文章目录
一、网络的定义
网络的定义:网络是由网络连接设备通过传输介质将网络终端设备连接起来进行数据交换、资源共享的平台。
网络的概念:具有独立功能的计算机通过通信介质连接起来就形成了网络。
计算机网络相关知识:https://blog.csdn.net/weixin_43483442/article/details/107629665
二、图的计算机表示:邻接矩阵、三元组
最常见的表示图的基本结构是邻接矩阵和邻接表。采用邻接矩阵的方法来表示一个图,可以轻易判定任意两个顶点之间是否有边相连。图的矩阵表示的另一个好处就是使得我们可以使用矩阵分析的方法来研究图的许多性质。
表示稀疏的无权图的最常用方法是邻接表,对每个顶点i建立一个单链表。
三元组:可以容易地表示一般的加权有向图。Eg:1 2 3,表示顶点1到顶点2之间有一条权值为3的边.
1 2 3
1 4 2 //点1到点4之间有权值为2的边
2 4 3
在无向图的三元组表示中,每条边也会出现两次。
在一些网络分析软件,比如Pajek中,邻接表和三元组也是常用的格式,只是每条边只出现一次,从而使表示更为紧凑。



简单路径:各个顶点都不互相同的路径称为是简单的。
在技术网络中,有时会有意设计一些圈,以期通过边的冗余而实现网络的鲁棒性。
三、网络的连通性:路径、割集、连通性(强连通、弱联通)
强弱连通:如果每对顶点之间都至少存在一条路径,这个无向图就是连通的,否则不连通。
一个不连通图是由多个连通片组成的,连通片就是连通的几个节点+边。包含顶点数最多的连通片就成为最大连通片。
Menger定理:1、点形式:设顶点s和顶点t为图G中两个不相邻的顶点,则使顶点s和顶点t分别属于不同的连通片所需去除的顶点的最少数目等于连接顶点s和顶点t的独立的简单路径的最大数目。
2、边形式:设顶点s和顶点t为图G中两个不同的顶点,则使顶点s和顶点t分别属于不同的连通片所需去除的边的最少数目等于连接顶点s和顶点t的不相交的简单路径的最大数目。
两个顶点称为是不相邻的,是指两个顶点之间没有边直接相连。
连接顶点s和t的两条简单路径称为是独立的,是指这两条路径的公共顶点只有顶点s和t。
连接s和t的两条简单路径称为是不相交的,是指这两条路径没有经过一条相同的边(但可以有共同顶点)。
使得一对顶点分属于不同的连通片所需去除的一组顶点称为这对顶点的点割集,使得一堆顶点分属于不同的连通片所需去除的一组边称为这对顶点的边割集。包含顶点数或边数最少的割集称为极小割集。
四、连通
对于有向图中任意一对顶点u和v,都既存在一条从顶点u到顶点v的路径,也存在一条从v到u的,称为强连通。弱连通:把有向边改为无向边后,若图是连通的,则称为弱连通。
Prim:依次把顶点相连的最小的边加入,直到全部顶点都加入。
Kruskal:把权值最小的依次加入。如果形成圈就不要这个边,换下一条。
都是基于贪心算法。
五、二分图与匹配问题:完全匹配、稳定匹配


匈牙利算法:https://blog.csdn.net/dark_scope/article/details/8880547/
稳定匹配:师生双选案例(1)如果有学生想要换导师,那么没有教师愿意接受这名学生。
(2)如果有教师想要换学生,那么没有学生愿意跟随这位教师。
那么就称此师生分配方案是稳定的。
G-S算法定理
定理1: G-S算法在至多 N^2次迭代之后终止,且算法终止时所得到的集合是一个完全匹配。
定理2: G-S算法终止时所得到的集合Ω一定是一个稳定匹配。
定理3: G-S算法所有执行得到的都是对学生最满意、对教师最不理想的稳定匹配。
定理4 一个左右节点数相同的二分图存在完全匹配的充要条件是它不包含抑制集。
只要一个二分图中存在抑制集,那就不存在完全匹配。
一、复杂网络的连通性:有向网络的蝴蝶结结构(入部、出部、核)


