SQL 的分类
一、DDL(Data Definition Language)数据库定义语言 create /alter /drop /rename /truncate
1.数据库
1-1.创建数据库
方式1:直接创建
CREATE DATABASE 数据库名;方式2:创建数据库并指定字符集
CREATE DATABASE 数据库名 CHARACTER SET 字符集;方式3(推荐使用):判断数据库是否已经存在,不存在则创建数据库
CREATE DATABASE IF NOT EXISTS 数据库名;1-2.管理数据库
1-2-1.查看当前连接中的数据库都有哪些
SHOW DATABASES1-2-2.切换数据库
USE 数据库名;1-2-3.查看当前数据库中保存的数据表
SHOW TABLES;1-2-4.查看当前使用的数据库
SELECT DATABASE() FROM DUAL;1-2-5.查看指定数据库下保存的数据表
SHOW TABLES FROM 数据库名;1-3.修改数据库
更改数据库字符集
ALTER DATABASE 数据库名 CHARACTER SET 'utf8';1-4.删除数据库
方式1:如果要删除的数据库存在,则删除成功。如果不存在,则报错。
DROP DATABASES 数据库名;方式2:如果要删除的数据库存在,则删除成功。如果不存在,则默默结束,不会报错。
DROP DATABASES IF EXISTS 数据库名;2.数据表
2-1.创建数据表
方式一:(白手起家)
CREATE TABLE IF NOT EXISTS myemp1( #需要用户具备创建表的权限
id INT,
emp_name VARCHAR(15), #使用VARCHAR来定义字符串,必须在使用VARCHAR时指明其长度。
hire_data DATE
);查看表结构(表中字段的详细信息)
DESC 表名查看创建表的语句结构
SHOW CREATE TABLE 表名;#如果创建表时没有指明使用的字符集,则默认使用表所在的数据库的字符集。查看表数据
SELECT * FROM 表名;方式2:基于现有的表复制一个
CREATE TABLE myemp2
AS
SELECT employee_id,last_name,salary
FROM employees;2-2.修改表 -->ALTER TABLE
2-2-1.添加一个字段
ALTER TABLE 表名
ADD 字段名 DOUBLE(10,2); #默认添加到表中的最后一个字段的位置ALTER TABLE 表名
ADD 字段名 VARCHAR(20) FIRST;ALTER TABLE 表名
ADD 字段名1 VARCHAR(45) AFTER 字段名2;2-2-2.修改一个字段:数据类型、长度、默认值
修改长度:
ALTER TABLE 表名
MODIFY 字段名 VARCHAR(25);修改默认值:
ALTER TABLE 表名
MODIFY 字段名 VARCHAR(35) DEFAULT 'aaa';2-2-3.重命名一个字段
ALTER TABLE 表名
CHANGE 旧的字段名 新的字段名 DOUBLE(10,2);2-2-4.删除一个字段
ALTER TABLE 表名
DROP COLUMN 字段名;2-3.重命名表
方式1:
RENAME TABLE 表名1
TO 表名2;方式2:
ALTER TABLE 表名1
RENAME TO 表名2;2-4.删除表(删除表数据的同时,表结构也一起被删除。)
DROP TABLE IF EXISTS 表名;2-5.清空表(清空表中的所有数据,但是表结构保留。)
TRUNCATE TABLE 表名;二、DML(Data Manipulation Language)数据操纵语言 insert / delete / update / select
1.增(insert into):
方式1:同时插入多条记录
INSERT INTO 表名(字段名1,字段名2,字段名3)
VALUES ('字段值1-1','字段值2-1','字段值3-1'),
('字段值1-2','字段值2-2','字段值3-2'),
('字段值1-3','字段值2-3','字段值3-3');方式2:将查询结果插入到表中(查询的字段一定要与添加到表中的字段一一对应)
INSERT INTO line(id,deleted,code)
SELECT id,deleted,line_id
FROM data
GROUP BY line_id2.删(delete):
DELETE FROM 表名
WHERE 字段名1 = '字段值1'3.改(update):
UPDATE 表名
SET 字段名1 = '字段值1',字段名2 = '字段值2',字段名3 = '字段值3'
WHERE 字段名n = '字段值n'4.查(select):
4-1.in(set) / not in(set) :查询字段名2为/不为字段值2-1,字段值2-2,字段值2-3的字段1信息
SELECT 字段名1
FROM 表名
WHERE 字段名2 IN (字段值2-1,字段值2-2,字段值2-3)4-2.like :模糊查询 (_代表一个不确定的字符,%代表不确定个数的字符)
4-2-1.查询字段名1中包含字符a的字段1信息
SELECT 字段名1
FROM 表名
WHERE 字段名1 LIKE '%a%'4-2-2.查询第3个字符是‘a'的字段1信息
SELECT 字段名1
FROM 表名
WHERE 字段名1 LIKE '__a%'4-3.or可以与and一起使用,但and优先级高于or,因此先对and两边的操作数进行操作,再与or中的操作数结合。
4-4.排序与分页
4-4-1.排序(升序:ASC(可省) / 降序:DESC)
1⃣️ 列的别名只能在order by中使用,不能在where中使用;
2⃣️ 如果没有使用排序操作,默认情况下查询返回的数据是按照添加数据的顺序显示的;
3⃣️ 可以使用不在select列表中的列排序;
4⃣️ 在对多列进行排序(即二级排序)时,首先排序的第一列必须有相同的列值,才会对第二列排序。
例如:查询图书信息,按照库存量降序排列,如果库存量相同的,按照note升序排列。
SELECT *
FROM books
ORDER BY num DESC , note ASC;4-4-2.分页(limit )limit子句必须放在整个select语句的最后;
1⃣️ limit和offset子句通常和order by语句一起使用,当我们对整个结果集排序之后,我们可以用limit来指定返回多少行数据,用offset来指定从哪一行开始返回;
例如:按片长排列,wang导演导过片长第3长的电影是哪部?
