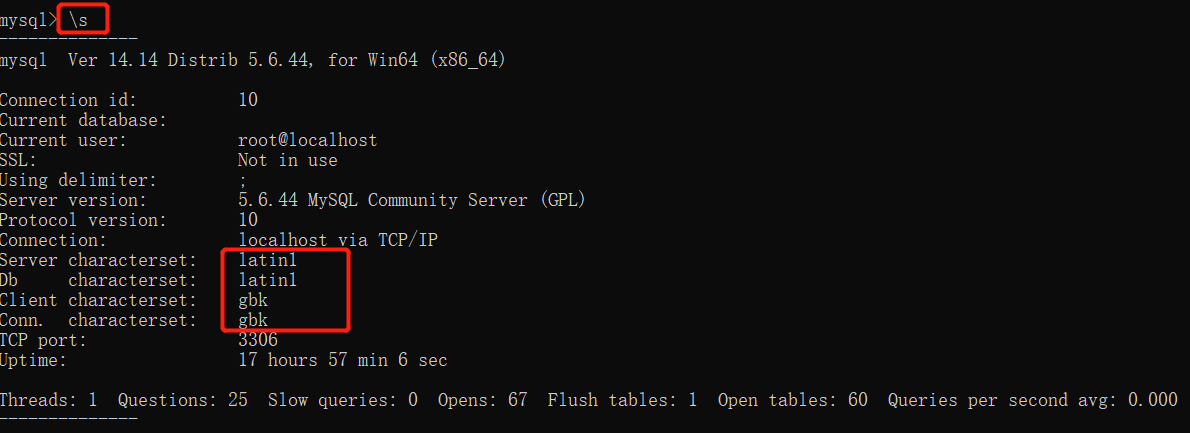
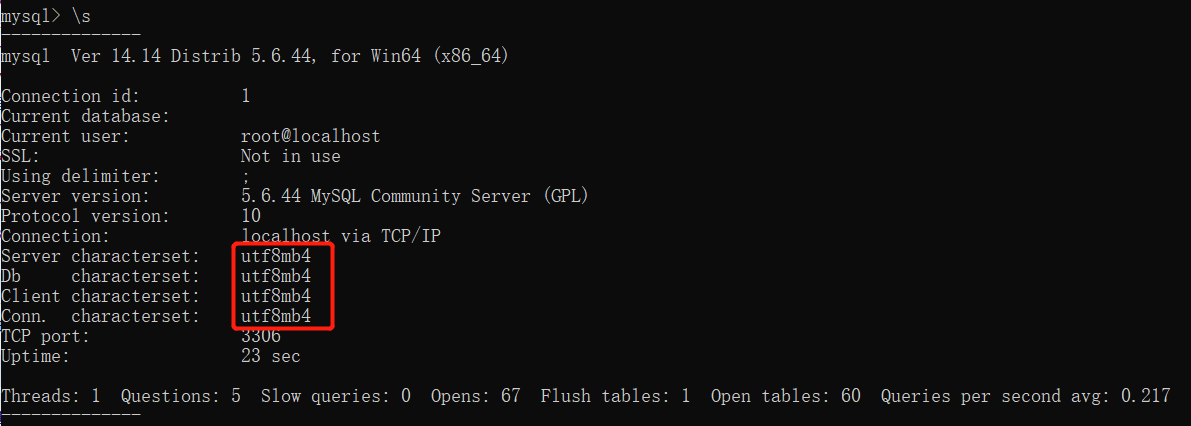
相关信息有:当前用户、版本、编码、端口号
MySQL5.6及之前的版本编码需要人为统一 之后的版本已经全部默认统一
如果想要永久修改编码配置 需要操作配置文件my-default.ini
注意事项:
2.默认的配置文件是my-default.ini
拷贝上述文件并重命名为my.ini
直接拷贝字符编码相关配置即可无需记忆
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
ps:
1.utf8mb4能够存储表情 功能更强大
2.utf8与utf-8是有区别的 MySQL中只有utf8
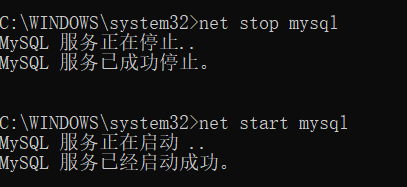
修改了配置文件中关于[mysqld]的配置 需要重启服务端
"""
利用配置文件我们可以偷懒
将管理员登录的账号密码直接写在配置文件中 之后使用mysql登录即可
[mysql]
user='root'
password=123
"""

my.ini这个名字不能随便取,放在旁边(注意打开文件扩展名)

补充说明:
1. mysql中'utf8'和'utf-8'这两个是有区别的:mysql中只允许有utf8.