强连通核未必一定就是蝴蝶结结构中节点最多的部分。
二、节点的度、平均度
无向网络中节点i的度ki定义为与节点直接相连的边的数目。网络中所有节点的度的平均值称为网络的平均度。网络节点的度和网络边数M之间的关系:2M=N。
=2M/N
在有向网络中,网络的平均出度=平均入度。-----对于系统中每个个体而言不一定成立的性质,却会在整个系统的层面上成立。

实际的大规模网络的一个特征就是稀疏性。
=2M/N=(N-1)密度=N密度
三、网络平均距离长度、直径

两个节点之间不存在路径即距离无限大,从而导致整个网络的平均路径长度也无限大。
于是引入了GE-简谐平均。

简谐平均越大,说明效率越高,说明平均路径长度越短。
网络中任意两个节点之间的距离的最大值称为网络的直径,记为D。在实际应用中,网络直径通常是指任意两个存在有限距离的节点之间的距离的最大值。
网络中距离为d的连通的节点对的数量占整个网络中连通的节点对的数量的比例,记为f(d)。
网络中距离不超过d的连通的节点对的数量占整个网络中连通的节点对数量的比例为g(d)。

四、聚类系数

一个网络的聚类系数C定义为网络中所有节点的聚类系数的平均值。
C的取值范围为0-1. C=1的时候,网络是全局耦合的,网络中任意两个节点都直接相连。
五、度分布


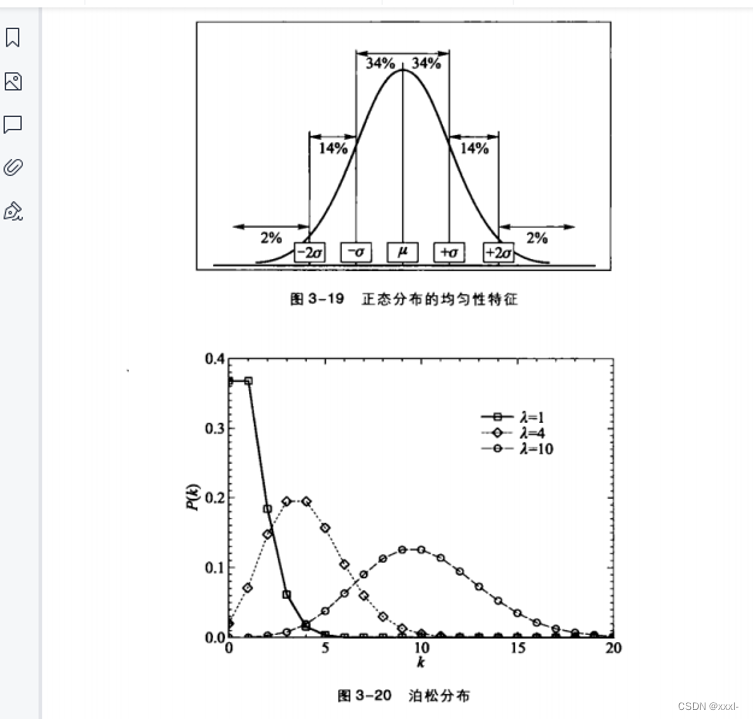
六、幂律分布
在一定的数学意义下,幂律分布是唯一一种具有无标度特性的长尾分布。

幂律分布的性质:https://blog.csdn.net/weixin_40614311/article/details/103450913

一、度相关性:联合概率分布、同配性、异配性


为了进一步刻画网络的拓扑结构,需要考虑包含更多结构信息的高阶拓扑特性。
因此:
联合概率分布:




余平均度表示,网络中随机选取的一个节点,这个节点的度为k邻居节点再被选取的概率。
在不改变节点度分布的情况下,可以使度大的节点倾向于和其它度大的节点连接。网络中的这个重要的结构特性,称之为节点之间的相关性(Correlation)。如果网络中的节点趋于和它近似的节点相连,就称该网络是同配的(Assortative);反之,就称该网络是异配的(Disassortative)。
网络同配性(或异配性)的程度可用同配系数(也称Pearson Coefficient----皮尔森系数)r来刻画。r>0表示整个网络呈现同配性结构,度大的节点倾向于和度大的节点相连;r<0表示整个网络呈现异配性;r=0表示网络结构不存在相关性。
二、社团结构与模块度:模块度、社团结构的检测算法

