目录
我们需要先构建个二叉树,方便后续对函数的测试;
还有我们在实现二叉树的这些函数时,尽量少用遍历,这里用的比较多的就是递归和分治思想。
typedef int Tdatatype;
typedef struct Tree
{
Tdatatype data;
struct Tree* left;
struct Tree* right;
}Tree;
Tree* BuyTree(Tdatatype x)
{
Tree* node = (Tree*)malloc(sizeof(Tree));
if (node == NULL)
{
perror("malloc fail");
return NULL;
}
node->data = x;
node->left = NULL;
node->right = NULL;
return node;
}
Tree* CreateTree() //这里可以自由操控二叉树的构建
{
Tree* node1 = BuyTree(1);
Tree* node2 = BuyTree(2);
Tree* node3 = BuyTree(3);
Tree* node4 = BuyTree(4);
Tree* node5 = BuyTree(5);
Tree* node6 = BuyTree(6);
Tree* node7 = BuyTree(7);
node1->left = node2;
node1->right = node4;
node2->left = node3;
node2->right = node7;
node4->left = node5;
node4->right = node6;
return node1;
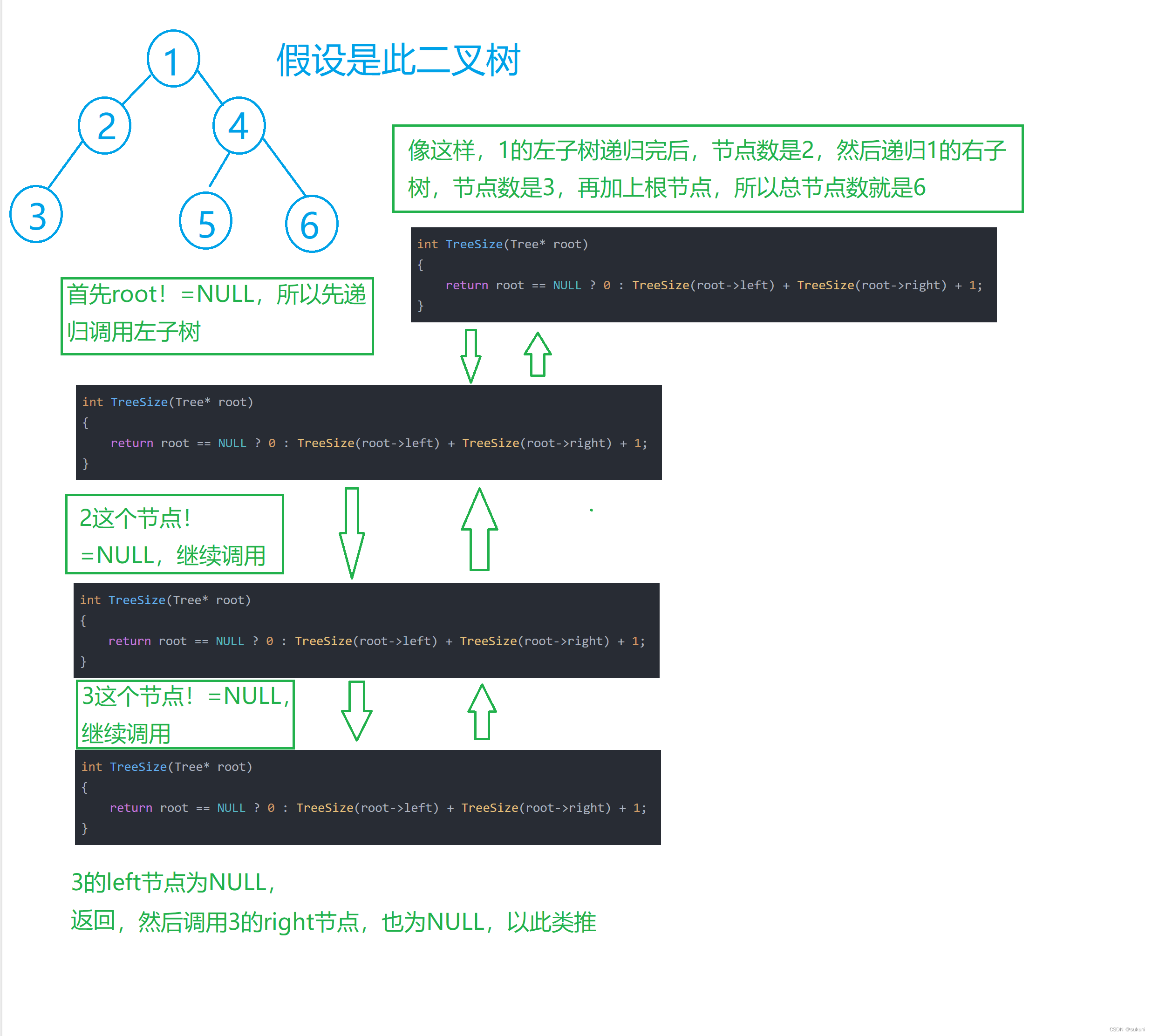
}二叉树的节点数=左子树的节点数+右子树的节点数;
1.如果root==NULL,则返回0;
2.否则递归调用它的左子树和右子树;
3.然后+1;
详细请看递归调用图:
int TreeSize(Tree* root)
{
return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;
}还是利用分治的思想;
1.分别算出左子树和右子树的深度;
2.然后比较二者的大小,大的返回;
3.不要忘了+1,因为根节点也算是一个深度。