2. [client]表示第三方的客户端 [mysql]表示自己写的客户端 [server]表示服务端.
3. 如果是8.0版本的mysql,则默认编码是utfmb4.
在mysqld的配置文件中加一串不明所以的代码
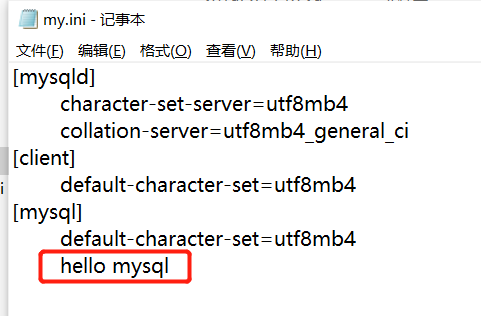
重启服务端,登录mysql:

会直接报错 连密码都输不进去了。所以说配置文件是在客户端启动之前加载的。
修改配置文件:

实现不输入密码直接登录,原来是账号密码写配置文件里了:
数据库针对数据采取的多种存取方式
举例:
不同的引擎针对相同的数据 采取的方式不一样
给小勇,小红一份数据:
小勇 ---> 存电脑 取的时候:小勇乖乖拿过来
小红 ----> 存网盘 取的时候:小红叫我过来拿
在mysql中使用show engines;命令查看引擎:
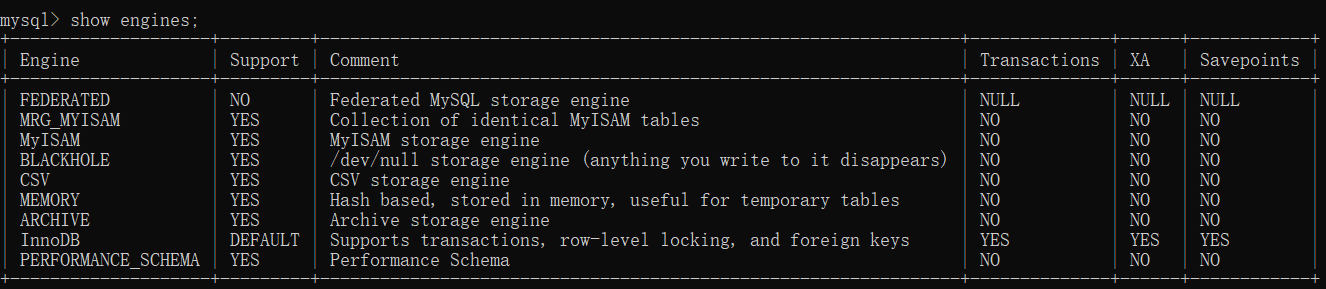
表格从左到右 ---> 引擎 模式 描述 事务 断点
事务:当两个不同的数据库交互时 例如小红转账时 银行瘫痪 只扣钱没加钱 事务可以让时间倒流
MyISAM
MySQL5.5之前默认的存储引擎
存取数据的速度快 但是功能较少 安全性较低
myisam 不支持事务 行锁表锁
InnoDB
MySQL5.5之后默认的存储引擎
支持事务、行锁、外键等操作 存取速度没有MyISAM快 但是安全性更高
Memory
基于内存存取数据 仅用于临时表数据存取
基于hash 默认不持久保存
BlackHole
任何写入进去的数据都会立刻丢失
备份时数据的处理
查看表的存储引擎:
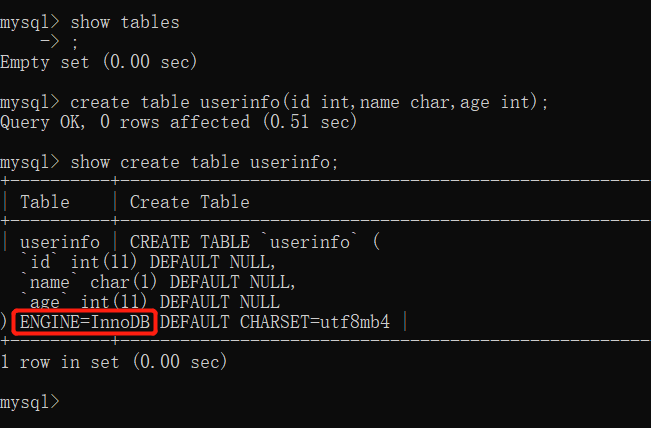
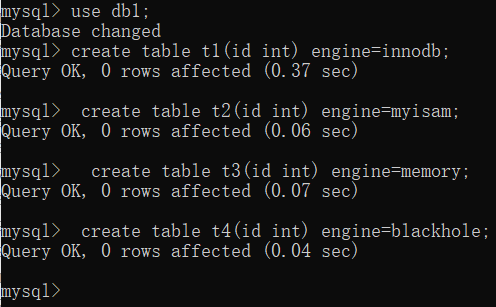
了解不同存储引擎底层文件个数
create database db2;
use db2;
create table t1(id int) engine=innodb;
create table t2(id int) engine=myisam;
create table t3(id int) engine=memory;
create table t4(id int) engine=blackhole;
'''
1.innodb两个文件
.frm 表结构
.ibd 表数据(表索引)
2.myisam三个文件
.frm 表结构
.MYD 表数据
.MYI 表索引
3.memory一个文件
.frm 表结构
4.blackhole一个文件
.frm 表结构
'''
insert into t1 values(1);
insert into t2 values(1);
insert into t3 values(1);
insert into t4 values(1);
'''
表索引相当于书的目录 用于加快数据查询
memery 基于内存所以没有表数据 文件是操作系统暴露出来给用户操作硬盘的快捷方式'''
ps:MySQL默认忽略大小写
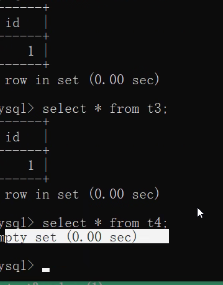
t3 重启服务数据消失:
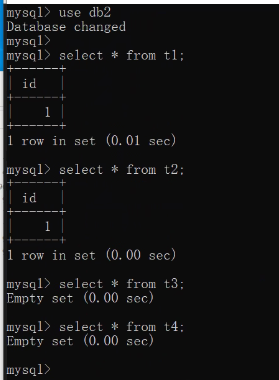
t4 数据直接消失:
'''
create table 表名(
字段名 字段类型(数字) 约束条件,
字段名 字段类型(数字) 约束条件,
字段名 字段类型(数字) 约束条件
);
'''
1.字段名和字段类型是必须的
2.数字和约束条件是可选的
3.约束条件也可以写多个 空格隔开即可
4.'''最后一行结尾不能加逗号'''
ps:编写SQL语句报错之后不要慌 仔细查看提示 会很快解决
near ')' at line 7
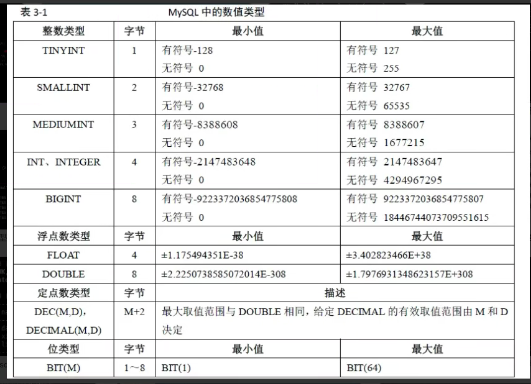
tinyint 1bytes 正负号(占1bit)
smallint 2bytes 正负号(占1bit)
int 4bytes 正负号(占1bit)
bigint 8bytes 正负号(占1bit)
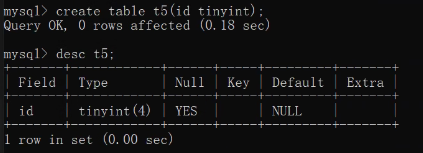
create table t5(id tinyint);
insert into t5 values(-129),(128);
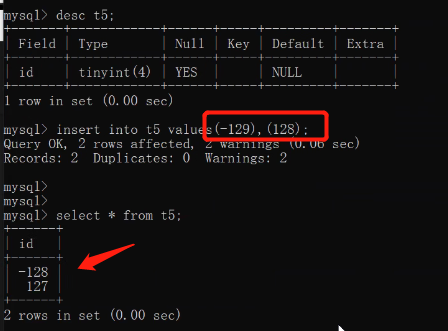
结果是-128和127 也就意味着默认自带正负号
正负数也要占用一个bit位 故只能存128
手机号(13位)存储时,Int的位数不够(10位) 需要使用bigint、字符串。
我们也可以取消正负号,使用约束条件unsigned.
create table t6(id tinyint unsigned);
insert into t6 values(-129),(128),(1000);