SELECT title
FROM movies
WHERE director = 'wang'
ORDER BY length_minutes desc
LIMIT 1 OFFSET 2;2⃣️ 使用limit实现数据的分页显示
公式:limit(页码-1)*每页条数,每页条数;
例如:每页显示20条记录,此时显示第2页。
SELECT 字段名1,字段名2
FROM 表名
LIMIT 20,20;4-5.在查询中进行统计
4-5-1.常见统计函数(聚合函数不能嵌套):
COUNT(*) 计数,统计数据行数;
COUNT(column)计数,统计字段中非null的行数;
MIN(column)找column最小的一行;
MAX(column)找column最大的一行;
AVG(column)对所有行取平均值;
SUM(column)对所有行求和。
4-5-2.分组 (group by)
select中出现的非组函数的字段必须声明在group by中,反之,group by中声明的字段可以不出现在select中。
例1:按角色统计每个角色的平均就职年份
SELECT role,AVG(Years_employed)
FROM employees
GROUP BY role;例2:按姓名统计t表中id最大的
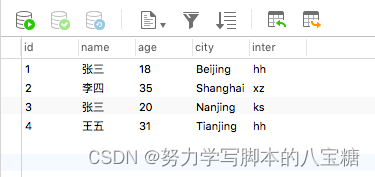
SELECT max(id)
FROM t
GROUP BY name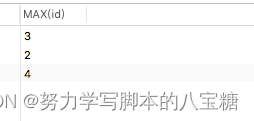
HAVING必须声明在GROUP BY之后,即使用HAVING的前提是SQL中使用了GROUP BY
例子:查询部门id为10,20,30,40这4个部门中最高工资比10000高的部门信息。
SELECT department_id,MAX(salary)
FROM employees
WHERE department_id IN (10,20,30,40)
GROUP BY department_id
HAVING MAX(salary) > 10000;where和having的区别:
当过滤条件中有聚合函数时,则过滤此条件必须声明在HAVING中;当过滤条件中没有聚合函数时,则建议声明在WHERE中。
从使用范围上看,HAVING的适用范围更广;如果过滤条件中没有聚合函数,WHERE的执行效率要高于HAVING。
4-6.子查询
例子:查询部门的部门号,其中不包括job_id是"ST_CLERK"的部门号
SELECT department_id
FROM departments
WHERE department_id NOT IN (
SELECT DISTINCT department_id
FROM employees
WHERE job_id = 'ST_CLERK'
);
4-7.多表查询
4-7-1.内连接(结果集中不包括一个表与另一个表不匹配的行)
1⃣️两个表
SELECT e.last_name,d.department_name
FROM employees e JOIN departments d
ON e.department_id = d.department_id;1⃣️三个表
SELECT e.last_name,d.department_name
FROM employees e JOIN departments d
ON e.department_id = d.department_id
JOIN locations l
ON d.location_id = l.location_id;4-7-2.左外连接(两个表在连接过程中除了返回满足连接条件的行以外,还返回左表中不满足条件的行。)
例子:查询所有员工的last_name,department_name信息。
SELECT e.last_name,d.department_name
FROM employees e LEFT JOIN departments d
ON e.department_id = d.department_id;4-7-3.右外连接(两个表在连接过程中除了返回满足连接条件的行以外,还返回右表中不满足条件的行。)
例子:查询所有部门的last_name,department_name信息。
SELECT e.last_name,d.department_name
FROM employees e RIGHT JOIN departments d
ON e.department_id = d.department_id;4-8.SQL99语法
书写顺序:
SELECT ...,...,...(存在聚合函数)
FROM ...(LEFT/RIGHT) JOIN ... ON 多表的连接条件
(LEFT/RIGHT) JOIN ... ON...
WHERE 不包含聚合函数的过滤条件
GROUP BY...,...