基于模块度的社团检测算法:
CNM算法:基于贪婪思想。


CNM和FN的区别就是:CNM中构建的是detaQ的矩阵,FN中的就是邻接矩阵。
模块度的局限性,比如有的公认不具有较强社团结构的网络也会有较大的q值,or公认具有明显社团结构的网络有很小的q值。Another:分辨率限制:模块度无法识别出规模充分小的社团。
一、重要性指标:度中心性、介数中心性、接近中心性、k-核与k-壳、特征向量中心性
度中心性:

以经过某个节点的最短路径的数目来刻画节点重要性的指标就称为介数中心性 Betweeness Centrality 简称介数BC。这个指数刻画了节点i对于网络中节点对之间沿着最短路径传输信息的控制能力。

接近中心性:

K-壳分解法:

实际网络可能出现:度大的节点既可能具有较大的ks值位于k-壳分解的核心内层,也可能具有较小的ks值而位于k-壳分解的外层。



特征向量中心性教学视频:
https://www.bilibili.com/video/BV1Cr4y1S7qF/?spm_id_from=333.337.search-card.all.click&vd_source=2949e61edef0cf5bdf117691a67dd6c9
二、节点相似性
基于节点相似性进行链路预测的一个基本假设就是如果两个节点之间的相似性越大,他们之间存在链接的可能性就越大。

一、 规则网络模型:网络结构、网络拓扑性质

要想构建和维护一个大规模的全耦合网络的成本是极其高昂的。全耦合网络作为实际网络模型的局限性:大型实际网络一般都是稀疏的,他们的边的数目一般至多是o(N)而不是o(N平方)。


基本拓扑性质:




二、ER随机图:网络构造算法、拓扑性质、网络演变
随机图:






因此,ER随机图也称为泊松随机图。


ER随机图的平均度是=p(N-1)=约等于pN



三、广义随机图(配置模型):构造算法、余平均度


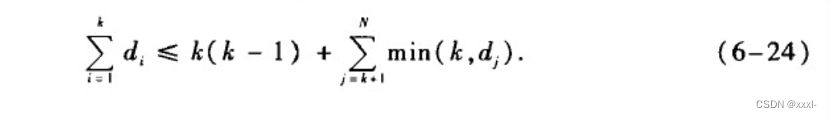



实际网络中节点的邻居节点的平均度往往大于网络节点的平均度。–你的朋友比你拥有更多的朋友。
网络节点的平均度只是把网络中每一个节点的度加起来再除以网络节点数,而在计算网络节点的邻居节点的平均度时,度越大的节点的度往往被重复统计的次数也越高,正是这种对度大节点的偏好使得邻居节点的平均度往往要大于节点的平均度。


一、小世界网络模型:WS小世界模型构造算法、NW小世界模型构造算法

在WS小世界模型中每个节点的度至少为K/2,而在ER随机图中对单个节点的度的最小值没有任何限制。
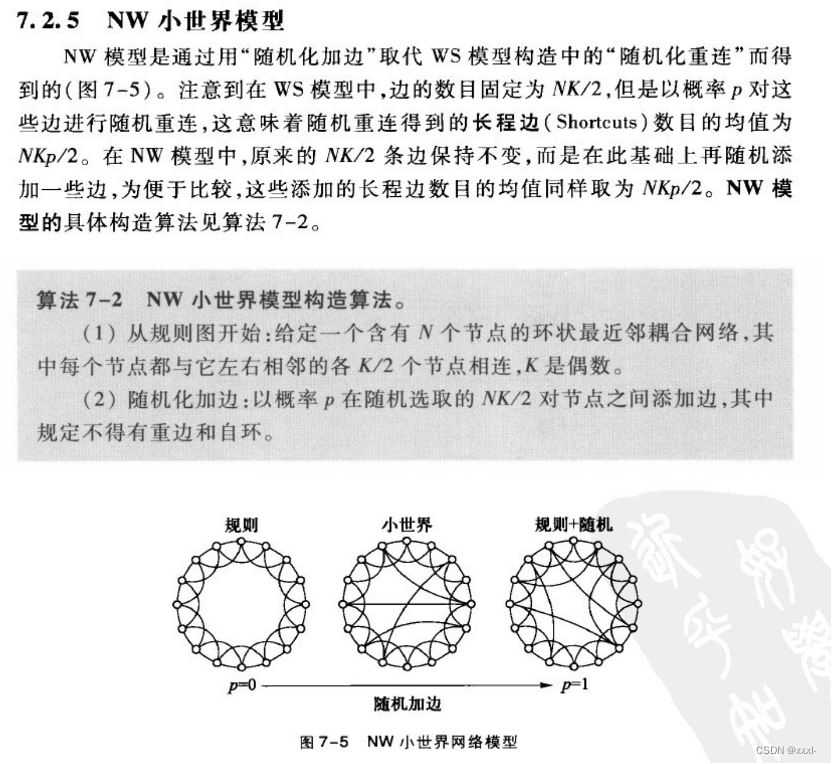