int TreeHeight(Tree* root)
{
if (root == NULL) //为空则返回0
return 0;
int left = TreeHeight(root->left); //要用left记录下其返回值,防止多次重复调用,right同
int right = TreeHeight(root->right);
return left > right ? left + 1 : right + 1;
}二叉树第k层的节点数=左子树的第k-1层的节点数+右子树第k-1层的节点数。
因为二叉树没有第0层,是从第一层开始的,所以k==1时,返回1。
int TreeLevel(Tree* root, int k)
{
if (root == NULL) //为空则返回0
return 0;
if (k == 1)
return 1;
int left = TreeLevel(root->left, k - 1); //左子树第k-1层节点数
int right = TreeLevel(root->right, k - 1); //右子树第k-1层节点数
return left + right;
}前序遍历:
1.先访问根节点;
2.然后访问左节点;
3.最后访问右节点;
4.如果节点为空,则结束此次递归调用。
void PreOrder(Tree* root)
{
if (root == NULL)
return;
printf("%d ", root->data);
PreOrder(root->left); //访问左节点
PreOrder(root->right); //访问右节点
}中序遍历:
1.先访问左节点;
2.然后访问根节点;
3.最后访问右节点;
4.如果节点为空,则结束此次递归调用。
void InOrder(Tree* root)
{
if (root == NULL)
return;
InOrder(root->left);
printf("%d ", root->data);
InOrder(root->right);
}后序遍历:
1.先访问左节点;
2.然后访问右节点;
3.最后访问根节点;
4.如果节点为空,则结束此次递归调用。
void PostOrder(Tree* root)
{
if (root == NULL)
return;
PostOrder(root->left);