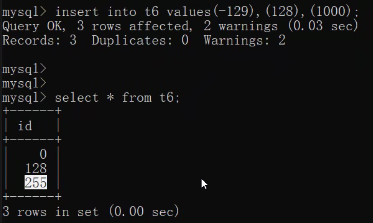
当我们在使用数据库存储数据的时候 如果数据不符合规范
应该直接报错而不是擅自修改数据 这样会导致数据的失真(没有实际意义)
正常情况下是应该报错 但是我们之前修改了配置文件 将严格模式的配置代码给删掉了
代码的意思是找出所有带mode的配置信息:
show variables like '%mode%';
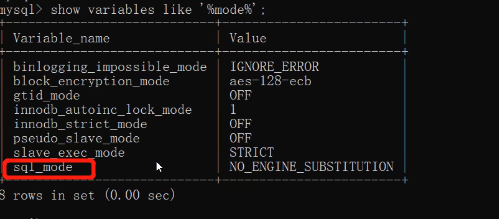
这表示没有开启严格模式
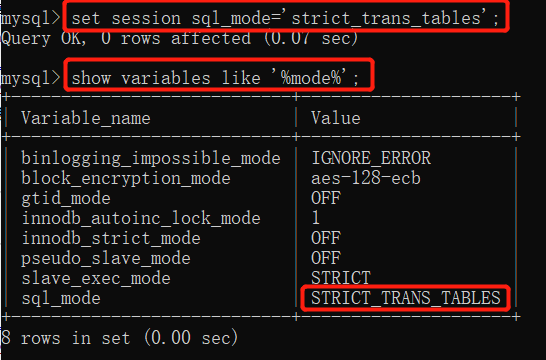
set session sql_mode='strict_trans_tables';
在当前客户端有效 当前用户有效 用户退出之后重新登录无效
set global sql_mode='strict_trans_tables';
在当前服务端有效 只要服务器没重启 对所有用户都有效
给配置文件添加一行:
sql_mode = STRICT_TRANS_TABLES
配置文件现在的样子:
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
sql_mode = STRICT_TRANS_TABLES
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
语法:
float (存储数字的位数,小数点后面的数)
float(20,10)
总共存储20位数 小数点后面占10
double(20,10)
总共存储20位数 小数点后面占10
decimal(20,10)
总共存储20位数 小数点后面占10
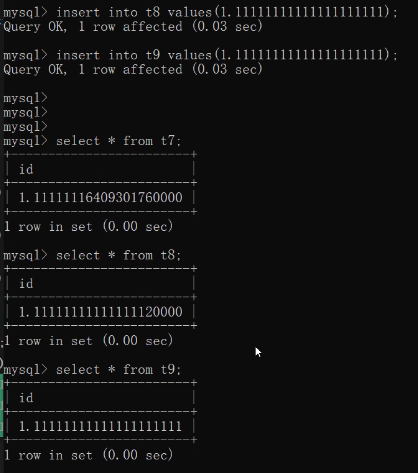
create table t7(id float(60,20));
create table t8(id double(60,20));
create table t9(id decimal(60,20));
insert into t7 values(1.11111111111111111111);
insert into t8 values(1.11111111111111111111);
insert into t9 values(1.11111111111111111111);
三者的核心区别在于精确度不同
float < double < decimal

验证三者精确度:
char
定长
char(4) 最多存储四个字符 超出就报错 不够四个空格填充至四个
varchar
变长
varchar(4) 最多存储四个字符 超出就报错 不够则有几位存几位
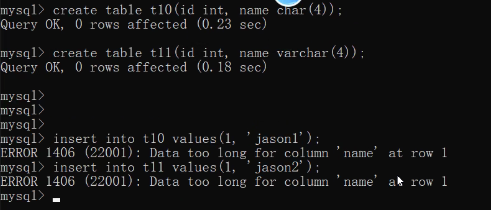
create table t10(id int, name char(4));
create table t11(id int, name varchar(4));
insert into t10 values(1, 'jason1');
insert into t11 values(1, 'jason2');
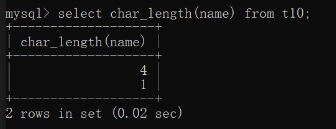
ps:char_length()获取字段存储的数据长度
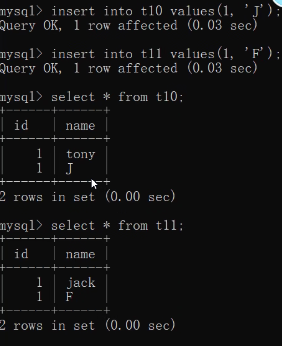
默认情况下MySQL针对char的存储会自动填充空格和删除空格
数字限制存储的字符长度:
输入:
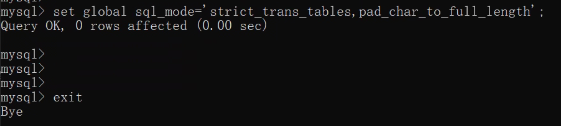
set global sql_mode='strict_trans_tables,pad_char_to_full_length';
注意这修改的是服务端层面,重启服务端则失效。
重新登录:
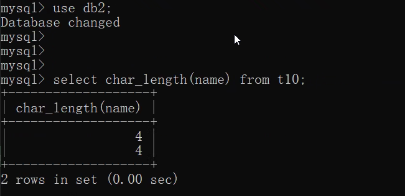
char
优势:整存整取 速度快
劣势:浪费存储空间
varchar
优势:节省存储空间
劣势:存取数据的速度较char慢
"""
char与varchar的使用需要结合具体应用场景
char(32)存中国人名字 劣势 因为大多数人名字都是两三个字 少部分人名字长
存姓名 用varchar
存手机号码 男女性别 用char
"""
# 为什么varchar存取速度较慢?
char取固定位数 直接拿就好了
jasonjacktomjerry 不知道存的时候是几位
不知道要取几位的时候 使用报头
存数据时用1bytes作为报头
取的时候先取一个字节的报头 解析数据真实的长度:
1bytes+jack 1bytes+tony 1bytes+jason 1bytes+kevin 1bytes+tom 1bytes+jerry
报头1bytes不够用怎么办?
数字在很多地方都是用来表示限制存储数据的长度
但是在整型中数字却不是用来限制存储长度
create table t12(id int(3));insert into t12 values(12345);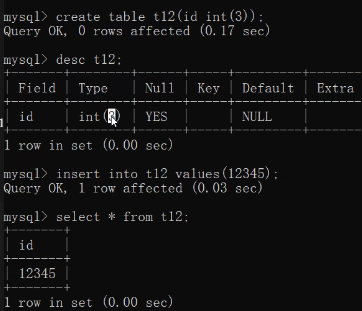
create table t13(id int(5) zerofill);insert into t13 values(123),(123456789);create table t14(id int);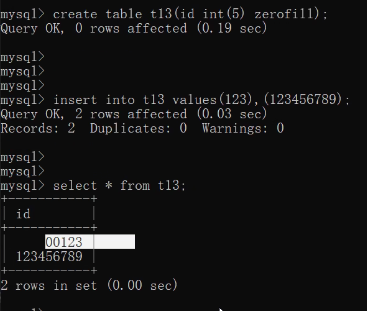
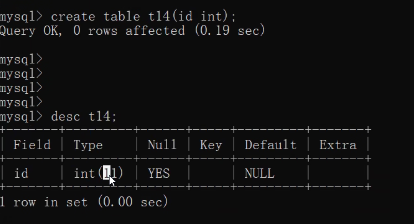
多选一
create table t15(
id int,
name varchar(32),
gender enum('male','female','others')
);
insert into t15 values(1,'tony','猛男');
insert into t15 values(2,'jason','male');
insert into t15 values(3,'kevin','others');
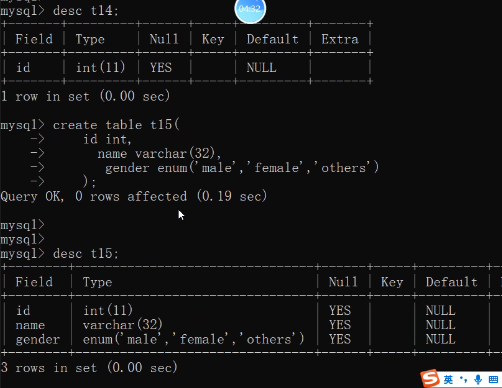

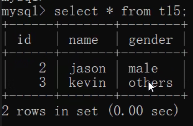
集合包括枚举!
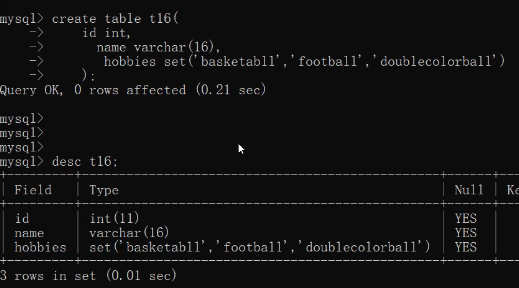
多选多(多选一)
create table t16(
id int,
name varchar(16),
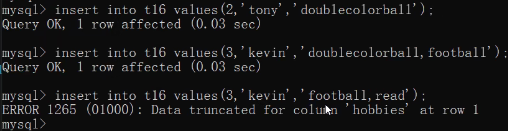
hobbies set('basketabll','football','doublecolorball')
);
insert into t16 values(1,'jason','study');
insert into t16 values(2,'tony','doublecolorball');
insert into t16 values(3,'kevin','doublecolorball,football');
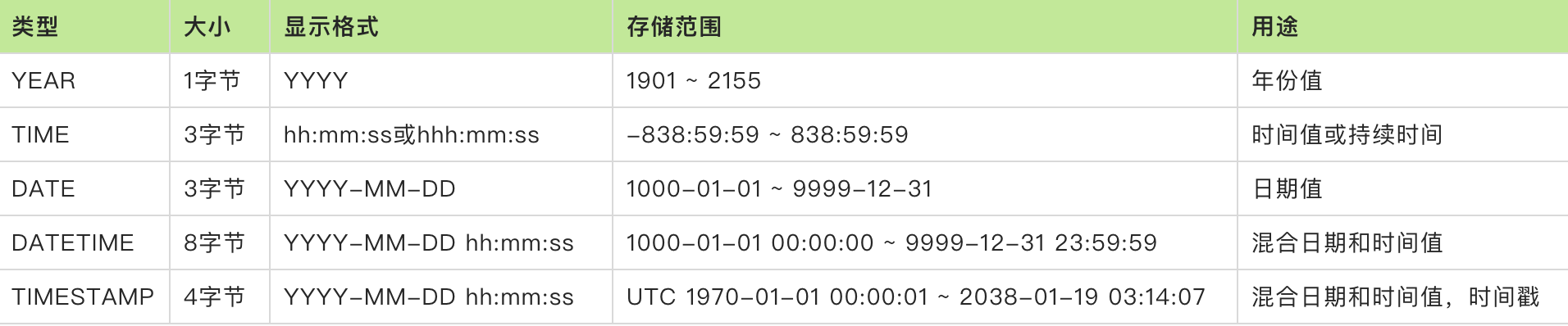
datetime 年月日时分秒
date 年月日
time 时分秒
year 年
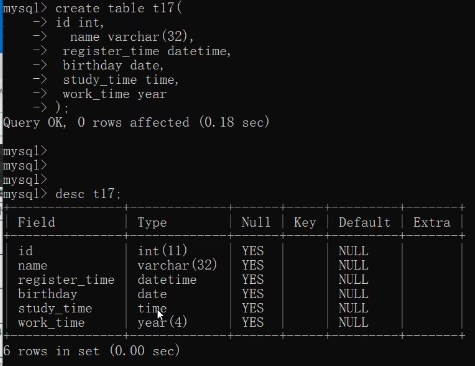
create table t17(
id int,
name varchar(32),
register_time datetime,
birthday date,
study_time time,
work_time year
);
insert into t17 values(1,'jason','2000-11-11 11:11:11','1998-01-21','11:11:11','2000');
ps:以后涉及到日期相关字段一般都是系统自动回去 无需我们可以操作
'''
以后所有的表都要用日期类型
datatime可以切割 想怎么切怎么切 用mysql内置函数 流程控制'''

MySQL语句处理逻辑, 其实就是一大堆函数执行和调用
连接层验证 >> 提供链接协议, 验证 >> 验证完成, 线程链接 >> 连接之后分配线程(线程池) >> 接收sql语句 >> 解析语义, 语法 >> 权限判断 >> 生成解析树 >> 优化器优化 >> 执行 >> 结果交给存储引擎 >> 拿到磁盘数据 >> 展示给用户
存储引擎相关:
MySQL所有管理操作都是以16进制的方式存储在磁盘上
主要是两大部分组成, 一部分内存结构In-Memory Structure, 一部分磁盘结构On-Disk Structure
1. 内存结构
Buffer Pool整体区域
Change Buffer索引相关
Log Buffer redo缓冲区
Adaptive Hash Index自适应hash索引
2. 磁盘结构
一系列表空间, system tablespace, undo, redo, file-per-table独立表空间, general, temporary
3. 线程结构
Main Thread: 核心后台进程, 负责全局数据管理和数据统一处理
IO Thread: 磁盘IO交互, 读写IO, inset buffer, log IO; 参数有inndb_read_io_threads...
Purge Thread: undo页回收
Page Cleaner: 脏页刷新线程, 默认1, 最大64
Other threads
DDL
Data Definition Language, 库表定义
库名, 库属性, 表名表属性, 列名, 列属性
额外:
https://www.cnblogs.com/ysging/articles/16915846.html
https://dev.mysql.com/doc/refman/8.0/en/faqs-storage-engines.html
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A