HAVING 包含聚合函数的过滤条件
ORDER BY...,...(ASC/DESC)
LIMIT...,...执行过程:
FROM...,...——>ON——>(LEFT/RIGHT JOIN)——>WHERE——>GROUP BY——>HAVING——>SELECT——>DISTINCT——>ORDER BY——>LIMIT三、DCL(Data Control Language)数据库控制语言 commit /rollback /savepoint /grant /revoke
1.DCL中COMMIT和ROLLBACK
1-1.COMMIT:提交数据。一旦执行COMMIT,则数据就永久的保存在数据库中,意味着数据不可以回滚。
1-2.ROLLBACK:回滚数据。一旦执行ROLLBACK,则可以实现数据的回滚。回滚到最近的一次COMMIT之后。
2.对比TRUNCATE TABLE 和 DELETE FROM
2-1.相同点:都可以实现对表中所有数据的删除,同时保留表结构。
2-2.不同点:
TRUNCATE TABLE :一旦执行此操作,表数据全部删除。同时,数据是不可以回滚的。速度更快,且占用资源少,但TRUNCATE可能造成事故,故不建议在开发代码中使用此语句。
DELETE FROM:一旦执行此操作,表数据可以全部删除,也可以部分清除(where),同时,数据是可以实现回滚的。
3.DDL和DML的说明
3-1.DDL的操作一旦执行, 就不可回滚。指令SET autocommit = FALSE对DDL操作无效。(因为在执行完DDL操作之后,一定会执行一次COMMIT,而此COMMIT操作不受SET autocommit = FALSE影响的。)
3-2.DML的操作默认情况,一旦执行,也是不可回滚的。
SET autocommit = FALSE,则执行的DML操作就可以实现回滚。
system-view进入系统视图quit退到系统视图sysname交换机命名vlan20创建vlan(进入vlan20)displayvlan显示vlanundovlan20删除vlan20displayvlan20显示vlan里的端口20Interfacee1/0/24进入端口24portlink-typeaccessvlan20把当前端口放入vlan20undoporte1/0/10删除当前VLAN端口10displaycurrent-configuration显示当前配置02配置交换机支持TELNETinterfacevlan1进入VLAN1ipaddress192.168.3.100
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我找到了这样的东西:Rails:Howtolistdatabasetables/objectsusingtheRailsconsole?这一行没问题:ActiveRecord::Base.connection.tables并返回所有表但是ActiveRecord::Base.connection.table_structure("users")产生错误:ActiveRecord::Base.connection.table_structure("projects")我认为table_structure不是Postgres方法。如何列出Postgres数据库的Rails控制台中表中的所有
Ruby中防止SQL注入(inject)的好方法是什么? 最佳答案 直接使用ruby?使用准备好的语句:require'mysql'db=Mysql.new('localhost','user','password','database')statement=db.prepare"SELECT*FROMtableWHEREfield=?"statement.execute'value'statement.fetchstatement.close 关于ruby-防止SQL注入(inject
我正在编写一个Rails应用程序,它将监视某些特定数据库的数据质量。为了做到这一点,我需要能够对这些数据库执行直接SQL查询——这当然与用于驱动Rails应用程序模型的数据库不同。简而言之,这意味着我无法使用通过ActiveRecord基础连接的技巧。我需要连接的数据库在设计时是未知的(即:我不能将它们的详细信息放在database.yaml中)。相反,我有一个模型“database_details”,用户将使用它来输入应用程序将在运行时执行查询的数据库的详细信息。因此与这些数据库的连接实际上是动态的,细节仅在运行时解析。 最佳答案
我正在使用Rails4应用程序,它需要创建大量对象以响应来自另一个系统的事件。当我调用create!时,主键列上出现非常频繁的ActiveRecord::RecordNotUnique错误(由PG::UniqueViolation引起)我的模型之一。我在SO上找到了其他答案,建议挽救异常并调用retry:beginTableName.create!(data:'here')rescueActiveRecord::RecordNotUnique=>eife.message.include?'_pkey'#Onlyretryprimarykeyviolationslog.warn"Retr
我有一个PORO(普通旧Ruby对象)来处理一些业务逻辑。它接收一个ActiveRecord对象并对其进行分类。为了简单起见,以下面为例:classClassificatorSTATES={1=>"Positive",2=>"Neutral",3=>"Negative"}definitializer(item)@item=itemenddefnameSTATES.fetch(state_id)endprivatedefstate_idreturn1if@item.value>0return2if@item.value==0return3if@item.value但是,我还想根据这些st
我正在使用ARincludes在对象User和Building之间执行LEFTOUTERJOIN的方法,其中User可能有也可能没有Building关联:users=User.includes(:building).references(:buildings)因为我正在使用references,任何关联的Building对象都将被预先加载。我的期望是我随后能够遍历用户列表,并检查用户是否有与其关联的建筑物而不会触发额外的查询,但实际上每当我尝试访问建筑物属性时我都会看到对于没有建筑物的用户,AR会进行另一个SQL调用以尝试检索该建筑物(尽管在后续尝试中它只会返回nil)。这些查询显然是
我有以下模型:activity.rbtag.rbtagging.rb标签是事件和标签的连接模型。我想搜索具有2个或更多标签的事件。我如何在Rails中执行此操作?例如:我有tag1=Christmas,tag2=Florida,tag3=John如果存在,我想找到tag1、tag2和tag3存在的Activity。[编辑]我最终做了什么:tags=[tag1,tag2,tag3]activities=[]tags.eachdo|tag|activities如果任何组值的大小等于tags.size,则该事件包含所有标签。 最佳答案 如