PostOrder(root->right);
printf("%d ", root->data);
}通过以上代码我们发现:
1.假设前序,中序,后序分别为1,2,3;
2.是哪个序遍历,就按照那个顺序访问根节点,左节点永远在右节点前面;
3.递归也是按照这个顺序。
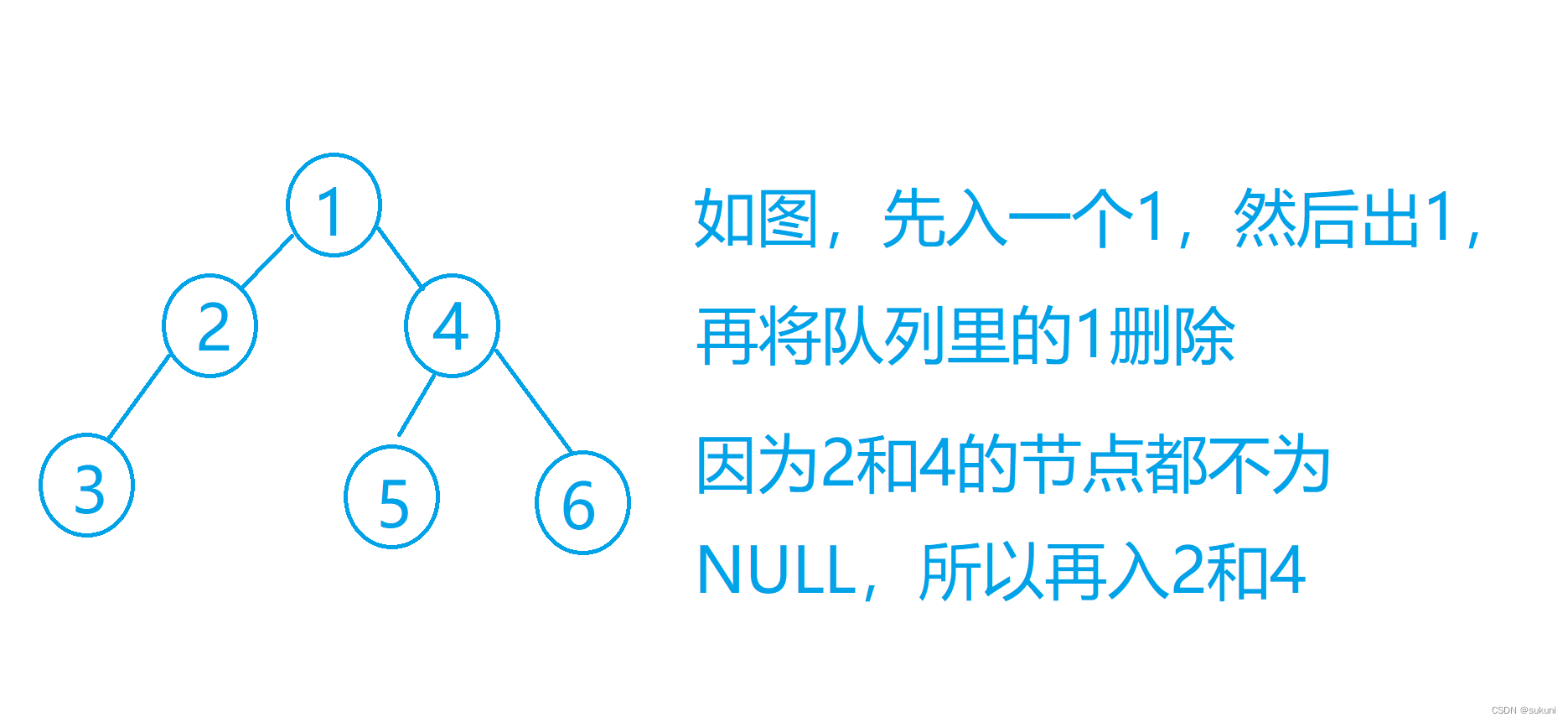
层序遍历就需要用到队列了。
1.先入一个节点进队列,此时队列不为空;
2。然后出一个节点,然后删除队列里的一个元素,如果左节点和右节点不为空的话,入它的左节点和右节点;
3.队列为空时跳出循环。
void LevelOrder(Tree* root)
{
//创建一个队列,并初始化
Queue q;
Queueinit(&q);
if (root)
Queuepush(&q, root);
while (!Queueempty(&q))
{
Tree* front = Queuefront(&q); //出一个数据
Queuepop(&q);
printf("%d ", front->data);
if (front->left)
Queuepush(&q,front->left); //入它的左节点
if (front->right)
Queuepush(&q, front->right); //入它的右节点
}
Queuedestroy(&q); //不要忘记销毁队列
}叶节点就是没有子节点的节点,我们可以分别记录下当前节点的左节点和右节点,如果都为空,那么叶节点的个数+1。
int BinaryTreeLeafSize(Tree* root)
{
Tree* left = root->left;
Tree* right = root->right;
if (left == NULL && right == NULL)
{
return 1;
}
else
{
BinaryTreeLeafSize(root->left);
BinaryTreeLeafSize(root->right);
}
}🐬🤖本篇文章到此就结束了,若有错误或是建议的话,欢迎小伙伴们指出;🕊️👻
😄😆希望小伙伴们能支持支持博主啊,你们的支持对我很重要哦;🥰🤩
😍😁谢谢你的阅读。😸😼

我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf