = records;
}
@Override
public void run() {
records.forEach(record -> {
System.out.println(" 开始处理消息: " + record.value() + ", partition " + record.partition());
});
}
}
}
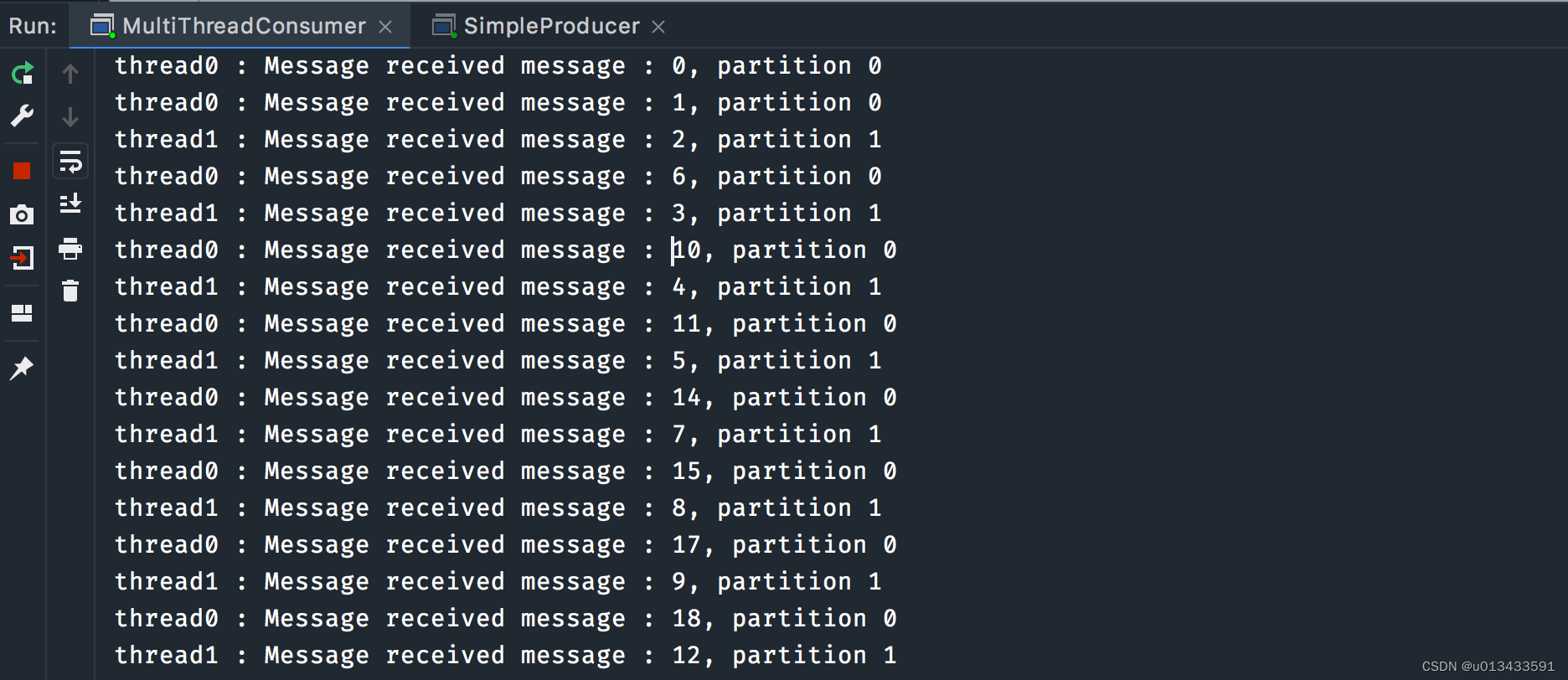
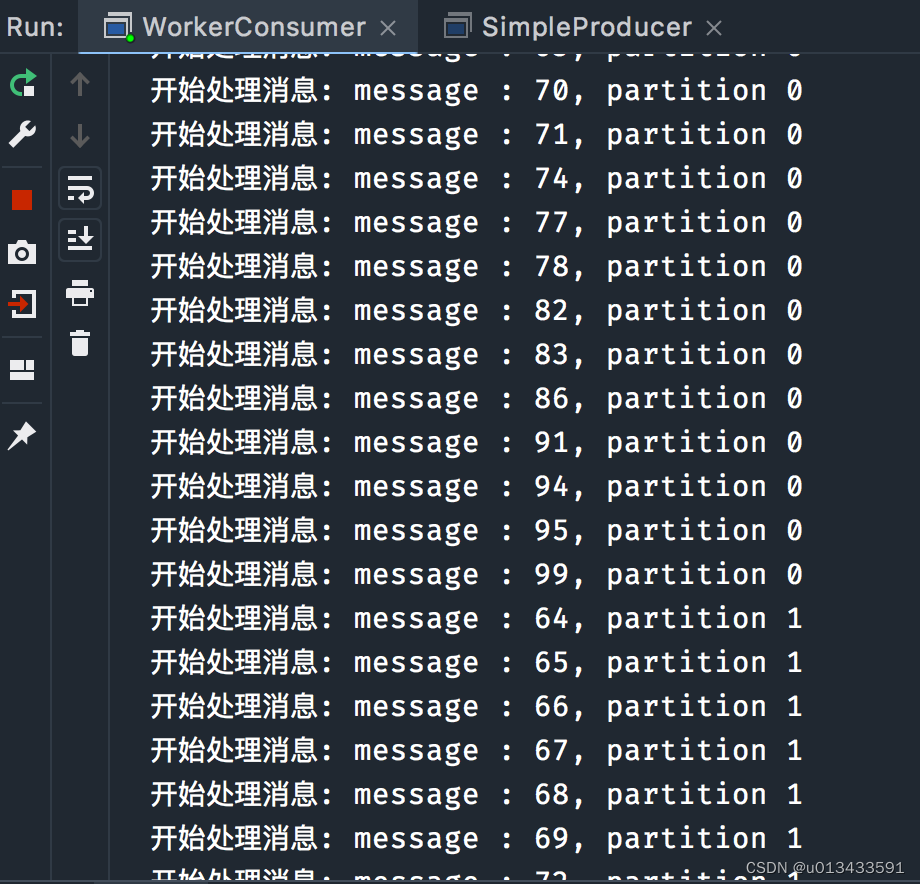
测试结果
多Consumer
多Work线程
之前提到过,消费者通过拉取模式从broker中拉取数据,每次消费成功后,消费者记录自身消费位移,当服务重启后,默认从最后的位移位置开始拉取最新的数据。那么消费者是如何记录自身的位移的呢?
__consumer_offset是kafka自行创建的一个内部topic,因此开发者不可以删除该topic,它的目的是存储Kafka 消费者的偏移量。consumer_offset是管理所有消费者的偏移量的一个主题。
# 查看kafka配置文件日志路径
more config/server.properties | grep log.dirs
log.dirs=/tmp/node0/kafka-logs
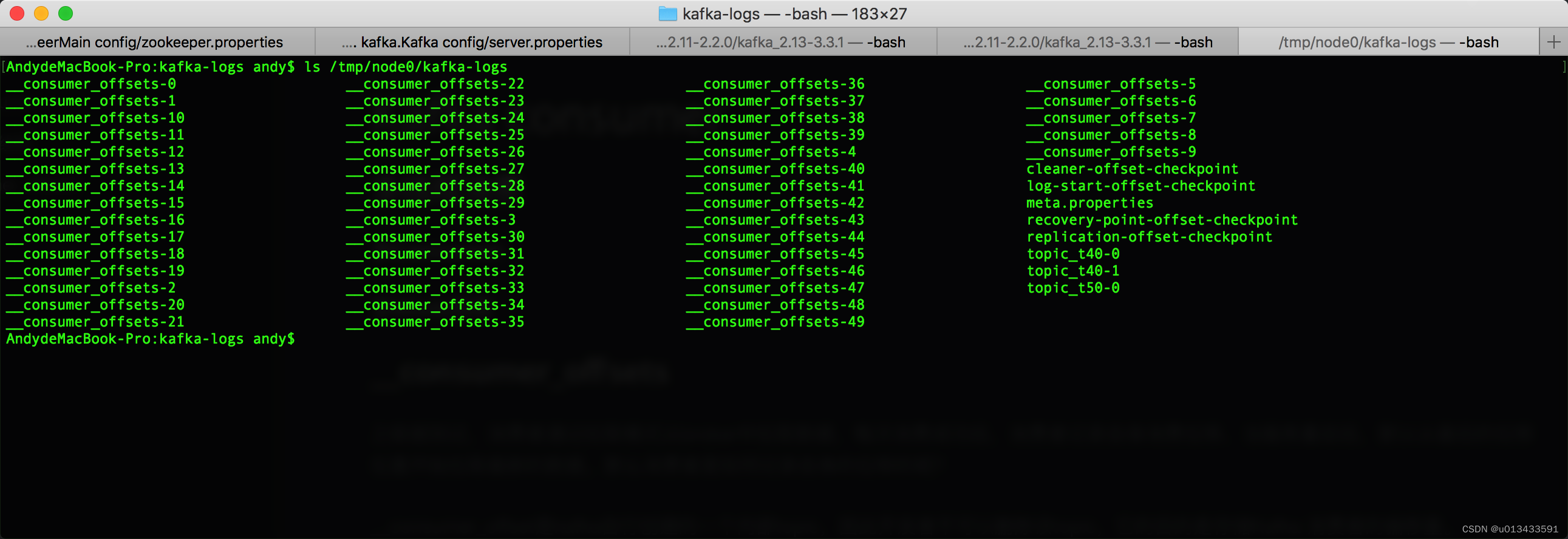
在kafka的日志目录中,可以看到由**__consumer_offsets**开头的带数字序号的50个文件夹,表示该topic有50个分区。进入任意文件夹,发现他跟正常的topic文件差不多,里面至少包含了2个index索引文件,一个日志文件
ls -ll /tmp/node0/kafka-logs/__consumer_offsets-1
total 16
-rw-r--r-- 1 andy wheel 10485760 12 27 21:07 00000000000000000000.index
-rw-r--r-- 1 andy wheel 0 12 26 19:49 00000000000000000000.log
-rw-r--r-- 1 andy wheel 10485756 12 27 21:07 00000000000000000000.timeindex
-rw-r--r-- 1 andy wheel 8 12 27 21:07 leader-epoch-checkpoint
-rw-r--r-- 1 andy wheel 43 12 26 19:49 partition.metadata00000000000000000000.log 00000000000000000000.timeindex leader-epoch-checkpoint partition.metadata
当多个consumer 或 consumer group需要同时提交位移信息时,kafka会根据每个消费者的group.id 做hash取模运算,从而将位移数据负载到不同的分区上。
kafka 消费者处理支持常规的topic列表进行订阅之外,还支持基于正则表达式订阅topic,代码实现分别如下:
consumer.subscribe(Arrays.asList("hello","world"));
consumer.subscribe(Pattern.compile("topic_*"));
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我正在尝试使用ruby编写一个双线程客户端,一个线程从套接字读取数据并将其打印出来,另一个线程读取本地数据并将其发送到远程服务器。我发现的问题是Ruby似乎无法捕获线程内的错误,这是一个示例:#!/usr/bin/rubyThread.new{loop{$stdout.puts"hi"abc.putsefsleep1}}loop{sleep1}显然,如果我在线程外键入abc.putsef,代码将永远不会运行,因为Ruby将报告“undefinedvariableabc”。但是,如果它在一个线程内,则没有错误报告。我的问题是,如何让Ruby捕获这样的错误?或者至少,报告线程中的错误?
我是ruby的新手,我认为重新构建一个我用C#编写的简单聊天程序是个好主意。我正在使用Ruby2.0.0MRI(Matz的Ruby实现)。问题是我想在服务器运行时为简单的服务器命令提供I/O。这是从示例中获取的服务器。我添加了使用gets()获取输入的命令方法。我希望此方法在后台作为线程运行,但该线程正在阻塞另一个线程。require'socket'#Getsocketsfromstdlibserver=TCPServer.open(2000)#Sockettolistenonport2000defcommandsx=1whilex==1exitProgram=gets.chomp
我有一个使用PDFKit呈现网页的pdf版本的Rails应用程序。我使用Thin作为开发服务器。问题是当我处于开发模式时。当我使用“bundleexecrailss”启动我的服务器并尝试呈现任何PDF时,整个过程会陷入僵局,因为当您呈现PDF时,会向服务器请求一些额外的资源,如图像和css,看起来只有一个线程.如何配置Rails开发服务器以运行多个工作线程?非常感谢。 最佳答案 我找到的最简单的解决方案是unicorn.geminstallunicorn创建一个unicorn.conf:worker_processes3然后使用它:
所以,Ruby1.9.1现在是declaredstable.Rails应该与它一起工作,并且正在慢慢地将gem移植到它。它具有native线程和全局解释器锁(GIL)。自从GIL到位后,原生线程是否比1.9.1中的绿色线程有任何优势? 最佳答案 1.9中的线程是原生的,但它们被“放慢了速度”,一次只允许一个线程运行。这是因为如果线程真的并行运行,它会混淆现有代码。优点:IO现在在线程中是异步的。如果一个线程阻塞在IO上,那么另一个线程将继续执行直到IO完成。C扩展可以使用真正的线程。缺点:任何非线程安全的C扩展都可能存在使用Thre
我在一个ruby文件中有一个函数可以像这样写入一个文件File.open("myfile",'a'){|f|f.puts("#{sometext}")}这个函数在不同的线程中被调用,使得像上面这样的文件写入不是线程安全的。有谁知道如何以最简单的方式使这个文件写入线程安全?更多信息:如果重要的话,我正在使用rspec框架。 最佳答案 您可以通过File#flock给锁File.open("myfile",'a'){|f|f.flock(File::LOCK_EX)f.puts("#{sometext}")}
我编写了几个类来控制我想如何处理多个网站,两者都使用类似的方法(即登录、刷新)。每个类都打开自己的WATIR浏览器实例。classSite1definitialize@ie=Watir::Browser.newenddeflogin@ie.goto"www.blah.com"endend无线程的main中的代码示例如下require'watir'require_relative'site1'agents=[]agents这工作正常,但在当前代理完成登录之前不会移动到下一个代理。我想合并多线程来处理这个问题,但似乎无法让它工作。require'watir'require_relative
代码:threads=[]Thread.abort_on_exception=truebegin#throwexceptionsinthreadssowecanseethemthreadseputs"EXCEPTION:#{e.inspect}"puts"MESSAGE:#{e.message}"end崩溃:.rvm/gems/ruby-2.1.3@req/gems/activesupport-4.1.5/lib/active_support/dependencies.rb:478:inload_missing_constant':自动加载常量MyClass时检测到循环依赖稍加研究后,
任何人都可以推荐任何详细介绍Ruby多线程/多处理的复杂性的好的多线程/处理书籍/网站吗?我尝试使用ruby线程,基本上在1.9vm上的无死锁代码中它在jruby中遇到了死锁。是的,我意识到差异很大(jruby没有GIL),但我想知道是否有用于ruby中多线程编程的策略或类集,我只需要继续阅读。旁注:从java到ruby必须定义是否需要重新输入锁,这有点奇怪。 最佳答案 如果你使用Ruby1.9,你可以试试Fiber,它是Ruby中线程的一大改进http://ruby-doc.org/core-1.9/classes/F
我想从不同线程调用一个公共(public)枚举器。当我执行以下操作时,enum=(0..1000).to_enumt1=Thread.newdopenum.nextsleep(1)endt2=Thread.newdopenum.nextsleep(1)endt1.joint2.join它引发了一个错误:Fibercalledacrossthreads.当enum在从t1调用一次后从t2调用时。为什么Ruby设计为不允许跨线程调用枚举器(或纤程),以及是否有其他方法可以提供类似的功能?我猜测枚举器/纤程上的操作的原子性在这里是相关的,但我不完全确定。如果这是问题所在,那么在使用时独占锁定