二、拓扑性质分析:聚类系数、平均路径长度和度分布


https://blog.csdn.net/weixin_42374938/article/details/120253526?ops_request_misc=&request_id=&biz_id=102&utm_term=WS小世界拓扑性质&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-120253526.142v62pc_search_tree,201v3control_2,213v1t3_control1&spm=1018.2226.3001.4449
三、二维Klernberg模型:构造算法




一、BA无标度网络:特性、构造算法、幂律度分析
ER随机图和WS小世界模型忽略了实际网络的两个重要特性—增长特性,即网络的规模是不断扩大的;优先连接,即新的节点更倾向于与那些具有较高连接度的hub节点连接。富者更富or马太效应。而在ER随机图中,两个节点之间是否有边相连是完全随机确定的,在WS小世界模型中,长程边的端点也是完全随机确定的。

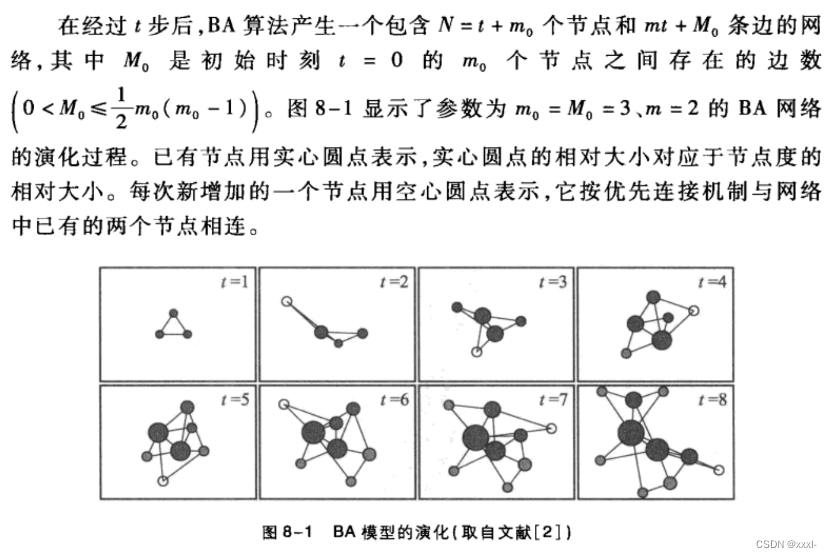
二、Price模型:构造算法、度分布分析

三、模型推广:适应度模型(构造算法)、局域世界演化模型(构造算法)


适应度模型具有以下特征:无标度特征、适者更富、赢者通吃。
一、经典的传染病模型:SI、SIR、SIS模型
在经典的传染病模型中,种群population内的N个个体的状态可分为如下几类:
1-易染状态S,Susceptible。一个个体在感染之前是处于易染状态的,即该个体有可能被邻居个体感染。
2-感染状态I,Infected。一个感染上某种病毒的个体就称为是处于感染状态,该个体还会以一定概率感染其邻居个体。
3-移除状态R,Removed Refractory or Recovered。也称为免疫状态或恢复状态。当一个个体经历过一个完整的感染周期后,该个体就不再被感染,因此就可以不再考虑该个体。
经典个体的一个基本假设是完全混合:一个个体在单位时间里与网络中任一其他个体接触的机会都是均等的。
SI模型:
https://www.bilibili.com/video/BV1PA411M7Zz/?spm_id_from=333.337.search-card.all.click&vd_source=2949e61edef0cf5bdf117691a67dd6c9
https://blog.csdn.net/qq_37730871/article/details/126532308
在现实世界中,感染个体一般不可能永远处于感染状态并永远传染别人。
因此以下两种更常见。
SIR模型:



SIS模型:

二、复杂网络的免疫策略:随机免疫、目标免疫、熟人免疫
标度网络的免疫方法:
(1)随机免疫:随机选择一些节点将其免疫,该方法的临界值会随着节点的增大而增大,成本较高
(2)目标节点免疫:选择一些高度连通的节点将其免疫,该方法的临界值远远小于随机免疫,效果很好
(3)熟人免疫:随机选择一些节点,然后将他们度最大的邻居免疫,该方法只需要用到局部信息,且效果比随机免疫效果好。
总结:效率由高到低:目标节点免疫>熟人免疫>随机免疫,熟人免疫相对于目标免疫而言只需要用到局部信息,不需要用到全局信息,随机免疫实现简单,但是效果很差。



一、博弈模型:囚徒困境、雪堆博弈、鹰鸽博弈、胆小鬼博弈、猎鹿博弈(收益矩阵、纳什均衡)
博弈模型:
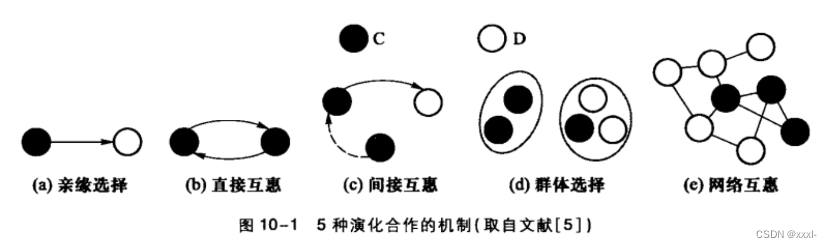
囚徒困境博弈:

无论对手采取哪种策略,选择背叛策略都是最佳的。因此理性的个体最终会处于相互背叛的状态–(D,D)是囚徒困境博弈的纳什均衡状态。但是此时的受益低于两人同时选择合作时的受益。
重复囚徒困境:
如果两个个体仅进行一轮囚徒困境博弈,个体会选择背叛策略。然而在现实生活中,两个个体之间经常进行重复的交互。此时个体会乐于帮助那些曾经帮助过自己的个体。
从各类重复困境中获胜的都是所有程序中最简单的规则—“针锋相对”Tit-for-tat-TFT,也称为“一报还一报or以牙还牙”。
TFT以合作开始,然后模仿对手上一步的策略。其之所以成功主要得益于:1-TFT是善良的,它不会首先背叛对手;2-TFT是可被激怒的,如果对手背叛自己,下一轮它也会做出报复性反应;3-TFT的报复是适当的,如果背叛它的对手知错能改,重新与TFT合作,TFT会原谅对手。 Eg:棘鱼受到大鱼威胁时,会组成探查小队试探,每游近几厘米,棘鱼会观察其他棘鱼是否照做,这个侦查过程就是分阶段的重复囚徒困境博弈。
与TFT相比,“两报还一报Tit-for-two-tat”只有对手连续两次背叛后才采取报复策略—因为对对手太过宽容而得分低于TFT。“对手背叛后永久报复”的完全不宽容的规则是所有善良规则中得分最低的。
如果两个TFT相互博弈,中间一次失误会导致合作与背叛行为交错发生。因此在噪声环境中,TFT因为不能纠正对手的失误而丧失合作优势。So更有力的规则提出: GTFT慷慨的TFT:考虑个体面对背叛行为时,仍以一定的概率保持合作。GTFT期望收益比TFT收益高。WSLS赢存输变Win-stay lost-shift:也叫巴甫洛夫规则。WSLS要求个体设一个心理阈值,如果一轮博弈的收入高于阈值,则下一轮将保持上一轮策略不变,反之改变。WSLS是一种确定性的纠错规则,而GTFT是一种随机纠错规则。所以WSLS比TFT和GTFT对待噪声干扰具有更好的鲁棒性。
雪堆博弈:Snowdrift game SG。最佳策略取决于对手,如果对手选择合作,个体的最佳策略是背叛,反之如果对手是背叛者,个体最好采取合作策略。因此不同于囚徒困境博弈,雪堆博弈中存在两个纯纳什均衡:(C,D)(D,C)。在存在多纳什均衡的情况下,个体如何抉择是一个难题,可以根据一些线索比如历史信息,进行选择均衡。If没有线索可利用,个体可以以概率1-r选择铲雪,以概率r选择待在车中,r=c/(2b-c)称为双方合作时的损益比cost-to-benefit,此时对对手来说选择合作或者背叛的期望收益是相同的

鹰鸽博弈-Hawk Dove game:

胆小鬼博弈-Chicken game:

猎鹿博弈Stag-hunting game SH:


X代表选择合作策略的个体的比例
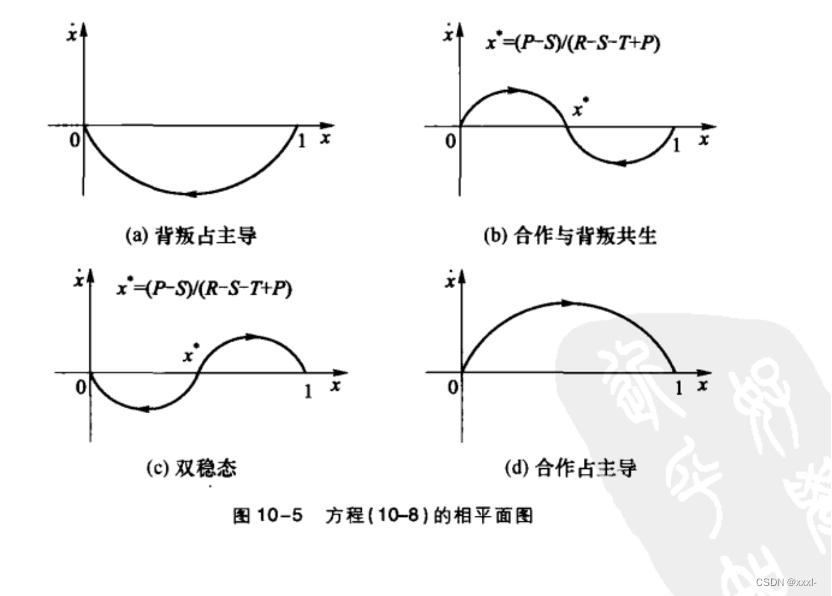
二、规则网络上的演化博弈
演化博弈是刻画群体决策形成和演化的一种基本范式,结合了传统博弈论与生物进化论。以参与群体为研究对象,通过分析群体策略在选择和突变作用下的演化过程,从而解释和预测个体在交互决策情境中的博弈行为。(从系统动态的角度考察个体决策到群体决策的形成机制)

规则网络上的雪崩博弈:

我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我在加密来self正在使用的第三方供应商的值时遇到问题。他们的指令如下:1)Converttheencryptionpasswordtoabytearray.2)Convertthevaluetobeencryptedtoabytearray.3)Theentirelengthofthearrayisinsertedasthefirstfourbytesontothefrontofthefirstblockoftheresultantbytearraybeforeencryption.4)EncryptthevalueusingAESwith:1.256-bitkeysize,2.25
我正在开发西洋跳棋实现,其中有许多易于测试的方法,但我不确定如何测试我的主要#play_game方法。我的大多数方法都可以很容易地确定输入和输出,因此也很容易测试,但这种方法是多方面的,实际上并没有容易辨别的输出。这是代码:defplay_gameputs@gui.introwhile(game_over?==false)message=nil@gui.render_board(@board)@gui.move_requestplayer_input=getscoordinates=UserInput.translate_move_request_to_coordinates(play
方法应返回-1,0或1分别表示“小于”、“等于”和“大于”。对于某些类型的可排序对象,通常将排序顺序基于多个属性。以下是可行的,但我认为它看起来很笨拙:classLeagueStatsattr_accessor:points,:goal_diffdefinitializepts,gd@points=pts@goal_diff=gdenddefothercompare_pts=pointsother.pointsreturncompare_ptsunlesscompare_pts==0goal_diffother.goal_diffendend尝试一下:[LeagueStats.new(
关闭。这个问题需要更多focused.它目前不接受答案。想改进这个问题吗?更新问题,使其只关注一个问题editingthispost.关闭8年前。Improvethisquestion我们有以下(以及更多)系统,我们将数据从一个应用推送/拉取到另一个:托管CRM(InsideSales.com)Asterisk电话系统(内部)横幅广告系统(openx,我们托管)潜在客户生成系统(自行开发)电子商务商店(spree,我们托管)工作板(本土)一些工作网站抓取+入站工作提要电子邮件传送系统(如Mailchimp,自主开发)事件管理系统(如eventbrite,自主开发)仪表板系统(大量图表和